
- 1全球首个真人级、 实时渲染数字人模型开源了!_实时数字人
- 2十月面经:真可惜!拿了小米的offer,字节却惨挂在三面
- 3构建应用程序的低代码思路_低代码的设计思路
- 42020 校招,我是如何拿到小米、京东、字节大厂前端offer
- 5Linux内核操作系统原理与概述(流程图)_linux原理与结构
- 6Oracle 20c 新特性:Online SecureFiles Defragmentation 在线的 LOB 碎片整理
- 7快速排序算法 ( 挖坑法 ) ------- C语言_快速排序挖坑法
- 8CCRC-CDO首席数据官:致力于将数据转化为黄金_13521730416
- 9Java基于SpringBoot+Vue的电影影城管理系统,附源码,文档_基于springboot+vue的影视推荐管理系统
- 10【送书活动】《客户成功的力量》——客户成功体系如何构建?请看这7步
软件部署-NEMO在LIinux系统上的安装教程_nemo搭建
赞
踩
NEMO(Nucleus for European Modelling of the Ocean)海洋模式是一个原始方程海洋环境模式,采用正交曲线坐标,Arkawa-C网格,垂直坐标采用z坐标或S坐标。其物理参数化方案和数值算法使得NEMO具备了支持更高的分辨率、支持更高的并行度、并行IO技术和单双向多层嵌套等特点,成为国际上用于海洋学研究、海洋季节性预测和气候研究的最新模型框架。
NEMO包括OPA(Ocean PArallel)、TAM(Tangent linear and adjoint models)、LIM(laneuveice Model)和TOP(Tracer in the Ocean Paradigm)等模块,被广泛应用于27个国家的多项相关科研计划中,是目前世界各国海洋业务化预报系统的主力军。
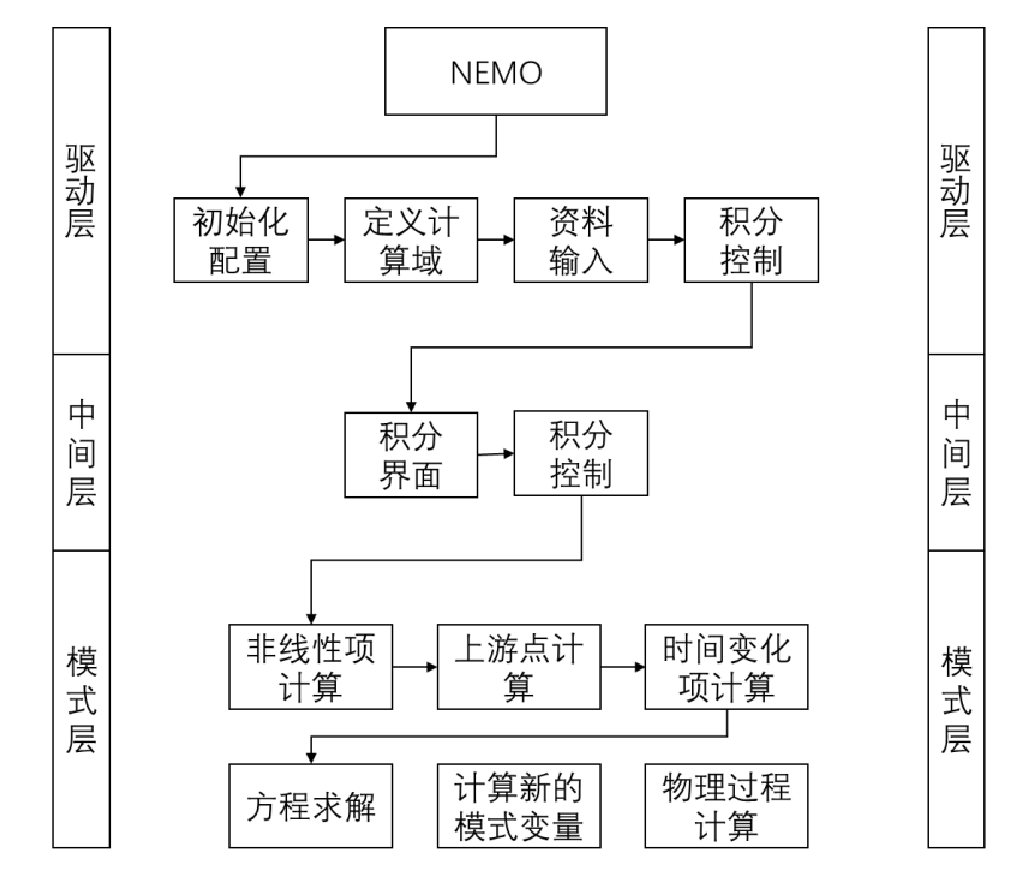
NEMO模式流程图如下:
01环境准备
-
编译器:Intel 2022.1.0
-
MPI:IntelMPI 2021.6.0
-
NEMO的编译依赖Netcdf,Netcdf的安装具体可参考:
-
onepai的安装具体可参考:
02NEMO编译安装
NEMO模式目录下的makenemo用于模式的配置编译,在执行makenemo时可以指定算例、编译选项配置文件等,编译选项配置文件存储在arch文件夹中。本次测试使用的编译选项配置文件为arch-linux_ifort.fcm,样例为 BENCH。
在 arch-linux_ifort.fcm 中需要根据环境修改如下选项。
-xHost是Intel编译器针对Intel处理器特定的编译优化选项,Intel编译器没有集成其他品牌处理器微架构相关信息。本实验环境处理器架构类似haswell,因此采用-march=haswell来帮助Intel编译器识别处理器的指令集特性。
本次测试使用如下命令完成编译,编译时间较长。
./makenemo -m 'linux_ifort' -n BENCH -a BENCH编译完成后在tests/BENCH/BLD/bin下生成nemo.exe可执行文件,在 test/BENCH/EXP00文件夹下执行nemo.exe可执行文件。
03算例介绍
NEMO模式模拟区域为全球区域,网格大小为 1440*1206,垂直层为75层。本次测试模拟50步,时间步长900s,采用MPI并行方式。
在测试之前需要根据需要修改配置文件。test/BENCH/EXP00下的namelist_cfg是nemo的输入文件,可以根据需要修改如下选项。
-
nn_it000为第一个时间步
-
nn_itend为最后一个时间步
-
nn_isize为X方向网格点数
-
nn_jsize为Y方向网格点数
-
nn_ksize为垂直方向层数
-
jpni和jpnj为X方向和Y方向的进程数,当设置为0时表示自动分配,但自动分配时总进程数不能超过255,若使用256进程运行时需要手动指定
- &namrun ! parameters of the run
- cn_exp = 'BENCH' ! experience name
- nn_it000 = 1 ! first time step
- nn_itend = 50 ! last time step
- /
- &namusr_def
- nn_isize = 1440 ! number of point in i-direction of global(local) domain if >0 (<0)
- nn_jsize = 1206 !! 1049 ! number of point in j-direction of global(local) domain
- if >0 (<0)
- nn_ksize = 75 ! total number of point in k-direction
- ln_Iperio = .true. ! i-periodicity
- ln_Jperio = .false. ! j-periodicity
- ln_NFold = .true. ! North pole folding
- cn_NFtype = 'T' ! Folding type: T or F
- /
- &nammpp ! Massively Parallel Processing
- ln_nnogather= .true. ! activate code to avoid mpi_allgather use at the northfold
- jpni = 0 ! jpni number of processors followingi
- jpnj = 0 ! jpnj number of processors followingj
- /

04运行方式
首先设置环境变量,加载oneapi环境。
source /PATH/oneapi/setvars.sh默认情况下,UCX尝试使用计算机上的所有可用设备,并根据性能特征(带宽、延迟、NUMA 位置等)选择最佳设备,这里使用UCX_NET_DEVICES指定通信时所使用的设备,用户可以根据自身机器配置灵活设置。
I_MPI_FABRICS指定MPI通信时的通信方法,这里在节点内使用share memory,节点间使用ofi通信。
I_MPI_SHM指定使用share memory通信时的通信方法。
- export UCX_NET_DEVICES=mlx5_0:1
- export I_MPI_FABRICS=shm:ofi
- export I_MPI_SHM=bdw_sse
之后使用mpirun启动作业,启动作业时无需指定输入配置文件。
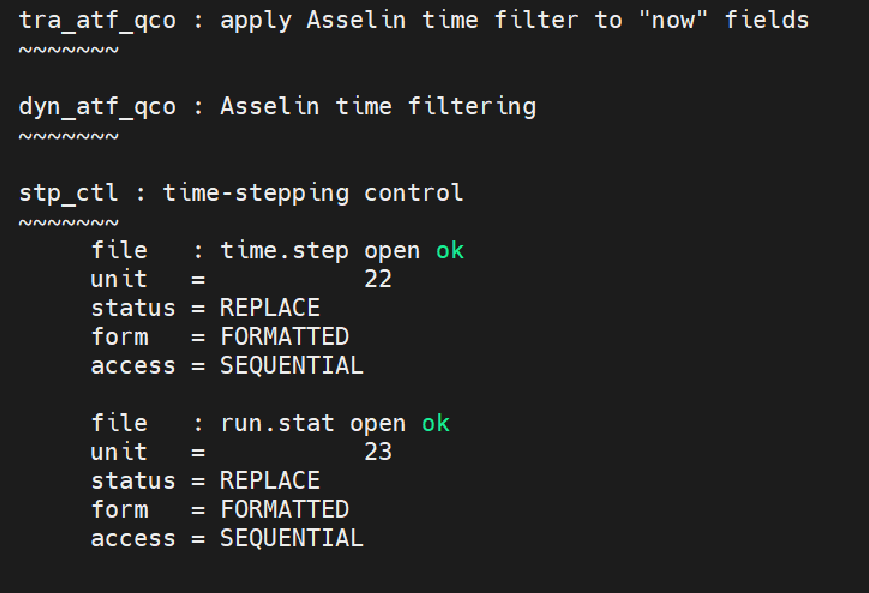
mpirun -n 128 ./nemo运行结束后,NEMO输出文件ocean.output会显示如下结果:
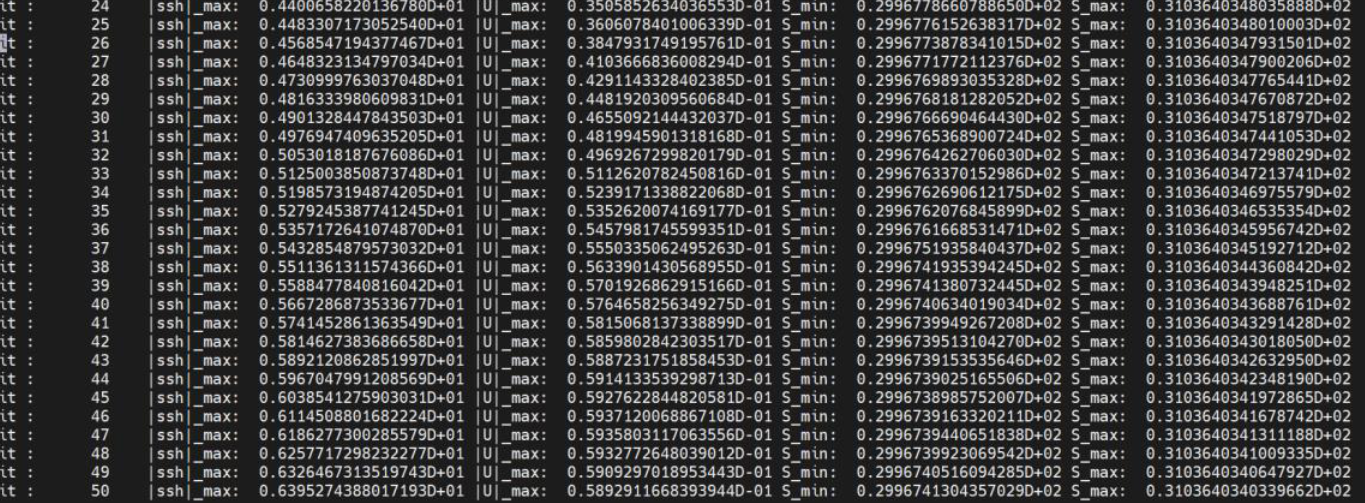
run.stat会显示每一步的结果概要。
- 机器学习 常见层 ...
赞
踩

