
- 1电脑自带录屏在哪?电脑录屏,4个详细方法
- 2Openai神作Dalle2理论和代码复现_dalle2复现代码
- 3第4节:Neo4j数据库实例_创建neo4j数据库实例
- 4Python-Django 静态文件的引入和配置(五)_static怎么导入vscode
- 5【网络】网络层IP报头的格式、网段划分、子网掩码、路由、数据链路层、MAC地址、ARP协议。_ip头部格式
- 6微信小程序电影推荐demo实战开发小结(附源码及思维导图) ... ..._微信小程序微电影详情代码
- 7【Java数据结构】Map和Set的使用_set
- 8SF Symbols 2在哪里下载 (SwiftUI 教程)_sf symbols 下载
- 9【开源社区建设】开源项目贡献者指南_fastbee 使用讲解
- 10textrank4zh提取文本关键词和内容摘要_tr4提取摘要
【LLM多模态】CogVLM图生文模型架构和训练流程_cogvlm2
赞
踩
note
- Cogvlm的亮点:
- 当前主流的浅层对齐方法不佳在于视觉和语言信息之间缺乏深度融合,而cogvlm在attention和FFN layers引入一个可训练的视觉专家模块,将图像特征与文本特征分别处理,并在每一层中使用新的QKV矩阵和MLP层。通过引入视觉专家模块弥补预训练语言模型和图像编码器之间的差距。
- 直接训语言模型会导致语言模型生成能力大幅度降低
- cogvlm保持原始语言模型的参数不变,虽然加入了视觉专家模块。
- cogvlm模型的文本encoder使用Vicuna-1.5-7B模型,视觉encoder使用EVA2-CLIP-E模型
- cogvlm2模型:支持 8K 文本长度、支持高达 1344 * 1344 的图像分辨率
文章目录
图生文:CogVLM-17B模型
多模态模型CogVLM-17B(开源):
Github:https://github.com/THUDM/CogVLM
Huggingface:https://huggingface.co/THUDM/CogVLM
魔搭社区:https://www.modelscope.cn/models/ZhipuAI/CogVLM
Paper:https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf
开源的对应模型:
| 模型名称 | 输入分辨率 | 介绍 | Huggingface model | SAT model |
|---|---|---|---|---|
| cogvlm-chat-v1.1 | 490 | 支持同时进行多轮聊天和视觉问答,支持自由的提示词。 | link | link |
| cogvlm-base-224 | 224 | 文本-图像预训练后的原始检查点。 | link | link |
| cogvlm-base-490 | 490 | 通过从 cogvlm-base-224 进行位置编码插值,将分辨率提升到490。 | link | link |
| cogvlm-grounding-generalist | 490 | 此检查点支持不同的视觉定位任务,例如REC,定位字幕等。 | link | link |
一、CogVLM模型
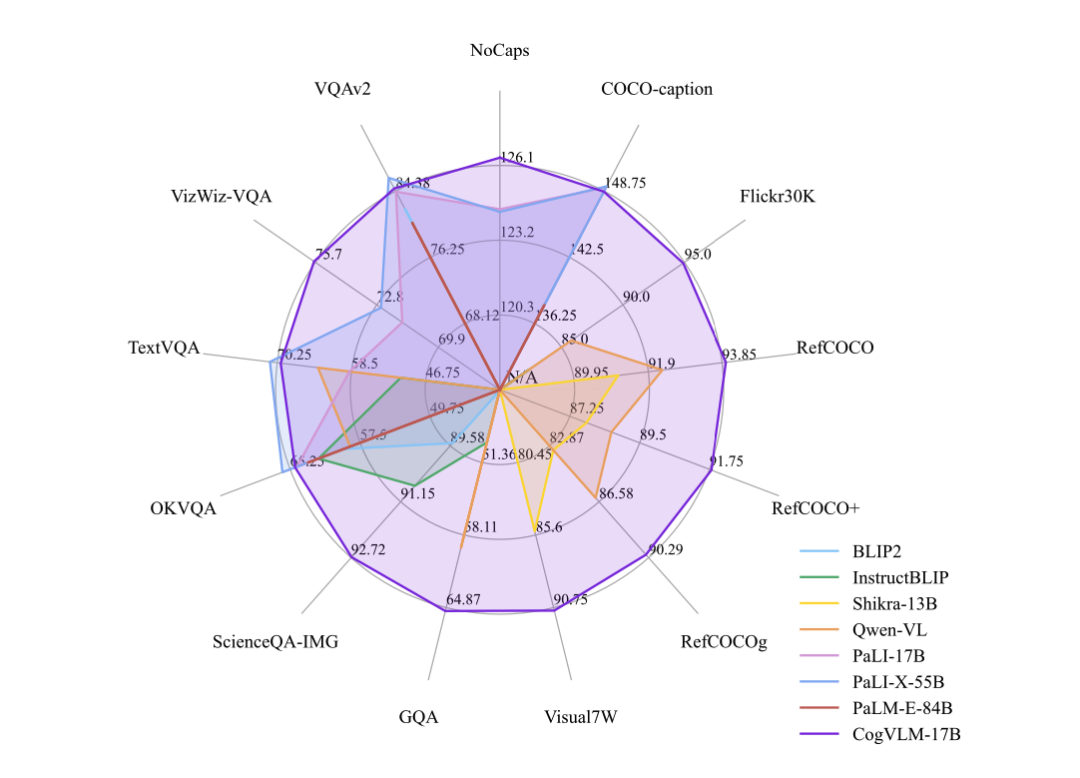
1. 模型效果和特点
CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。训练的 CogVLM-17B 是目前多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了state-of-the-art或者第二名的成绩。这些基准大致分为三类(共 14 个),包括图像字幕(Image Captioning)、视觉问答(Visual QA)、视觉定位(Visual Grounding)。
2. 训练数据:CogVLM-SFT-311K
CogVLM-SFT-311K:CogVLM SFT 中的双语视觉指令数据集
链接: CogVLM-SFT-311K
CogVLM-SFT-311K 是在训练 CogVLM v1.0 最初版本时使用的主要对齐语料库。此数据集的构建过程如下:
- 从开源的 MiniGPT-4 中选取了大约3500个高质量数据样本,称为 minigpt4-3500。
- 将 minigpt4-3500 与 Llava-Instruct-150K 整合,并通过语言模型翻译获得中文部分。
- 发现在 minigpt4-3500 和 Llava-instruct 的详细描述部分存在许多噪声。因此,我们纠正了这两部分的中文语料,并将纠正后的语料重新翻译成英语。
数据集信息
数据集共有三个文件夹,分别对应混合 minigpt4-3500 与llava混合的一部分数据集,llava 单论对话和多轮对话数据集。其布局如下:
.CogVLM-SFT-311K
├── llava_details-minigpt4_3500_formate
├── llava_instruction_multi_conversations_formate
└── llava_instruction_single_conversation_formate
- 1
- 2
- 3
- 4
在开源的数据中,数据集按照以下格式分布
.llava_details-minigpt4_3500_formate
├── images
│ └── 00000001.jpg
└── labels
└── 00000001.json
- 1
- 2
- 3
- 4
- 5
其中,images存储图像数据,而labels存储这张图像对应的描述或对话。
数据集数量
- llava_details-minigpt4_3500_formate 22464 张图片和描述
- llava_instruction_muti_conversations_formate 56673 张图片和多轮连续对话
- llava_instruction_single_conversation_formate 76634 张图片和单轮对话
数据集格式
图像描述 Caption 格式:
{
"captions": [
{
"role": "caption",
"content": "这张照片展示了一男一女,他们都穿着红嘿色衣服,坐在桌子旁,在参加活动时面带微笑。这对情侣正在一起摆姿势,背景中还有其他人。在整个场景中可以看到另外几个人,一些人坐在附近的桌子旁,另一些人坐得离这对夫妇更近。各种餐桌设置,如酒杯和杯子,被放置在桌子上。排在最前面的男子打着领带。"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
图像对话 Json 格式:
{
"conversations": [
{
"role": "user",
"content": "在尝试保持这个浴室有序时可能会遇到哪些挑战?",
},
{
"role": "assistant",
"content": "在尝试保持这空间和各种物品的存在,例如杯子和手机占用了可用的空间。在图像中,浴室柜台上只有一个水槽可用,这导致多个用户可能必须共享空间放置自己的物品。这可能导致杂乱和混乱外的储物解决方案,如架子、橱柜或墙壁挂架,以保持浴室有序并最小化柜台上的杂乱。"
},
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3. 处理的任务
这些任务主要是基于图像理解和语言生成的任务:
- 图像字幕任务(Image Captioning):根据给定的图片生成描述图片内容的自然语言句子。数据集包括COCO、Flickr30K等,这些数据集包含了数十万张图片,每张图片都有人工生成的多个描述。
- 视觉问答任务(Visual Question Answering, VQA):根据给定的图片和关于图片内容的问题,生成回答问题的自然语言文本。数据集包括VQAv2、OKVQA等,这些数据集包含了数百万个图像-问题-答案三元组。
- 视觉定位任务(Visual Grounding):确定文本中提到的目标和图像中的具体位置区域之间的对应关系。数据集包括Visual7W、RefCOCO系列等。例如,模型需要从给定的图像中定位出文本提到的对象。
- 图像字幕任务(Grounded Captioning):生成图像的描述句子,其中每个名词短语的对应对象在图像中用边界框标注。数据集包括Flickr30K Entities。
- 定位描述生成任务(Referring Expression Generation, REG):为图像中的每个边界框生成描述其内容的文本表达。数据集包括VisualGenome。
- 定位描述理解任务(Referring Expression Comprehension, REC):根据文本描述的内容在图像中定位出对应区域。数据集包括RefCOCO系列。
这些任务在图像-语言建模的下游应用中扮演重要角色,需要模型理解深层的视觉语义信息。其中,视觉定位任务比较独特,需要确保文本描述与图像区域之间的对齐匹配。
二、模型架构
1. 模型架构
思想:视觉优先
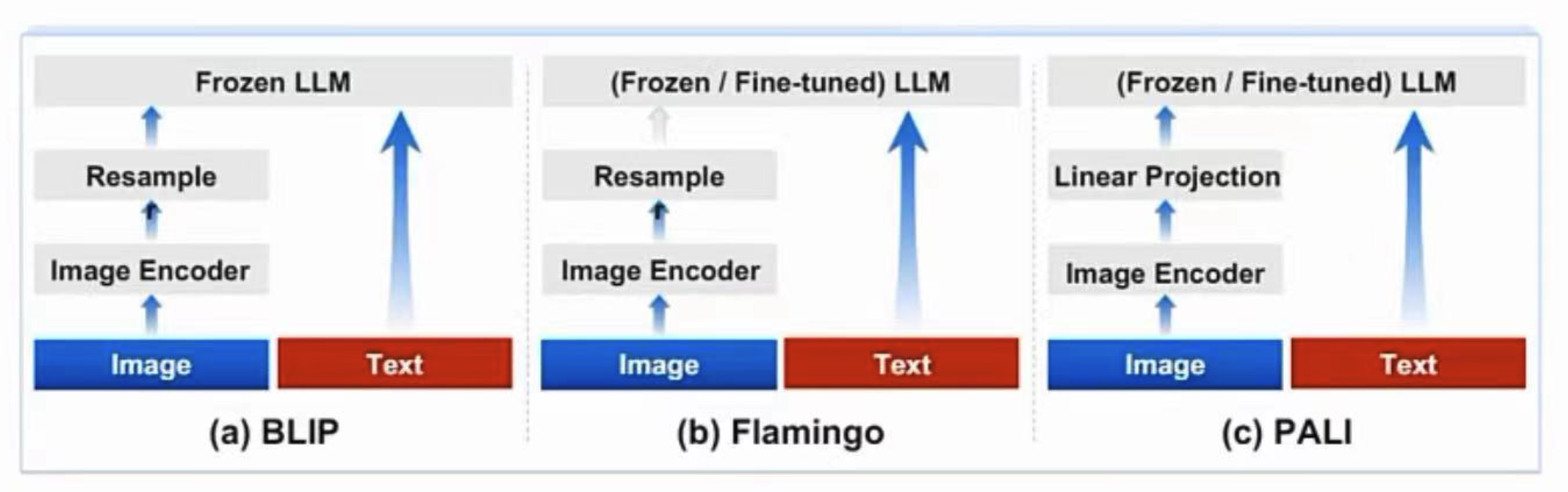
之前的多模态模型:通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的“附庸”,效果自然有限。
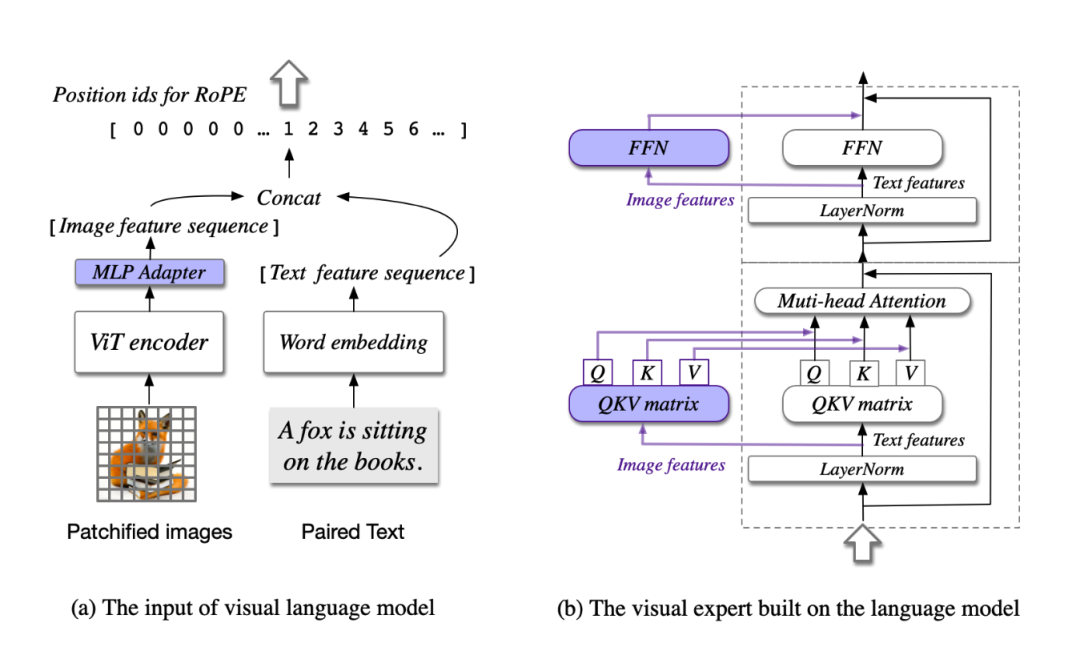
Cogvlm模型共包含四个基本组件:ViT 编码器,MLP 适配器,预训练大语言模型(GPT-style)和视觉专家模块。
- ViT编码器:在 CogVLM-17B 中,采用预训练的 EVA2-CLIP-E。也就是上图将图片进入vit encoder编码。在CogVLM-17B中,移除了ViT编码器的最后一层,因为该层专注于整合[CLS]特征以用于对比学习。
- MLP 适配器:MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同的空间。注:所有的图像特征在语言模型中共享相同的position id。
- 预训练大语言模型:CogVLM 的模型设计与任何现有的 GPT-style的预训练大语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7B-v1.5 进行进一步训练;也选择了 GLM 系列模型和 Llama 系列模型做了相应的训练。
- 视觉专家模块:在每层添加一个视觉专家模块,以实现深度的视觉 - 语言特征对齐。在每个transformer层中,图像特征使用与文本特征不同的QKV矩阵和MLP层(都是可训练的)。
class CogVLMModel(LLaMAModel): def __init__(self, args, transformer=None, parallel_output=True, **kwargs): super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kwargs) self.image_length = args.image_length self.add_mixin("eva", ImageMixin(args)) self.del_mixin("mlp") self.add_mixin("mlp", LlamaVisionExpertFCMixin(args.hidden_size, args.inner_hidden_size, args.num_layers, 32)) self.del_mixin("rotary") self.add_mixin("rotary", LlamaVisionExpertAttnMixin(args.hidden_size, args.num_attention_heads, args.num_layers, 32)) @classmethod def add_model_specific_args(cls, parser): group = parser.add_argument_group('CogVLM', 'CogVLM Configurations') group.add_argument('--image_length', type=int, default=256) group.add_argument('--eva_args', type=json.loads, default={}) return super().add_model_specific_args(parser) def forward(self, input_ids, vision_expert_mask, image_embed_mask, **kwargs): if input_ids.shape[1] > 1: return super().forward(input_ids=input_ids, vision_expert_mask=vision_expert_mask, image_embed_mask=image_embed_mask, **kwargs) return super().forward(input_ids=input_ids, **kwargs) class FineTuneTrainCogVLMModel(CogVLMModel): def __init__(self, args, transformer=None, parallel_output=True, **kw_args): super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kw_args) self.args = args # If you want to use model parallel with a mp_size=1 checkpoint, and meanwhile you also want to use lora, # you have to add_mixin after loading model checkpoint. @classmethod def add_model_specific_args(cls, parser): group = parser.add_argument_group('CogVLM-finetune', 'CogVLM finetune Configurations') group.add_argument('--pre_seq_len', type=int, default=8) group.add_argument('--lora_rank', type=int, default=10) group.add_argument('--use_ptuning', action="store_true") group.add_argument('--use_lora', action="store_true") group.add_argument('--use_qlora', action="store_true") group.add_argument('--layer_range', nargs='+', type=int, default=None) return super().add_model_specific_args(parser)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2. 训练方式
- 模型在15亿张图文对上预训练了4096个A100*days,并在构造的视觉定位(visual grounding)数据集上进行二阶段预训练。
- 在对齐阶段,CogVLM使用了各类公开的问答对和私有数据集进行监督微调,使得模型能回答各种不同类型的提问。
(1)预训练阶段
训练数据:图像文本对
- 在CogVLM的预训练阶段,它使用了公开可用的图像文本对进行训练,包括LAION-2B和COYO-700M。在筛选过程中,移除了损坏的URL、含有不适当内容的图像、带有噪声字幕的图像、具有政治偏见的图像,以及长宽比大于6或小于1/6的图像。经过筛选后,大约还剩下15亿个图像文本对用于预训练。
- 视觉定位数据集:作者还构建了一个包含4000万个图像的视觉定位数据集。在这个数据集中,每张图像的名词都与边界框相关联,以指示其在图像中的位置。构建过程遵循了Peng等人的方法,使用
spaCy提取名词,使用GLIPv2预测边界框。这些图像文本对是从LAION-400M的子集LAION-115M中抽取的,LAION-115M是由Li等人进行了筛选的。筛选后,保留了4000万张图像的子集,以确保超过75%的图像至少包含两个边界框。
预训练超参数:

1)预训练第一阶段:图像描述损失函数
在预训练的第一阶段中,模型训练的是图像描述损失函数(image captioning loss),即对文本部分进行下一个标记的预测。预训练的第一阶段使用了上述提及的15亿个图像文本对,共进行了12万次迭代,批量大小为8192。
2)预训练第二阶段:图像描述+REC任务
预训练的第二阶段涉及图像描述(image captioning)和指代表达理解(REC)任务。REC任务是根据物体的文本描述来预测图像中的边界框位置。这个任务以VQA的形式进行训练,即"问题:物体在哪里?“和"答案:[[x0,y0,x1,y1]]”。其中,x和y坐标的取值范围从000到999,表示在图像中的归一化位置。在答案的部分,只考虑了下一个标记的预测损失。
预训练的第二阶段同时涵盖了图像描述和REC任务,进行了6万次迭代,批量大小为1024。在最后的3万次迭代中,将输入分辨率从224×224改变为490×490(分辨率提升,增加图片的大小和细节,提供模型对细节的捕捉能力、增强模型的泛化能力,适应各种尺寸的输入图像等)。整个预训练过程中可训练参数总数为65亿,预训练过程消耗了约4096个A100×天。
(2)SFT有监督微调
数据:可以参考1.2的 CogVLM-SFT-311K数据介绍。
在SFT期间:除VIT(Vision Transformer)编码器外,所有的参数都是可以训练的。
sft训练的超参数设置:

3. 视觉专家模块
(1)工作模式
在每一层中,视觉专家模块由两部分组成:一个QKV矩阵和一个MLP。这里的QKV代表“查询-键-数值”,是用于注意力计算的重要矩阵。其工作模式:
- 首先,输入的隐藏状态被分成图像隐藏状态(XI)和文本隐藏状态(XT)。
- 接着,利用QKV矩阵,对图像和文本的隐藏状态进行相应的注意力计算。这一步可以理解为模型决定在处理时应该关注图像和文本中的哪些部分。
- 计算得到的注意力权重会影响到后续的处理过程,确保模型在处理过程中充分结合了图像和文本的信息。
- 在FFN(FeedForward Network)层中,视觉专家模块也会进行类似的处理,保证了在深度处理过程中图像和文本特征的融合。
(2)相关步骤:

- 首先定义:输入的input hidden states为
X
∈
R
B
×
H
×
(
L
I
+
L
T
)
×
D
X \in \mathbb{R}^{B \times H \times\left(L_I+L_T\right) \times D}
X∈RB×H×(LI+LT)×D,其中:
- B是
batch_size -
L
I
L_I
LI和
L
T
L_T
LT分别是图片和文本的
sequence_len - H是多头注意力的头数
- D是hidden size。
- B是
- 这里视觉专家的注意力表示形式为:
Attention
(
X
,
W
I
,
W
T
)
=
softmax
(
Tril
(
Q
K
T
)
D
)
V
\operatorname{Attention}\left(X, W_I, W_T\right)=\operatorname{softmax}\left(\frac{\operatorname{Tril}\left(Q K^T\right)}{\sqrt{D}}\right) V
Attention(X,WI,WT)=softmax(D
Tril(QKT))V
- 其中这里的 W I W_I WI、 W T W_T WT分别是视觉专家、original language model的QKV矩阵
- Tril ( ) \operatorname{Tril}() Tril()是取矩阵的下三角部分(自注意力机制常用的掩码操作)。
- Q = concat ( X I W I Q , X T W T Q ) Q=\operatorname{concat}\left(X_I W_I^Q, X_T W_T^Q\right) Q=concat(XIWIQ,XTWTQ)
- K = concat ( X I W I K , X T W T K ) K=\operatorname{concat}\left(X_I W_I^K, X_T W_T^K\right) K=concat(XIWIK,XTWTK)
- V = concat ( X I W I V , X T W T V ) V=\operatorname{concat}\left(X_I W_I^V, X_T W_T^V\right) V=concat(XIWIV,XTWTV)
- 最后进行拼接操作: FFN ( X ) = concat ( FFN I ( X I ) , FFN T ( X T ) ) \operatorname{FFN}(X)=\operatorname{concat}\left(\operatorname{FFN}_I\left(X_I\right), \operatorname{FFN}_T\left(X_T\right)\right) FFN(X)=concat(FFNI(XI),FFNT(XT))
- 特点:视觉专家模块在每个transformer层都对图像特征进行专门处理,使得模型更好理解和融合视觉信息。
4. 图片处理模块
from torchvision import transforms from torchvision.transforms.functional import InterpolationMode import torch class BlipImageEvalProcessor: def __init__(self, image_size=384, mean=None, std=None): super().__init__() if mean is None: mean = (0.48145466, 0.4578275, 0.40821073) if std is None: std = (0.26862954, 0.26130258, 0.27577711) self.normalize = transforms.Normalize(mean, std) self.transform = transforms.Compose( [ transforms.Resize( # 将图片大小调整,使用双三次插值 (image_size, image_size), interpolation=InterpolationMode.BICUBIC ), transforms.ToTensor(), self.normalize, ] ) def __call__(self, item): return self.transform(item) from functools import partial def blip2_image_processor_func_with_inputs(image_processor, image): return {'image': image_processor(image).unsqueeze(0), 'input_ids': torch.zeros(1, 1, dtype=torch.long), 'position_ids': None, 'attention_mask': torch.ones(1, 1, dtype=torch.long)} def get_image_processor(image_size): return partial(blip2_image_processor_func_with_inputs, BlipImageEvalProcessor(image_size))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
函数 get_image_processor 的返回部分是:
return partial(blip2_image_processor_func_with_inputs, BlipImageEvalProcessor(image_size))
- 1
这行代码使用 Python 的 functools.partial 函数来创建一个新的偏函数。partial 的作用是“冻结”一个函数的某些参数,从而返回一个新的函数,这个新函数在调用时会忽略被冻结的参数。在这个例子中,partial 被用来创建一个新的函数,这个新函数将 BlipImageEvalProcessor 的 image_size 参数固定,并且只接受一个参数 image。
具体来说:
blip2_image_processor_func_with_inputs是一个函数,它需要两个参数:image_processor和image。BlipImageEvalProcessor(image_size)创建了一个图像处理器实例,该实例已经被初始化为特定的image_size。partial将BlipImageEvalProcessor(image_size)作为第一个参数传递给blip2_image_processor_func_with_inputs,这样image_processor参数就被固定了。
因此,当 get_image_processor 被调用时,它返回一个新的函数,这个新函数接受一个图像作为输入,然后使用 BlipImageEvalProcessor 对图像进行处理,最后通过 blip2_image_processor_func_with_inputs 函数生成所需的字典输出。这种设计模式允许你创建一个可重用的图像处理流程,可以轻松地应用于不同的图像数据,而不需要每次调用时都重新指定图像处理器的配置。
三、Cogvlm模型训练中的数据增强
当面对特定场景(如路牌识别)且可用的图片数据集较小时,微调CogVLM前可以做的:
-
数据增强(Data Augmentation):
- 对现有的图像数据应用各种变换,如旋转、缩放、裁剪、颜色调整等,以生成更多的训练样本。
- 使用图像合成技术生成新的图像样本,例如,通过将路牌元素合成到不同背景中来增加数据多样性。
-
使用预训练任务:利用预训练阶段的数据集,这些数据集可能包含与路牌识别相关的图像,即使它们不是专门为路牌识别而设计的。
-
模型正则化:应用正则化技术,如Dropout或权重衰减,以防止模型在有限数据上过拟合。
四、Ablation Study消融实验
一些消融实验发现:
-
图像自监督损失没有帮助
-
图像序列中使用下三角注意力>全注意力(有点反直觉)
-
不同视觉编码器差异较小

-
Model structure and tuned parameters(模型结构和调整后的参数) :作者研究了仅调整MLP Adapter层或调整所有LLM参数和Adapter而不添加VE的有效性,以及修改VE架构以在每个第四个LLM层添加完整VE或仅在所有层中添加配备了FFN的VE。结果显示,仅微调adapted layer(如BLIP2模型)可能导致较差的浅层对齐效果。
-
Initialization Method(初始化方法) :作者研究了从LLM初始化VE权重的有效性。结果表明,这种方法略微降低了性能,这表明了这种方法的积极影响。
-
Visual Attention Mask(视觉注意力掩码) :作者在视觉标记上使用因果掩码(causal mask)会产生比full mask更好的结果。作者假设这种现象的可能解释是因果掩码更好地适应了LLM的内在结构。
-
Image SSL Loss(图像自我监督损失) :作者还研究了图像特征上的自我监督学习损失,其中每个视觉特征预测下一个位置的CLIP特征以进行视觉自我监督。与观察到的来自PaLI-X的观察一致,我们发现它对下游任务没有改善,尽管我们在早期实验证明了在小模型中确实有所改善。
-
EMA(指数移动平均) :作者在预训练期间使用了EMA,通常在各种任务中带来了改善。
五、评测集上的cogvlm效果
cogvlm用到的一些评测集如下:

六、CogVLM2模型
代码仓库:
Github:https://github.com/THUDM/CogVLM2
模型下载:
Huggingface:huggingface.co/THUDM
魔搭社区:modelscope.cn/models/ZhipuAI
始智社区:wisemodel.cn/models/ZhipuAI
Demo体验:
https://modelscope.cn/studios/ZhipuAI/Cogvlm2-llama3-chinese-chat-Demo/summary
CogVLM2 技术文档:
https://zhipu-ai.feishu.cn/wiki/OQJ9wk5dYiqk93kp3SKcBGDPnGf
1. 模型介绍
如何桥接视觉和语言特征:
- 很多主流模型使用Q-former
- 有损压缩:类似VAE
- 位置信息很难保留
- 泛化性差:不同大小图片同样query长度?
- cogvlm2使用MLP+Downsample
- 无损压缩:9600token->2400 token
- 位置信息完全保留
- 所有benchmark分数不下降

特点:
- 50亿参数的视觉编码器,在LLM中整合一个70亿参数的视觉专家模块,增强视觉理解能力
- 尽管CogVLM2的总参数量为190亿,但得益于精心设计的多专家模块结构,每次进行推理时,实际激活的参数量仅约120亿
- CogVLM2支持高达1344分辨率的图像输入
- 视觉编码器之前引入一个专门的降采样模块,降低输入到语言模型中的序列长度、提升推理速度
2. 模型效果
benchmark:TextVQA、DocVQA、ChartQA、OCRbench、MMMU、MMVet、MMBench等
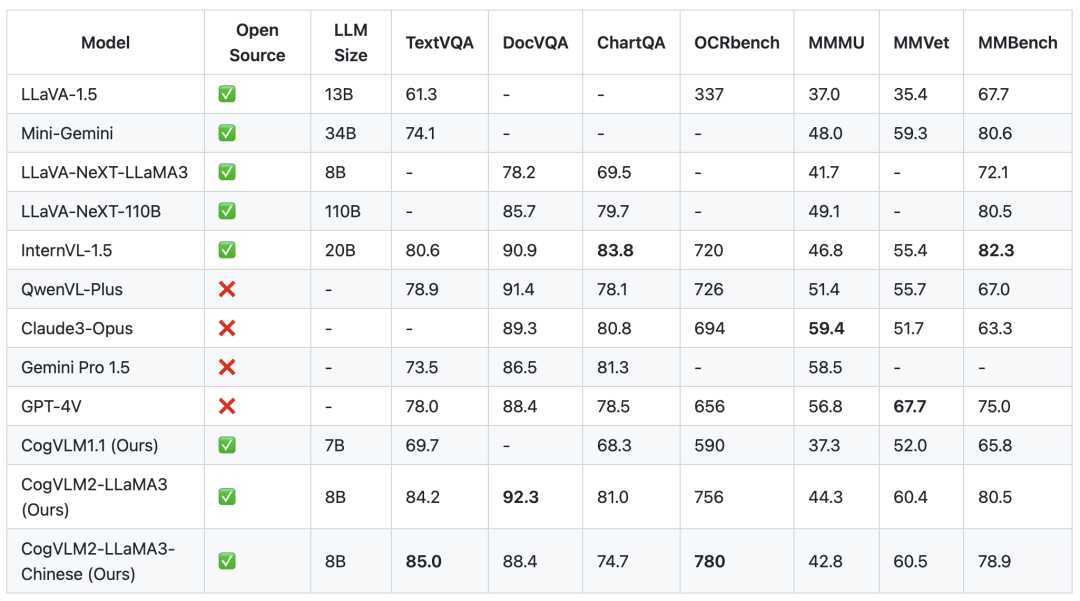
- TextVQA 专注于基于图像中的文本进行视觉推理。这个数据集要求模型能够读取并推理图像中的文本,以便回答与这些图像相关的问题。
- DocVQA 是一个用于视觉问答(VQA)的数据集,专注于文档图像(包括了各种类型的文档,如报告、表格、说明书等)。
- ChartQA 是一个用于图表问答的数据集,主要特点是它关注于复杂推理问题,这些问题通常涉及逻辑和算术操作,并且常常涉及图表的视觉特征。
- OCRbench 是一个用于评估多模态大模型在光学字符识别(OCR)能力方面的基准测试数据集
- MMMU是一个用于评估多模态模型在大规模跨学科任务上表现的新基准。它旨在挑战模型执行类似于专家面对的任务,特别是在需要大学水平的学科知识和深思熟虑的推理能力方面。对于该基准,较大的语言基座模型将具有较高的性能。
- MMVet是一个用于评估模型在识别、OCR、知识、语言生成、空间感知和数学计算等方面能力的基准数据集。
- MMBench相比其他评测,具有全面且具有挑战性的问题设计,以及对模型预测的更稳健的评估方式。
3. 推理and微调资源
- 整个模型仅 19B,全量推理(BF16/PF16)需要 42GB 显存,Int4 量化版本,仅需要 16GB 显存
- 如果冻结视觉部分,BF16 Lora 微调则仅需 57GB 显存;如果同时对视觉部分进行 BF16 Lora 微调,则至少需要80GB 显存。

七、GLM4V
GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
GLM-4V-9B模型权重:https://huggingface.co/THUDM/glm-4v-9b
GLM-4V-9B 是一个多模态语言模型,具备视觉理解能力,其相关经典任务的评测结果如下:
| MMBench-EN-Test | MMBench-CN-Test | SEEDBench_IMG | MMStar | MMMU | MME | HallusionBench | AI2D | OCRBench | |
|---|---|---|---|---|---|---|---|---|---|
| gpt-4o-2024-05-13 | 83.4 | 82.1 | 77.1 | 63.9 | 69.2 | 2310.3 | 55.0 | 84.6 | 736 |
| gpt-4-turbo-2024-04-09 | 81.0 | 80.2 | 73.0 | 56.0 | 61.7 | 2070.2 | 43.9 | 78.6 | 656 |
| gpt-4-1106-preview | 77.0 | 74.4 | 72.3 | 49.7 | 53.8 | 1771.5 | 46.5 | 75.9 | 516 |
| InternVL-Chat-V1.5 | 82.3 | 80.7 | 75.2 | 57.1 | 46.8 | 2189.6 | 47.4 | 80.6 | 720 |
| LLaVA-Next-Yi-34B | 81.1 | 79.0 | 75.7 | 51.6 | 48.8 | 2050.2 | 34.8 | 78.9 | 574 |
| Step-1V | 80.7 | 79.9 | 70.3 | 50.0 | 49.9 | 2206.4 | 48.4 | 79.2 | 625 |
| MiniCPM-Llama3-V2.5 | 77.6 | 73.8 | 72.3 | 51.8 | 45.8 | 2024.6 | 42.4 | 78.4 | 725 |
| Qwen-VL-Max | 77.6 | 75.7 | 72.7 | 49.5 | 52.0 | 2281.7 | 41.2 | 75.7 | 684 |
| Gemini 1.0 Pro | 73.6 | 74.3 | 70.7 | 38.6 | 49.0 | 2148.9 | 45.7 | 72.9 | 680 |
| Claude 3 Opus | 63.3 | 59.2 | 64.0 | 45.7 | 54.9 | 1586.8 | 37.8 | 70.6 | 694 |
| GLM-4V-9B | 81.1 | 79.4 | 76.8 | 58.7 | 47.2 | 2163.8 | 46.6 | 81.1 | 786 |
快速使用:
import torch from PIL import Image from transformers import AutoModelForCausalLM, AutoTokenizer device = "cuda" tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True) query = '描述这张图片' image = Image.open("your image").convert('RGB') inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}], add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True) # chat mode inputs = inputs.to(device) model = AutoModelForCausalLM.from_pretrained( "THUDM/glm-4v-9b", torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True ).to(device).eval() gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1} with torch.no_grad(): outputs = model.generate(**inputs, **gen_kwargs) outputs = outputs[:, inputs['input_ids'].shape[1]:] print(tokenizer.decode(outputs[0]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
八、相关问题
1. 图片的位置编码
在图片序列中引入2d RoPE位置编码

2. 是否有必要使用多个视觉编码器

Reference
[1] CogVLM:深度融合引领视觉语言模型革新,多领域性能创新高
[2] 多模态融合新方向!21篇2024年最新顶会论文汇总!
[3] https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf
[4] minigpt-4模型论文:https://arxiv.org/pdf/2304.10592.pdf
[5] https://huggingface.co/datasets/THUDM/CogVLM-SFT-311K
[6] https://huggingface.co/THUDM/cogvlm-chat-hf/
[7] https://huggingface.co/THUDM/CogVLM/tree/main
[8] https://huggingface.co/THUDM/cogvlm-base-490-hf/blob/main/modeling_cogvlm.py
[9] CogVLM大模推理代码详细解读

