
- 1嗨,Chrome和火狐,有第三者插足!_ortc开源吗
- 2ACL2022 | 关系抽取和NER等论文分类整理_few-shot class-incremental learning for named enti
- 3陪诊小程序成品|陪诊系统功能|陪诊小程序研发功能和流程
- 4Android Studio中配置aliyun maven库_android studio maven配置
- 5把本地文件 formfile 拷贝到本地文件 tofile 的程序
- 6Pytorch(二) —— 激活函数、损失函数及其梯度_pytorch 激活函数的梯度
- 7Tensorflow训练mnist数据集损失函数loss出现Nan_minist 训练结果lost 大
- 8Android SDK下载安装及配置教程_andorid sdk
- 9【鸿蒙开发】第十七章 Web组件(一)_鸿蒙 web组件 nweb
- 1012 个在线代码编辑器,有哪个比 GitHub Codespaces 更香?_在线写代码
【pyltp】windows安装pyltp_microsoft visual c++ compiler for python 2.7
赞
踩
申明:
python2.7.14
VCForPython27
pip install pyltp==0.1.9.1
model 3.3.1
顺利安装
1.安装python2.7
https://www.python.org/download/releases/2.7/ 下载安装即可

2.安装Micorsoft Visual C++ Compiler for Python 2.7
https://www.microsoft.com/en-us/download/details.aspx?id=44266 下载安装即可
3.安装pip
https://blog.csdn.net/oqqHun123/article/details/86767477
4.安装CMAKE

5.安装VS2008
配置cl环境变量(如我的是 C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin\cl.exe)
可能存在dll修复问题,若遇到请用directX修复工具,若还解决不了请参照下面内容:
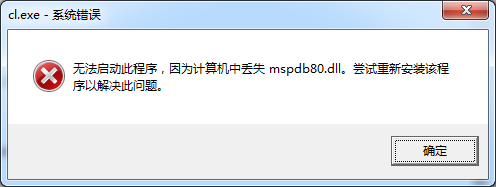
在cmd中键入cl执行编译时会出现mspdb80.dll无法找到的情况,是因为VC/Bin/下没有“msobj80.dll,mspdb80.dll,mspdbcore.dll,mspdbsrv.exe”这四个文件,解决的方法:
1>直接从Common7/IDE/下复制这四个文件到VC/Bin/下即可解决
2> 添加系统变量(Path),这样:我的电脑->属性->高级->环境变量->系统变量,在path中添加C:\Program Files (x86)\Microsoft Visual Studio 9.0\Common7\IDE;,注意结尾最后用“;”隔开!
这样在用cl编译就不会出现mspdb80.dll文件找不到的错误了。
6.安装pyltp
打开网址下载pyltp环境
https://pypi.org/project/pyltp/0.1.9.1

下载好解压后,在 pyltp-0.1.9.1 目录文件下打开cmd,python setup.py install 进行安装,大概10-20分钟后出现finished即完成

输入pip list 检查环境是否安装成功

7.下载模型
下载ltp的相关模型,可在此百度云选择下载:
http://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569
最终成功的组合是 :
pyltp版本 0.1.9.1
模型版本:3.3.1
8.上代码运行实例
- 修改model路径后运行即可,若出现 Segmentor: Model not loaded! 的问题请参照:
- https://blog.csdn.net/oqqHun123/article/details/86769943
pyltp相关文档:
https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id4
https://pyltp.readthedocs.io/zh_CN/latest/api.html#
pyltp是专注nlp领域的第三方工具,可以做分词,词性分析等nlp基础任务,而tensorflow是搭建神经网络的开源框架。

