
- 1关于mpvue和taro框架实战对比_mpvue taro 对比
- 2轻松写出高质量内容:6款自媒体ai写作工具全攻略! #人工智能#知识分享_ai工具写作自媒体
- 3OpenCV测量物体的尺寸技能 get~
- 4【LeetCode】每日一题:排序链表
- 5PMP认证证书的实际作用!_pmp是啥证书有什么作用
- 6python 堆的使用 heapq_heapq 包
- 7MYSQL中编辑表格相关基本操作指南_mysql怎么编辑表内内容英文
- 8RabbitMQ系列【13】优先级队列_rabbitmq优先级队列
- 9Spring MVC数据绑定和响应——简单数据绑定(一)默认类型数据绑定_chapter12项目在哪里
- 10现在企业出现网络安全问题的原因都有哪些?_2.引起这件网络安全风险的原因是什么?
SQL Server - Window Function - 聚合函数和Framing_sql server function
赞
踩
概要
窗口聚合函数本身具有极高的灵活性,在数据库开发过程中,可以满足一些复杂的查询需求。本文主要以举例说明的方式,来介绍聚合窗口函数的使用方法,以及性能调优。
为什么要用聚合窗口函数
在数据库开发过程中,像SUM,MAX,MIN等聚合函数主要是配合group by子句使用。但是出group by要求select后面的字段 要么是在聚合函数中,要么是在group by 中,具有一定的限制。而使用窗口聚合函数既可以达到分组聚合的要求,又完全不受该规则的限制,灵活性更大。
什么是聚合窗口函数
窗口函数的表达式如下:
window_function ( [ ALL ] expression )
OVER ( [ PARTITION BY partition_list ] [ ORDER BY order_list] )
- 1
- 2
我们看下表,该表格记录了每个同学的英语成绩和性别。现在我们希望新增两列,一列是按照性别分组的平均成绩,男生显示男生的平均成绩,女生显示女生的,另一列是全班的英语平均成绩。
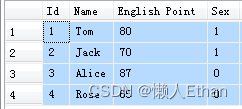
本例我们使用窗口聚合函数实现。本例窗口函数实际上是为每条记录开了两个窗口,第一个窗口是按照性别分组后的数据作为分组,另一个是全表数据作为窗口。聚合函数在两个窗口中,分别进行求平均值的运算。
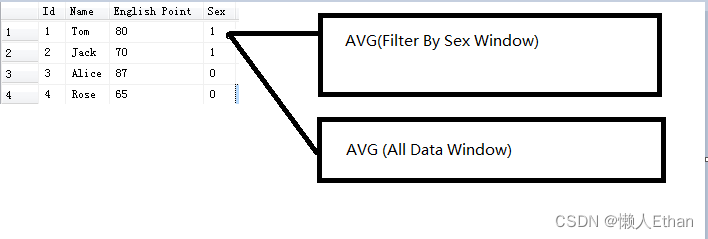
最后的SQL代码如下:
SELECT [Id]
,[Name]
,[English Point]
,[Sex]
,avg([English Point]) over (partition by sex order by Id rows between unbounded preceding and unbounded following ) EN_AVG_BY_SEX
,avg([English Point]) over (order by Id rows between unbounded preceding and unbounded following ) EN_AVG_ALL
FROM [Bankings].[dbo].[Table_EN]
order by Id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
聚合窗口函数主要有三部分组成:
- 聚合函数,决定具体操作行为
- over子句中的分组语句,决定窗口怎么开,是整个表格作为窗口,还是某个分组作为窗口。
- over子句中的排序语句,筛选窗口中的数据参与聚合。
复杂实例分析
我们采用MS的AdventureWorks2012数据库。
下载地址:https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2012.bak
复杂的累加问题
我们使用 Sales.SalesOrderHeader表,具体栏位包括CustomerID SalesOrderID, OrderDate, TotalDue
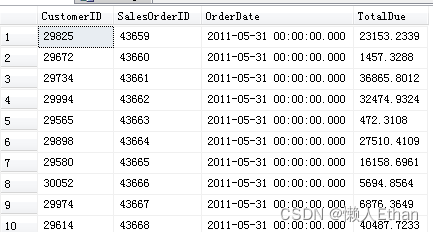
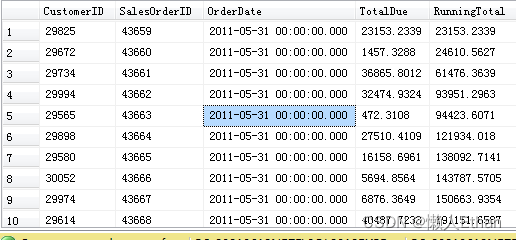
我们希望按照SalesOrderID排序,新增一列用于累加,对于每个SalesOrderID,该列计算从当前SalesOrderID到之前的全部SalesOrderID行对应的TotalDue的总和。
代码如下:
select
CustomerID,
SalesOrderID,
OrderDate,
TotalDue,
SUM(TotalDue) over (order by SalesOrderID ) RunningTotal
from Sales.SalesOrderHeader
order by SalesOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们按照窗口函数的格式来分析:
- 进行累加操作,所以使用SUM
- 根据需求,全表数据都要参与运算,所以PARTITION 省去。
- over中的order by SalesOrderID 表示窗口中的数据按照SalesOrderID升序拍列,每次聚合从当前SalesOrderID到之前的全部SalesOrderID的TotalDue
部分执行结果截图如下:
Order By中的重复数据处理
上面的例子中SalesOrderID是没有重复的,下面我们看一个有重复Id的情况。
我们使用 Purchasing.PurchaseOrderDetail表,具体栏位包括PurchaseOrderID, PurchaseOrderDetailID, ProductID, LineTotal。
我们希望按照PurchaseOrderID排序,新增一列用于累加,对于每个PurchaseOrderID,该列计算从当前PurchaseOrderID到之前的全部PurchaseOrderID行对应的LineTotal的总和。
SQL语句如下:
select
PurchaseOrderID,
PurchaseOrderDetailID,
ProductID,
LineTotal,
SUM(LineTotal) over (order by PurchaseOrderID) TotalDue
from Purchasing.PurchaseOrderDetail
order by PurchaseOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
部分执行结果截图如下:
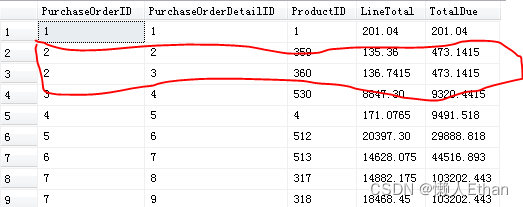
这次PurchaseOrderID不是唯一的了,在按照PurchaseOrderID升序排序后,如果PurchaseOrderID相同,会把PurchaseOrderID相同的行的LineTotal一次全部累加(并不会逐行累加)。所以第二行的TotalDue不是 336.40而是473.1415。
如果我们希望逐行累加,忽略PurchaseOrderID相同的影响,这个时候我们需要通过Framing的选项进行控制。代码如下:
select
PurchaseOrderID,
PurchaseOrderDetailID,
ProductID,
LineTotal,
SUM(LineTotal) over (order by PurchaseOrderID rows unbounded preceding) TotalDue2
from Purchasing.PurchaseOrderDetail
order by PurchaseOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
部分执行结果截图如下:
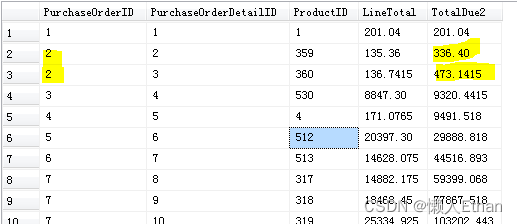
其实从字面意思就可以看出rows和range的区别,rows是基于行的操作,本例中就是从当前行到之前的所有行的数据进行聚合。range是范围的意思,表示小于等于当前行PurchaseOrderID的数据进行聚合。
Framing的默认值
Framing的默认值是 range unbounded preceding,具体意思我们看下面代码:
select
PurchaseOrderID,
PurchaseOrderDetailID,
ProductID,
LineTotal,
SUM(LineTotal) over (order by PurchaseOrderID) TotalDue_DEFAULT,
SUM(LineTotal) over (order by PurchaseOrderID range unbounded preceding) TotalDue_RANG
from Purchasing.PurchaseOrderDetail
order by PurchaseOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
部分执行结果截图如下:
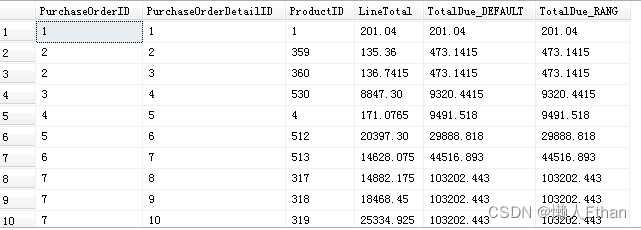
rows和range
rows和range在具体指定一部分数据参与聚合运行,如果ORDER BY中的栏位存在相同的数据,则执行结果不同。
rows和range在具体指定全表参加聚合运算时候没有区别,我们看下面的SQL
select
PurchaseOrderID,
PurchaseOrderDetailID,
ProductID,
LineTotal,
SUM(LineTotal) over (order by PurchaseOrderID rows between unbounded preceding and unbounded following) TotalDue_ROWS,
SUM(LineTotal) over (order by PurchaseOrderID range between unbounded preceding and unbounded following) TotalDue_RANGE
order by PurchaseOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
部分执行结果截图如下:
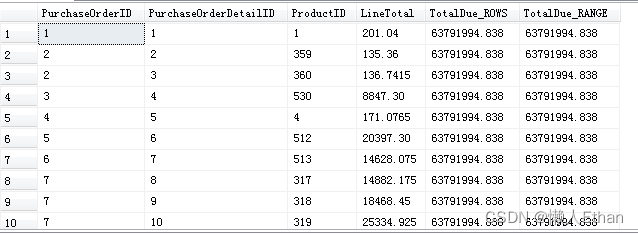
rows指定具体的行数参与聚合
我们还是按照order by PurchaseOrderID的方式进行聚合,累加LineTotal列,这次我们聚合当前PurchaseOrderID的,以及它前面一个PurchaseOrderID和后面一个PurchaseOrderID的LineTotal。 SQL如下:
select
PurchaseOrderID,
PurchaseOrderDetailID,
ProductID,
LineTotal,
SUM(LineTotal) over (order by PurchaseOrderID rows between 1 preceding and 1 following) TotalDue
from Purchasing.PurchaseOrderDetail
order by PurchaseOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
部分执行结果截图如下:
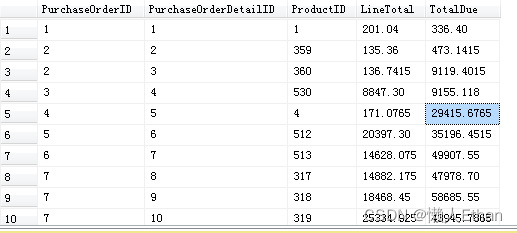
注意range不支持具体行数的情况,所以当前例子不能用range替换rows
Partition By的例子
在增加了Partition By语句后,前面阐述的range和rows的区别依然成立。
我们这次使用Sales.SalesOrderDetail表,涉及的栏位包括SalesOrderID, SalesOrderDetailID, LineTotal。
要求每条数据新增聚合列RunningTotal,聚合规则是按照SalesOrderID进行分组,每个分组按照LineTotal进行排序,每条数据的RunningTotal计算当前LineTotal和分组内小于LineTotal的全部行的LineTotal进行累加。
SQL如下:
select
SalesOrderID,
SalesOrderDetailID,
LineTotal,
SUM(LineTotal) over(partition by SalesOrderID order by LineTotal range unbounded preceding) RunningTotal_RANGE,
SUM(LineTotal) over(partition by SalesOrderID order by LineTotal rows unbounded preceding) RunningTotal_ROWS
from Sales.SalesOrderDetail
order by SalesOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
部分执行结果截图如下:
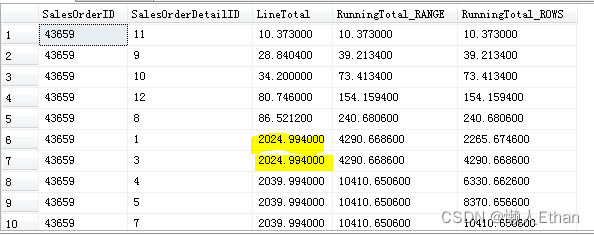
可以看到在LineTotal相同的情况,rows和range的聚合结果依然是不同的。
性能调优
rows的实现是基于TempDB,range的实现就是内存操作。所以在性能上rows一般会高于range。
我们看下面的SQL:
set statistics io on
select
CustomerID,
SalesOrderID,
OrderDate,
TotalDue,
SUM(TotalDue) over (order by SalesOrderID ) RunningTotal
from Sales.SalesOrderHeader
order by SalesOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
如果没有指定Framing,则默认是range,我们打开IO的分析器后,SQL Server的统计信息如下:

set statistics io on
select
CustomerID,
SalesOrderID,
OrderDate,
TotalDue,
SUM(TotalDue) over (order by SalesOrderID rows unbounded preceding ) RunningTotal
from Sales.SalesOrderHeader
order by SalesOrderID
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

从执行结果的分析看rows的IO数量明显小于range的情况。

