
热门标签
热门文章
- 1如何用NLP辅助投资分析?三大海外机构落地案例详解
- 2Python基于深度学习的车辆特征分析系统(V2.0),附源码
- 3NLP中任务总结_cloze task
- 4常见的cuda出错及解决方法_cuda异常
- 5国产具身人形机器人征服复杂场景: 实时感知规划,动态运动告别“盲走”
- 6鸿蒙Harmony应用开发—ArkTS声明式开发(基础组件:AlphabetIndexer)_鸿蒙 private arr: a[] = [] 添加值
- 7vs2010最佳配色选择_2010年代35部最佳电影
- 8NLP学习笔记——BERT的一些应用(简记)_bertlmheadmodel
- 9直播预告|Sora 会怎样驱动视频编解码领域的突破与革新
- 10【python】之pyautogui库,实现自动化办公!_pyautogui办公
当前位置: article > 正文
Triton Server Python 后端优化
作者:小蓝xlanll | 2024-04-09 09:19:04
赞
踩
Triton Server Python 后端优化
接上文 不使用 Docker 构建 Triton 服务器并在 Google Colab 平台上部署 HuggingFace 模型
MultiGPU && Multi Instance
Config
追加
·
·
·
instance_group [
{
count: 4
kind: KIND_GPU
gpus: [ 0, 1 ]
}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python Backend
Triton 会根据配置信息启动四个实例,model_instance_device_id 可以获取到 Triton 给每个实例自动分配的 GPU,模型加载到GPU时使用 .to(f"cuda:{gpu}"时指定 GPU 的 id 即可。
import numpy as np import triton_python_backend_utils as pb_utils from transformers import ViTImageProcessor, ViTModel from diffusers import DiffusionPipeline import torch import time import os import shutil import json import numpy as np class TritonPythonModel: def initialize(self, args): gpu = json.loads(args["model_instance_device_id"]) self.model = DiffusionPipeline.from_pretrained( "playgroundai/playground-v2.5-1024px-aesthetic", torch_dtype=torch.float16, variant="fp16" ).to(f"cuda:{gpu}") · · ·

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Dynamic Batch
开启此配置 Triton 会将一段时间间隔内的请求组成一个batch交给模型批处理
Config
·
·
·
dynamic_batching {
max_queue_delay_microseconds: 100
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Python Backend
此时需要对后端代码进行改造,之前的代码每次只能处理一个请求,GPU仅仅占用30G,对于80G的 GPU 来说实在是浪费资源。SDXL 依次是可以处理多个 Prompt 生成多个图片的,只要不把现存撑爆就行。现在我们要在最大 Batch 的限制内处理多个请求,假设客户端每个请求只包含一个 Prompt。
我们获取到一个请求后不直接输入到模型,而是都添加到 Prompts 列表里,然后统一生成图片,然后把生成的图片和请求一一对应上,最后响应给客户端就OK了。
· · · def execute(self, requests): responses = [] prompts = [] for request in requests: inp = pb_utils.get_input_tensor_by_name(request, "prompt") for i in inp.as_numpy(): prompts.append(i[0].decode()) images = self.model(prompt=prompts, num_inference_steps=50, guidance_scale=3).images pixel_values = [] for image in images: pixel_values.append(np.asarray(image)) inference_response = pb_utils.InferenceResponse( output_tensors=[ pb_utils.Tensor( "generated_image", np.array(pixel_values), ) ] ) responses.append(inference_response) return responses
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
ONNX_RUNTIME(失败)
转换 playgroundai/playground-v2.5-1024px-aesthetic pipeline 为 onnx 格式
pip3 install diffusers>=0.27.0 transformers accelerate safetensors optimum["onnxruntime"]
optimum-cli export onnx --model playgroundai/playground-v2.5-1024px-aesthetic --task stable-diffusion-xl playground-v2.5_onnx/
- 1
- 2

分享已经转换好的文件:
测试一下
from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "playground-v2.5_onnx"
pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
# pipeline.save_pretrained("playground-v2.5-onnx/")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
成功加载,发现使用的是 CPU 推理,参考Accelerated inference on NVIDIA GPUs发现默认是用CPU,需要卸载 optimum[“onnxruntime”] 安装 optimum[onnxruntime-gpu]。
pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id, provider="CUDAExecutionProvider", device=f"cuda:{gpu}")
- 1
FAQ
CPU 推理正常,GPU推理报错,类似这种错误:
- [E:onnxruntime:Default, provider_bridge_ort.cc:1480 TryGetProviderInfo_CUDA] /onnxruntime_src/onnxruntime/core/session/provider_bridge_ort.cc:1193 onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libcublasLt.so.12: cannot open shared object file: No such file or directory
解决方法: 安装CUDNN,官方手册
apt install libcudnn8=8.9.2.26-1+cuda12.1 -y
apt install libcudnn8-dev=8.9.2.26-1+cuda12.1 -y
apt install libcudnn8-samples=8.9.2.26-1+cuda12.1 -y
- 1
- 2
- 3
- 2024-04-08 15:21:39.497586288 [E:onnxruntime:, sequential_executor.cc:514 ExecuteKernel] Non-zero status code returned while running Add node. Name:‘/down_blocks.1/attentions.0/Add’ Status Message: /down_blocks.1/attentions.0/Add: left operand cannot broadcast on dim 3 LeftShape: {2,64,4096,10}, RightShape: {2,640,64,64}
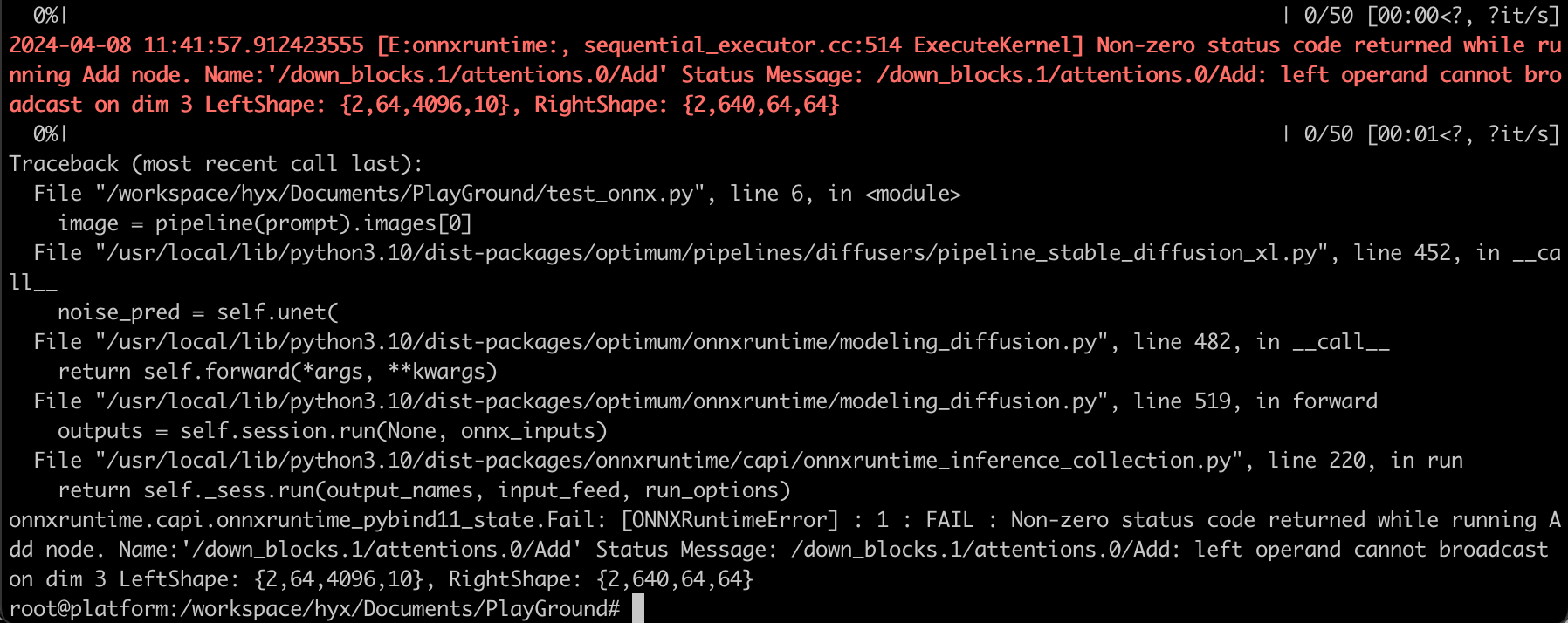
解决方法:
未解决,参考 Issue
TENSORRT_RUNTIME
Doing…
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/391740
推荐阅读

相关标签

