
- 1Hume获5000万美元融资,推出首个“情商”AI聊天助手
- 2.NET中的IO操作基础介绍
- 3如何搭建一个 tts 语言合成模型_tts模型训练
- 4微信小程序--多种类型日期选择器(年月、月日...)_微信小程序时间筛选
- 5HarmonyOS学习第二课:关于横向滚动视图的一些想法_harmonyos div 滚动
- 6ChatGPT扩展系列之跨平台桌面客户端ChatBox
- 7SSM+Vue+Element-UI实现网上跳蚤市场_uview跳蚤市场
- 8手把手教你做小型机器狗,毕业设计。必看_机器狗编程制作教程
- 98、MapReduce实现WordCount单词统计_wordcount只统计长度超过2的单词怎么设计mapreduce函数
- 102024年的七大前端Web开发趋势_2024 年 7 个 web 前端开发趋势
BERT-as-service 时隔三年突然更新,这次连名儿都改了_petrel_client
赞
踩
无需担心复杂的实现细节,只需简单调用 API,就可以为文本和图像创建 SOTA 表征向量。
从 BERT 到 BERT-as-service
2018 年 9 月,Google 一篇 BERT 模型相关论文引爆全网:该自然语言模型,在机器阅读理解顶级水平测试 SQuAD1.1 中,连破 11 项 NLP 测试记录,两个衡量指标全面超越人类。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
这不仅开启了 NLP 的全新时代,也标志着迁移学习和预训练+微调的模式,开始进入人们的视野。
2018 年 10 月,BERT 发布仅一个月后,BERT-as-service 横空出世。用户可以使用一行代码,通过 C/S 架构的方式,连接到服务端,快速获得句向量。
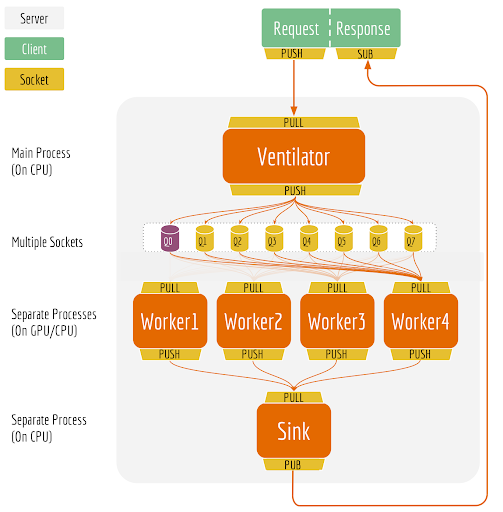
作为基于 BERT 的第一个微服务框架,BERT-as-service 通过对 BERT 的高度封装和深度优化,以方便易用的网络微服务 API 接口,赢得了 NLP 及机器学习技术社区的广泛关注。
它简洁的 API 交互方式、文档写作风格,甚至连 README 排版,都成为之后众多开源项目的模板。
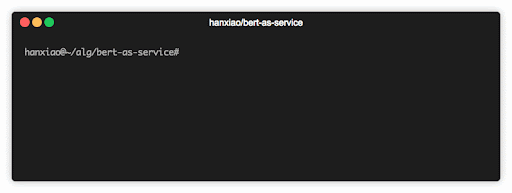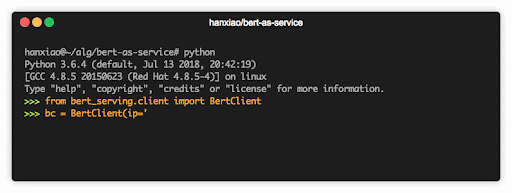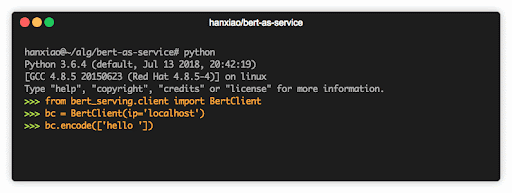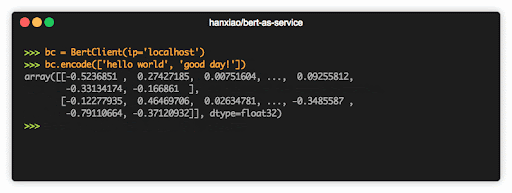
如果说 BERT 是迁移学习的里程碑,那么 BERT-as-service 的出现,可以称得上是迁移学习,在工程服务化的里程碑。
GitHub 上 BERT 模型的不少贡献者,也积极参与了 BERT-as-service 的代码贡献。火遍全球的 Hugging Face 在 2018 年 11 月推出的 Pytorch-transformers 初版,也受到了 BERT-as-service 的启发。
尽管 BERT-as-service 在 2019 年 2 月后的更新逐渐暂停,但 3 年来该项目在 GitHub 上积累了 10,000 个 Star, 2,000 多个 Fork 和堆积成山的 Issue,都显示出社区对 BERT-as-service 的极大兴趣和热情。
其中很多开发人员 Fork 了 BERT-as-service 并结合自身业务,开发出了一套自己的微服务系统。
BERT-as-service 升级版重磅来袭
时隔三年,BERT-as-service 再度更新,升级为全新的 CLIP-as-service,不仅保留了原有的高并发、微服务、简单易用等特性,更可以同时生成文本和图像的表征向量。

CLIP-as-service 的背后是由 OpenAI 在 2021 年 1 月发布的 CLIP (Contrastive Language-Image Pre-training) 模型,它可以基于文本对图像进行分类,打破了自然语言处理和计算机视觉两大门派「泾渭分明」的界限,实现了多模态 AI 系统。
CLIP-as-service具有以下特点:
* 开箱即用:无需额外学习,只需调用客户端或服务端的 API,即可实时生成图像和文本的向量输出。
* 速度快:为大型数据集和长耗时任务量身定制,同时支持 ONNX 和 PyTorch 模型引擎,以提供快速推理服务。
* 高扩展:支持多核、单核 GPU 上并行扩展多个 CLIP 模型,并自动进行负载均衡。服务器端可以选择通过 gRPC、Websocket 或 HTTP 三种方式对外提供服务。
* 神经搜索全家桶:开发者可以短时间内,快速融合 CLIP-as-service 及 Jina、DocArray,搭建跨模态和多模态搜索行业解决方案。
CLIP-as-service 实操指南
安装 CLIP-as-service
同 BERT-as-service 的 C/S 架构一样,CLIP-as-service 也分为服务器端和客户端两个安装包。
开发者可通过 pip 在不同的机器上选择性地安装 CLIP 客户端或服务端。
注意:请确保使用 Python 3.7+
1、安装 CLIP 服务端(通常是 GPU 服务器)
pip install clip-server2、安装 CLIP 客户端(比如在本地笔记本电脑上)
pip install clip-client启动 CLIP 服务器
启动服务器意味着下载预训练模型,启动微服务框架,对外开放接口等一系列操作。所有这些操作都可以通过一句简单的命令完成。
启动服务器:
python -m clip_server服务器启动后,将显示以下输出:
-
- 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/371130推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

