
- 1《动手学深度学习 Pytorch版》 10.5 多头注意力_pytorch中多头注意力机制的
- 2oracle中asm是什么,什么是ASM?
- 3深度学习之群卷积(Group Convolution)
- 4鸿蒙开发入门教程—瀑布流的实战案例_鸿蒙瀑布流
- 5在C#中像Python一样编写TensorFlow机器学习代码_ml.net
- 6spring boot 拦截 以及Filter和interceptor 、Aspect区别_@after interceptor
- 7全球首位AI程序员诞生,我们的饭碗真的要被抢走了吗?
- 8【opencv】教程代码 —ImgProc (9) 图像金字塔
- 9ChatGLM-6B 中文对话模型复现、调用模块、微调及部署实现(更新中)_chatglm 可复现性
- 10MySQL进阶-----索引的结构与分类
深度学习(十三) Adversarial Attack 理论部分
赞
踩
前言
本文主要介绍的是现在比较新型的对抗攻击部分,这个部分资料甚少,作为科普使用
一、Adversarial Attack的用途是什么?
- 在深度学习网络里面,很多网络都是容易被攻击的,所以不能大量投入使用,所以我们要对对抗攻击有了比较深入的理解之后,才能对对抗防御有比较深入的理解
- 对抗样本攻击也在自编码器和生成模型,在循环神经网络,深度强化学习,在语义切割和物体检测等方面也有应用。
二、Adversarial Attack的分类
- 白盒攻击,称为White-box attack,也称为open-box 对模型和训练集完全了解,这种情况比较简单,但是和实际情况不符合。
- 黑盒攻击,称为Black-box attack,对模型不了解,对训练集不了解或了解很少。这种攻击和实际情况比较符合,主要也是主要研究方向。
- 定向攻击,称为targeted attack,对于一个多分类网络,把输入分类误判到一个指定的类上,即指定判断错误的类别
- 非定向攻击,称为non-target attack,只需要生成对抗样本来欺骗神经网络,可以看作是上面的一种特例。
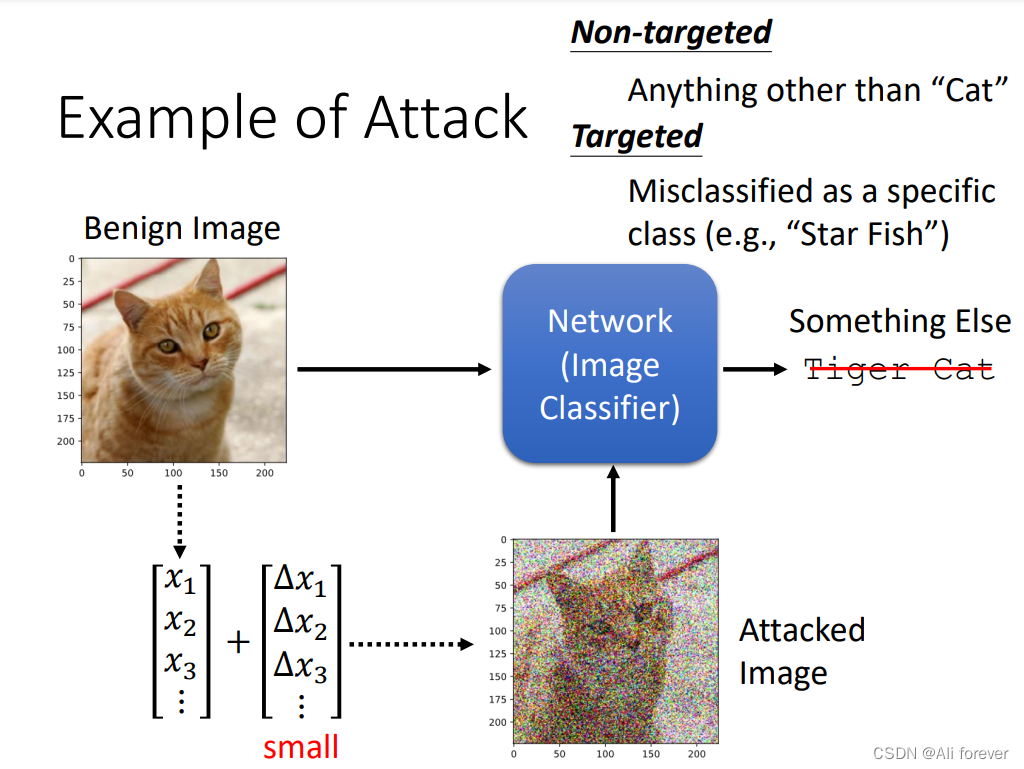
三、如何实现Adversarial Attack?
1.对于non-target attack而言
这种情况比较简单,因为只需要让判别器判别错误即可,并不需要进行定向地改变,所以我们只要设定一个误差函数
e
(
y
,
y
^
)
e(y,\hat y)
e(y,y^),让这个值越大就说明两值的差距越大,即:
x
∗
=
arg
min
−
e
(
y
,
y
^
)
x^*=\arg\min -e(y,\hat y)
x∗=argmin−e(y,y^)
我们重点来看看定向地攻击模型。
2.对于targeted attack而言
相对于non-target attack,targeted attack需要最后的判断结果与自己设定的定向结果很接近,也就是我们要引入一个目标输出,其函数变为:
x
∗
=
arg
min
−
e
(
y
,
y
^
)
+
e
(
y
,
y
t
a
r
g
e
t
)
x^*=\arg\min -e(y,\hat y) +e(y,y^{target})
x∗=argmin−e(y,y^)+e(y,ytarget)
然后如果两张照片的差值过于大的时候,将会面目全非,不符合我们一开始肉眼看不到的假设,所以我们需要给两张照片的像素值之间设有一定的限制,一般我们有L2-norm和L-infinity两种方法。
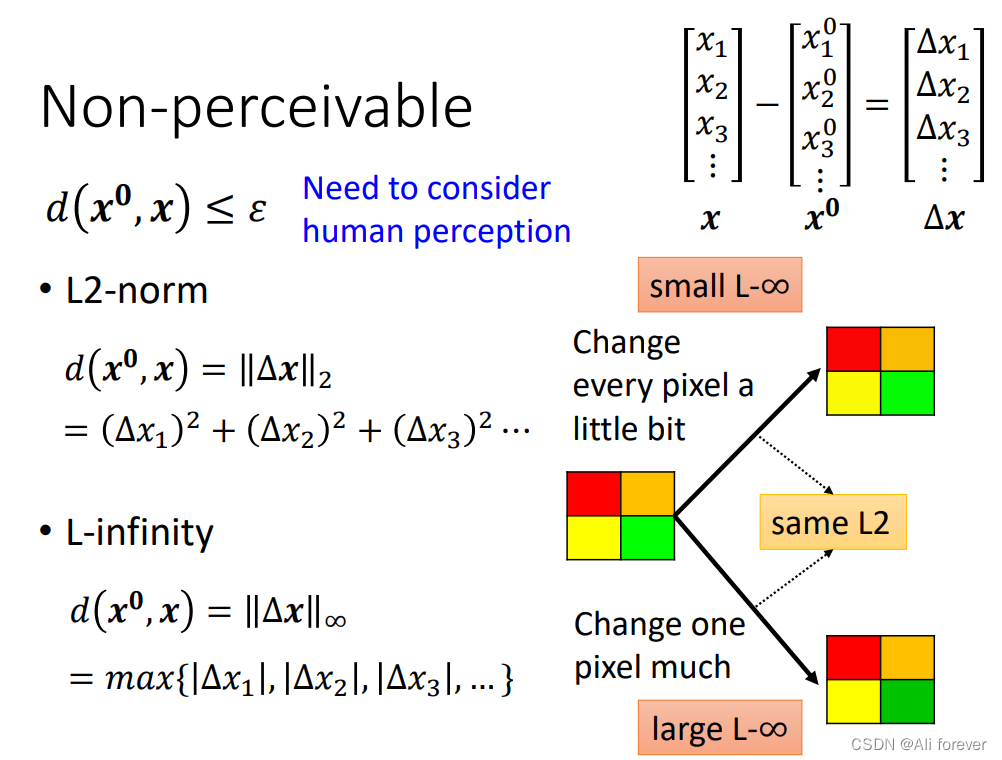
对于我们人眼而言,一般只会感知最大变化的那一个部分,如果像L2-norm这样把所有误差求和,这样的误差值过大了,所以一般L-infinity的方法会有更好的表现效果。
3.训练模型
由于加入了我们刚才的那一个限制,我们本可以用拉普拉斯算子去进行优化,但是我们采取了一种更加简单的方法进行梯度下降。

一开始我们会比较正常地进行梯度下降,但是当我们的这个差距大于
ϵ
\epsilon
ϵ时,我们强制拉回以我们更新点
x
0
x_0
x0为中心的正方形范围内的随机一个边框点,完成我们的更新。
为了更简单进行我们的梯度下降,大大减少运算量,我们可以对x进行符号化,也就是规定x的取值只有四个点,并且人为设定更新的次数。

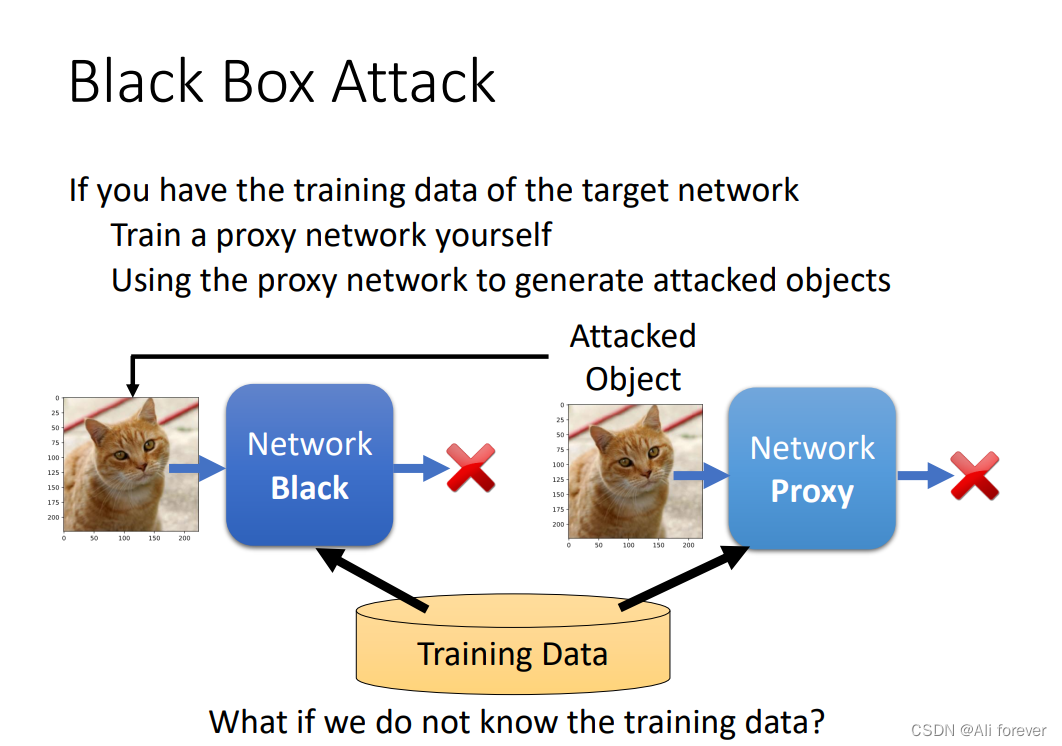
4.Black Box Attack
我们前面说过,白盒攻击比较简单,如果一直不发放模型,就无法知道参数,就无法进行白盒攻击,但是这样是否就绝对安全呢?答案是否定的,因为我们可以进行黑盒攻击,黑盒攻击可以在不知道训练集的情况下进行,具体操作如下:
- 可以把一堆图片丢到NN中,得到输出的图片,把输入和输出图片丢到network proxy来训练出一个模型
- 我们可以通过同一组训练集来训练一个network proxy,来模拟network black
- 从而通过攻击network proxy观察,就可以来攻击network black
5.“Backdoor” in Model
除此之外,我们除了对测试集进行攻击,我们还可以对训练模型进行攻击,当训练模型出问题的时候,测试集是什么已经不重要了。
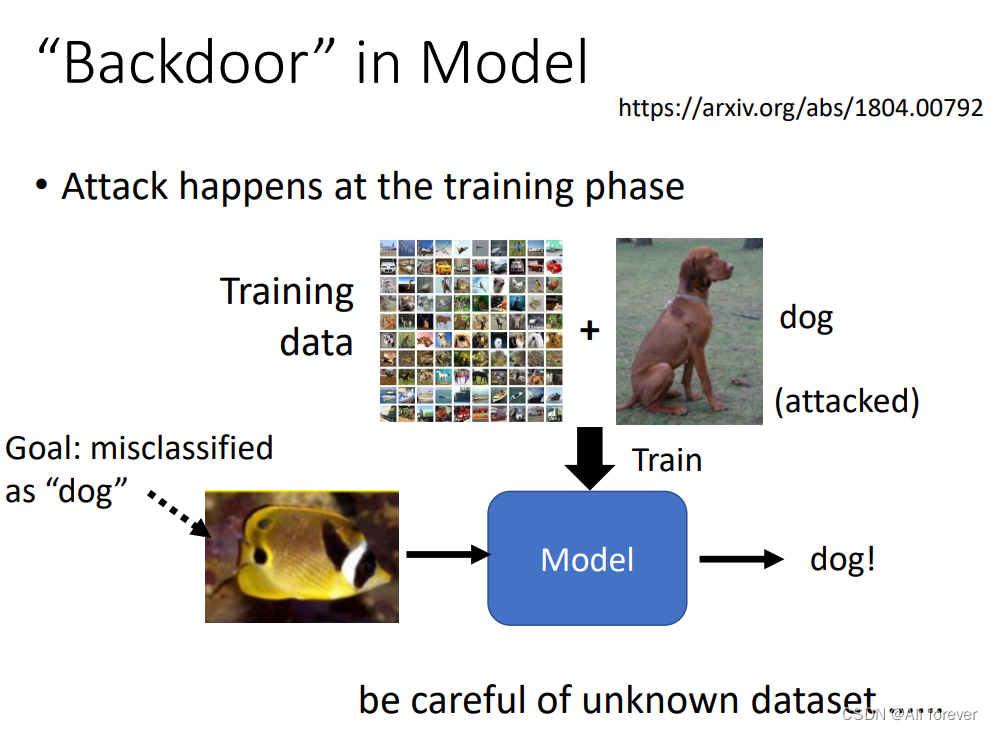
我们可以看到在训练阶段我们引入了"dog"这个种类,然后让其判断成"fish",这就提高了攻击的成功率了。
四、Defense
刚刚我们介绍了许多攻击的方式,那有了这些攻击的经验我们应该如何防御呢?下面将会介绍几种防御的方法。
1.Passive Defense
被动防御是一种比较简单的防御方式,主要的方式有:
- 被动防御就是指在模型之前加上一个过滤器,去减小Attack signal的强度,使Network辨识正确。

- 主要的方法有对图片进行模糊化,对图片进行压缩处理;将图片使用Generator重新产生一张相同的图片。

- 还有一种方法,就是进行随机防御,这种防御对于进攻者来说非常难进攻,因为防守者没有固定的防守手段。
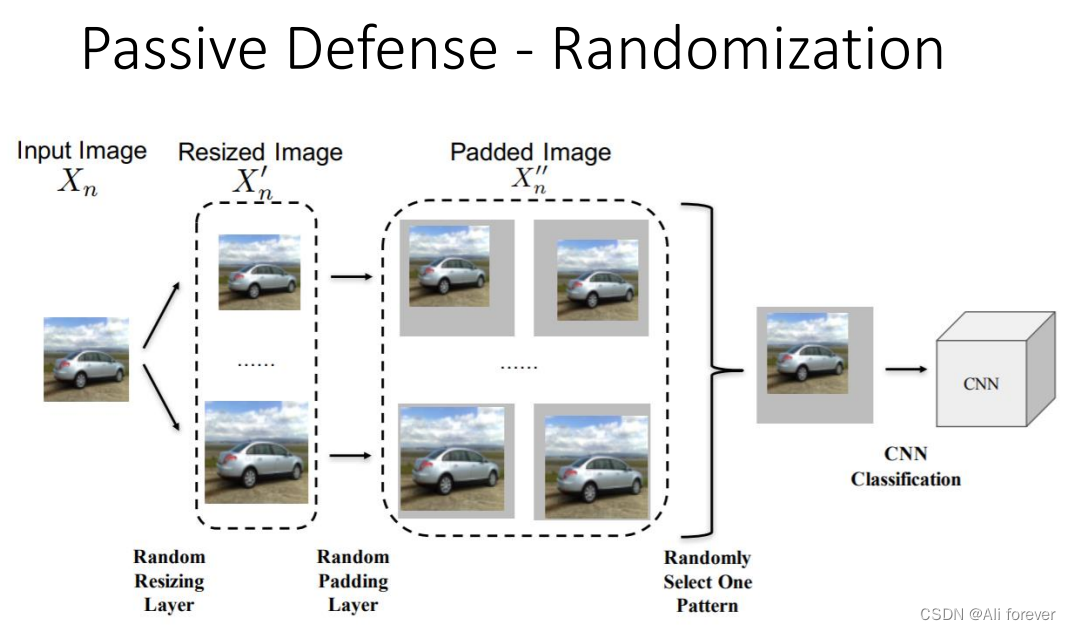
被动防御的缺点是:没有被攻击的图片进行模糊化后,会导致分数下降

2.Proactive Defense
这种防御手段跟被动防御完全不一样,它一开始就训练出一个不容易被攻破的模型,具体过程就是在训练阶段就对模型进行攻击,然后把训练后得到的资料重新去训练模型,反复进行这个过程,就会得到一个不容易被攻破的模型。

但是这种方法未必能抵挡住新的攻击,而且Adversarial Training需要大量的训练资源。

