
热门标签
热门文章
- 1Ubuntu22.04系统 arm64虚拟机 安装cANN_ubuntu23 arm64
- 2vscode转到解释器,转到含torch的就可以import torch_vscode无法解析导入“torch”pylancer
- 3uni-app实现登录功能之一_uniapp切换用户登录
- 4MATLAB仿真光的干涉(五)_法布里-珀罗matlab仿真
- 5【DevEco Studio】真机调试,自动签名失败_deveco 启动签名错误
- 6什么是机器学习?_机器学习是什么
- 7docker入门及实战(纯干货)_docker技术入门与实战
- 8全是精华,GIthub获星65kAndroid面试题(java、Android性能调优、IPC和SDK、第三方框架分析 、数据结构、设计模式、计算机网络和kotlin等)_android 面试 github
- 9MySQL高端局,不把这些吃透,谈什么优化?_谓最左前缀,可以想象成一个爬楼梯的
- 10python建立等面积缓冲区_python geom.buffer
当前位置: article > 正文
吴恩达|chatgpt 提示词工程师学习笔记。_吴恩达 提示词工程
作者:小蓝xlanll | 2024-03-22 23:06:43
赞
踩
吴恩达 提示词工程
目录
吴恩达和openai团队共同开发了一款免费的课程,课程是教大家如何更有效地使用prompt来调用chatgpt,整个课程时长1个半小时,也提供了对应的环境和代码,大家可以去学习。
课程链接:ChatGPT Prompt Engineering for Developers - DeepLearning.AI
(小伙伴也可以在B站自行搜索,有搬运的视频)
推荐重点看下一、二和代码的demo,其他的是一些case,对我来说价值没那么大
一、提示指南
-
写提示词的2大原则:
- 原则1:书写清晰具体的指令
- 使用分隔符,帮助chatgpt更好地分辨指令和内容
- 让chatgpt提供结构化的输出,比如html,json
- 让chatgpt做任务前,确认当前条件是否满足
- few-shot prompting,给几个完成任务的成功案例,然后让模型照葫芦画瓢
- 原则2:给模型一些意见去思考
- 将任务拆解成几个具体的步骤,让chatgpt按步骤完成任务
- 让模型自己想出问题的解法,而不是直接给个答案问是否正确。
- 原则1:书写清晰具体的指令
-
模型的限制
- 模型会尝试编造一些不存在的回答
- 让模型找到相关信文档,再基于文档回答问题。追溯文档可以帮助你快速定位是否会虚假回答
- 模型会尝试编造一些不存在的回答
二、迭代
步骤:
- 给出清晰具体的prompt --给出一把中世纪椅子的产品说明
- 分析为什么结果不符合预期--太长了
- 按照修改思路和prompt--将产品说明限定在50字之内
- 重复上述过程,直至获得满意的结果
后面的几节课给出了如何使用prompt+chatgpt完成一些常见的NLP任务。基本实例如下,每节课根据目标不同,prompt也要做出相应的修改。
- import openai
- import os
-
- from dotenv import load_dotenv, find_dotenv
- _ = load_dotenv(find_dotenv()) # read local .env file
-
- openai.api_key = os.getenv('OPENAI_API_KEY')
-
-
- def get_completion(prompt, model="gpt-3.5-turbo", temperature=0):
- messages = [{"role": "user", "content": prompt}]
- response = openai.ChatCompletion.create(
- model=model,
- messages=messages,
- temperature=temperature,
- )
- return response.choices[0].message["content"]
-
-
- prompt = f"""
- Translate the following English text to Spanish: \
- ```Hi, I would like to order a blender```
- """
- response = get_completion(prompt)
- print(response)

三、总结
给出的例子是让chatgpt总结用户的评论,
后续修改prompt,让它为物流、定价部门总结评论,那对应的结果也会不同
四、推断
现在可以用chatgpt+prompt做一些文本分类的任务,并且效果还不错
- 使用chatgpt做情感分析
- 主题提取
- 给定对应的主题,让chatgpt判断是这当中的哪一个
五、转换
- 翻译
- 让chatgpt翻译一段文本
- 让chatgpt辨别一段文本属于什么语言
- 语气的转化
- 让chatgpt将文本以商业信函的格式重新写一遍。
- 转化格式
- 使用chatgpt将json转化为html
- 语法&拼写检查
- 使用python 中的redlines来查看前后的区别
- from redlines import Redlines
-
- diff = Redlines(text,response)
- display(Markdown(diff.output_markdown))
六、扩展
这里介绍了温度,一个模型参数,用以改变模型响应的多样性的。
温度越高,随机性越大。当需要构建一个可靠和可预测的系统时,温度应当为0。当需要更有创意的方式使用模型时,可以使用更高的温度。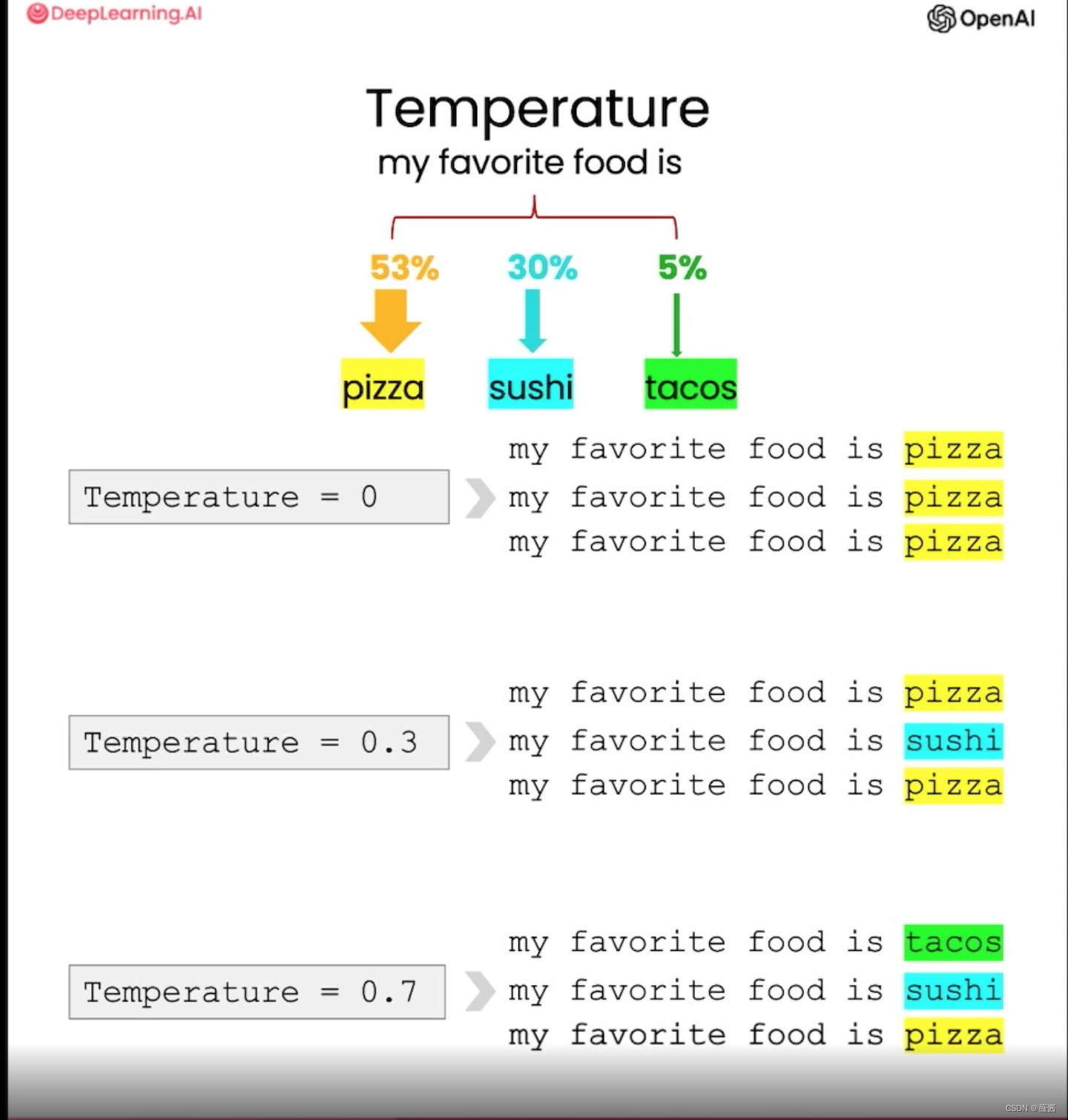
调用方式也很简单,在之前的函数中传递temperature参数。
response = get_completion(prompt, temperature=0.7)七、对话机器人
之前的任务中,都是单一消息,单一回复。而在对话机器人中,会有多轮对话,且有多个角色。
一般来说,会有以下三个角色:
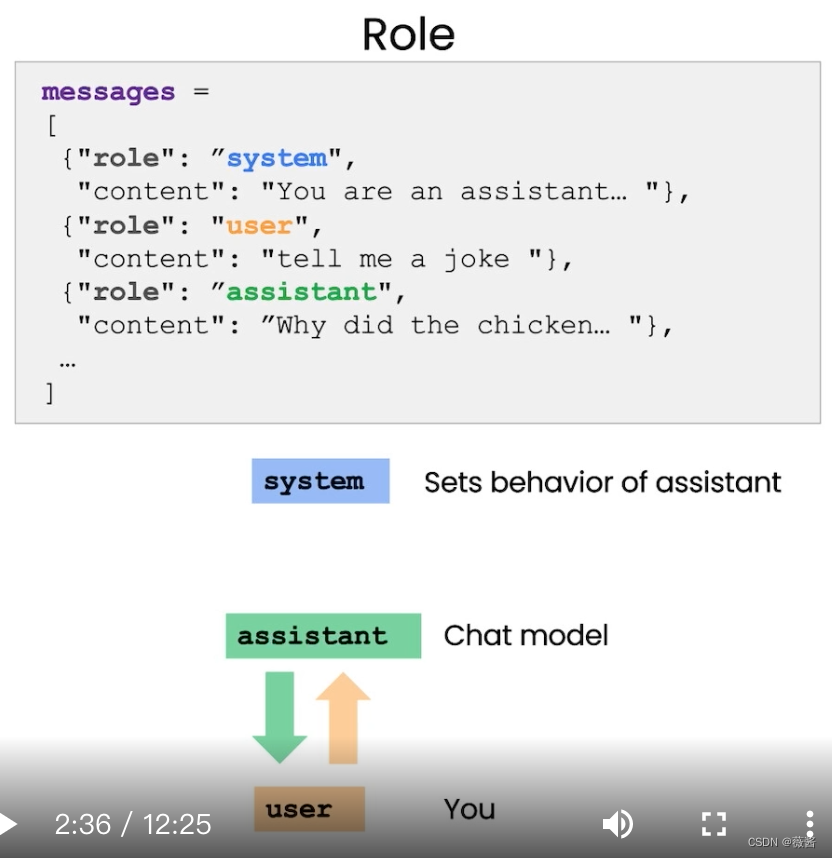
system:提供了整体的指导方针,比如告诉chatgpt,它是一个助手。用以引导助手,用户感知不到它的存在。
assistant:在我们的感知中,就是chatgpt
user:就是使用者,提出问题,使用prompt的人
可以使用system message让助手扮演某种角色,比如教授小学生的老师。
调用代码:
- def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
- response = openai.ChatCompletion.create(
- model=model,
- messages=messages,
- temperature=temperature, # this is the degree of randomness of the model's output
- )
- # print(str(response.choices[0].message))
- return response.choices[0].message["content"]
-
-
- messages = [
- {'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'},
- {'role':'user', 'content':'tell me a joke'},
- {'role':'assistant', 'content':'Why did the chicken cross the road'},
- {'role':'user', 'content':'I don\'t know'} ]
-
- response = get_completion_from_messages(messages, temperature=1)
- print(response)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/291528
推荐阅读
相关标签

