
热门标签
热门文章
- 12023,九章云极DataCanvas的澎湃时刻
- 2一个比较完善的httpWebRequest 封装,适合网络爬取及暴力破解
- 3rsync—远程同步_rsync远程拷贝文件
- 4首先是java接口代码写了四个让前端请求的接口,以下为代码_java后端api接口供前端调用代码
- 5卸载WPS但电脑设备和驱动还显示WPS网盘图标,右击删除却是灰色_wps删除后留了一个网盘
- 6开窗函数 OVER(PARTITION BY)函数介绍_开窗函数partition by
- 7构造方法以及构造方法的重载
- 8【AI绘画】Stable Diffusion 提示词——时尚日志封面_stable diffustion 照片质量正向通用提示词
- 9看了同事用AI做项目管理,我人都傻了!
- 10微软 AR 眼镜新专利:包含热拔插电池_ar新专利
当前位置: article > 正文
【你的第一个大模型微调,Qwen1_8B-Chat-Int8,8G显卡】_qwen-1_8b-chat
作者:小蓝xlanll | 2024-03-22 20:44:46
赞
踩
qwen-1_8b-chat
你的第一个大模型微调,Qwen1_8B-Chat-Int8,8G显卡
部署第一个小模型后进行finetuning微调。先学习一下调用API,再用web启动服务,最后微调训练完以后用web服务验证。
一、调用API
有openapi,还有dashscopeapi,都是类似的,学会一个就会另一个。主要试的第二个,链接如下。
使用环境变量保存,linux下用
export DASHSCOPE_API_KEY="YOUR_DASHSCOPE_API_KEY"
- 1
windows下可以
setx DASHSCOPE_API_KEY="YOUR_DASHSCOPE_API_KEY"
- 1
也可以直接设置环境变量。
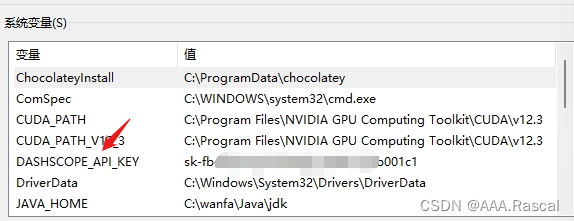
按照实例调用就行,代码里面不用单独写api_key,程序会自动去环境变量里面找。
ps:设置完后要重启一下vscode,我说半天怎么不行呢,这家伙一直没重新读取环境变量。
二、启动web服务
1.下载Qwen官方代码
git clone https://hub.yzuu.cf/QwenLM/Qwen.git#github国内镜像网站,不用魔法
- 1
2.环境依赖及运行
cd Qwen
pip install -r requirements_web_demo.txt
- 1
- 2
命令行启动,或者程序运行都行
python web_demo.py#具体在Qwen文件夹里
- 1
然后就行了。
三、微调
1、windows下详看这篇文章(我有所改动),linux照github QWEN官方做。
python finetune.py --model_name_or_path C:/Users/A/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int8 --data_path C:/lkp/LLM/qwen1.8B/qwen_data_process/q_answer/chat.json --fp16 True --output_dir output_qwen --num_train_epochs 5 --per_device_train_batch_size 2 --per_device_eval_batch_size 1 --gradient_accumulation_steps 8 --evaluation_strategy "no" --save_strategy "steps" --save_steps 1000 --save_total_limit 10 --learning_rate 3e-4 --weight_decay 0.1 --adam_beta2 0.95 --warmup_ratio 0.01 --lr_scheduler_type "cosine" --logging_steps 1 --report_to "none" --model_max_length 512 --lazy_preprocess True --gradient_checkpointing --use_lora
- 1
ps:
1.去下载他的chat.json文件,照着那篇文章做就行,这里我用的绝对路径。此为lora微调,还有全参数微调,显卡要求高,还有Q-lora微调,要求比lora低。
2.如果出现json读取错误问题,改一下finetune.py代码
try:
train_json = json.load(open(data_args.data_path, "r"))
except:
train_json = json.load(open(data_args.data_path, "r",encoding='utf8'))
- 1
- 2
- 3
- 4
2、训练结束后怎么调用新的模型
1.直接调用
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("C:/Users/A/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int8", revision='master', trust_remote_code=True) from peft import AutoPeftModelForCausalLM model = AutoPeftModelForCausalLM.from_pretrained( f'C:\lkp\LLM\qwen1.8B\Qwen\output_qwen', # path to the output directory device_map="auto", trust_remote_code=True ).eval() response, history = model.chat(tokenizer, "你来自哪里", history=None) print(response) response, _ = model.chat(tokenizer, "你是谁", history=None) print(response)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
web_demo.py 照此改动才能使用。改动完毕后重新启动web会发现你是谁的问题已经改过来了。
ps:没合并的话,基本模型地址不变,tokenizer和config仍然是之前的,仅model变化
DEFAULT_CKPT_PATH = 'C:/Users/A/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int8' #没合并的话,基本模型地址不变,tokenizer和config仍然是之前的,仅model变化 def _load_model_tokenizer(args): tokenizer = AutoTokenizer.from_pretrained( args.checkpoint_path, trust_remote_code=True, resume_download=True, ) if args.cpu_only: device_map = "cpu" else: device_map = "auto" '''model = AutoModelForCausalLM.from_pretrained( args.checkpoint_path, device_map=device_map, trust_remote_code=True, resume_download=True, ).eval()''' from peft import AutoPeftModelForCausalLM model = AutoPeftModelForCausalLM.from_pretrained( f'C:\lkp\LLM\qwen1.8B\Qwen\output_qwen', # path to the output directory device_map="auto", trust_remote_code=True ).eval() config = GenerationConfig.from_pretrained( args.checkpoint_path, trust_remote_code=True, resume_download=True, ) return model, tokenizer, config
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.合并源模型,注意:非量化后的lora微调,能合并。量化后的lora微调,不能合并,本文的模型不能合并;使用Q-lora,不能合并。
参照之前微调的文章。
3、复杂微调需要更改更多参数
以上只是最简单的微调,5轮几十条数据,只能把chat.json中的你是谁的问题改过来,后面的答案还会和原数据不完全一致,只是初步尝试。
复杂微调以后再介绍,可以学习firefly做法。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/290774
推荐阅读
相关标签

