
- 1HarmonyOS应用开发者基础认证考试(98分答案)
- 2IDS(入侵检测系统)简介
- 3阿里巴巴最新的SpringCloud面试题是如何让我“颜面扫地”的?_springcloudalibaba面试题
- 4检验两组数据是否显著差异_SPSS自动完成卡方分割的两两比较检验
- 5win10不能被远程连接解决方案(开启远程桌面,关闭防火墙仍不能被远程)_win10防火墙关闭后sqlserver数据库引擎远程连接不上
- 6C# 字符【包含汉字】常用转码_c#中文转码
- 7[Android]手把手带你写个权限请求工具_android requireactivity
- 8IDEA连接不上SVN,一直弹出authentication required_idea svn没有连接时一直提醒
- 9C#将字符转换成utf8编码 GB321编码转换_c# 字符串转utf8
- 10IDEA开发工具的安装及使用,设置常用快捷键提升开发效率
NLP系列——(3)特征选择_pmi点互信息算法特征选择
赞
踩
任务描述:Task3 特征选择
TF-IDF原理以及利用其进行特征筛选
互信息的原理以及利用其进行特征筛选
一、TF-IDF
1.1 背景
文本向量化特征的不足
在将文本分词并向量化后,我们可以得到词汇表中每个词在各个文本中形成的词向量,比如在文本挖掘预处理之向量化与Hash Trick 这篇文章中,我们将下面4个短文本做了词频统计:
corpus=[“I come to China to travel”,
“This is a car polupar in China”,
"I love tea and Apple ",
“The work is to write some papers in science”]
不考虑停用词,处理后得到的词向量如下:
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
[0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
[1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
如果我们直接将统计词频后的19维特征做为文本分类的输入,会发现有一些问题。比如第一个文本,我们发现"come","China"和“Travel”各出现1次,而“to“出现了两次。似乎看起来这个文本与”to“这个特征更关系紧密。但是实际上”to“是一个非常普遍的词,几乎所有的文本都会用到,因此虽然它的词频为2,但是重要性却比词频为1的"China"和“Travel”要低的多。如果我们的向量化特征仅仅用词频表示就无法反应这一点。因此我们需要进一步的预处理来反应文本的这个特征,而这个预处理就是TF-IDF。
-
每一个文档的关键词(或主题词)包括哪些?
-
给定一个(或一组)关键词,与这个(或组)词最相关的文档是哪一个?
-
给定一个文档,哪个(或哪些)文档与它具有最大的相似度呢?
回答上述三个问题的关键是:对于一个给定的词和一个给定的文档,定义一个可以用来衡量该词对该文档相关性(或重要性)的指标。那么,如何定义这样的一个指标呢?
词频-逆文档频率(Term Frequency - Inverse Document Frequency,TF-IDF)技术,它是一种用于资讯检索与文本挖掘的常用加权技术,可以用来评估一个词对于一个文档集或语料库中某个文档的重要程度。
1.2 TF-IDF概述
参考
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----“的”、“是”、“在”----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、“蜜蜂”、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,“蜜蜂"和"养殖"的重要程度要大于"中国”,也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词(“的”、“是”、“在”)给予最小的权重,较常见的词(“中国”)给予较小的权重,较少见的词(“蜜蜂”、“养殖”)给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低。
那该如何计算呢?
一、计算词频

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

二、计算逆文档频率
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
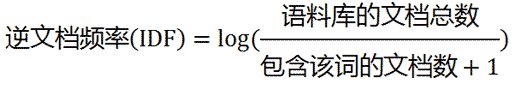
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
三、计算TF-IDF
T
F
−
I
D
F
(
x
)
=
T
F
(
x
)
∗
I
D
F
(
x
)
TF-IDF(x)=TF(x)*IDF(x)
TF−IDF(x)=TF(x)∗IDF(x)
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
1.3 TF-TIDF的实现
1.3.1 用gensim库来计算tfidf值
### 首先来看我们的语料库
corpus = [
'this is the first document',
'this is the second second document',
'and the third one',
'is this the first document'
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
接下来看我们的处理过程
####1)把语料库做一个分词的处理 ###[输入]: word_list = [] for i in range(len(corpus)): word_list.append(corpus[i].split(' ')) print(word_list) ###[输出]: [['this', 'is', 'the', 'first', 'document'], ['this', 'is', 'the', 'second', 'second', 'document'], ['and', 'the', 'third', 'one'], ['is', 'this', 'the', 'first', 'document']] ### 2)得到每个词的id值及词频 ###[输入]: from gensim import corpora # 赋给语料库中每个词(不重复的词)一个整数id dictionary = corpora.Dictionary(word_list) new_corpus = [dictionary.doc2bow(text) for text in word_list] print(new_corpus) # 元组中第一个元素是词语在词典中对应的id,第二个元素是词语在文档中出现的次数 ###[输出]: [[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)], [(0, 1), (2, 1), (3, 1), (4, 1), (5, 2)], [(3, 1), (6, 1), (7, 1), (8, 1)], [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)]] ### [输入]: # 通过下面的方法可以看到语料库中每个词对应的id print(dictionary.token2id) [输出]: {'document': 0, 'first': 1, 'is': 2, 'the': 3, 'this': 4, 'second': 5, 'and': 6, 'one': 7, 'third': 8} ### 3)训练gensim模型并且保存它以便后面的使用 ###[输入]: # 训练模型并保存 from gensim import models tfidf = models.TfidfModel(new_corpus) tfidf.save("my_model.tfidf") # 载入模型 tfidf = models.TfidfModel.load("my_model.tfidf") # 使用这个训练好的模型得到单词的tfidf值 tfidf_vec = [] for i in range(len(corpus)): string = corpus[i] string_bow = dictionary.doc2bow(string.lower().split()) string_tfidf = tfidf[string_bow] tfidf_vec.append(string_tfidf) print(tfidf_vec) ###[输出]: [[(0, 0.33699829595119235), (1, 0.8119707171924228), (2, 0.33699829595119235), (4, 0.33699829595119235)], [(0, 0.10212329019650272), (2, 0.10212329019650272), (4, 0.10212329019650272), (5, 0.9842319344536239)], [(6, 0.5773502691896258), (7, 0.5773502691896258), (8, 0.5773502691896258)], [(0, 0.33699829595119235), (1, 0.8119707171924228), (2, 0.33699829595119235), (4, 0.33699829595119235)]]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
再测试一下
#[输入]:
# 我们随便拿几个单词来测试
string = 'the i first second name'
string_bow = dictionary.doc2bow(string.lower().split())
string_tfidf = tfidf[string_bow]
print(string_tfidf)
#[输出]:
[(1, 0.4472135954999579), (5, 0.8944271909999159)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结论
- gensim训练出来的tf-idf值左边是词的id,右边是词的tfidf值
- gensim有自动去除停用词的功能,比如the
- gensim会自动去除单个字母,比如i
- gensim会去除没有被训练到的词,比如name
- 所以通过gensim并不能计算每个单词的tfidf值
1.3.2 用sklearn库来计算tfidf值
语料库保持不变
处理过程如下:
#[输入]: from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vec = TfidfVectorizer() tfidf_matrix = tfidf_vec.fit_transform(corpus) # 得到语料库所有不重复的词 print(tfidf_vec.get_feature_names()) # 得到每个单词对应的id值 print(tfidf_vec.vocabulary_) # 得到每个句子所对应的向量 # 向量里数字的顺序是按照词语的id顺序来的 print(tfidf_matrix.toarray()) #[输出]: ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'] {'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4} [[0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674] [0. 0.27230147 0. 0.27230147 0. 0.85322574 0.22262429 0. 0.27230147] [0.55280532 0. 0. 0. 0.55280532 0. 0.28847675 0.55280532 0. ] [0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.3.3 用python手动实现tiidf的计算
这里的处理过程如下:
## 1 对语料进行分词 #[输入]: word_list = [] for i in range(len(corpus)): word_list.append(corpus[i].split(' ')) print(word_list) #[输出]: [['this', 'is', 'the', 'first', 'document'], ['this', 'is', 'the', 'second', 'second', 'document'], ['and', 'the', 'third', 'one'], ['is', 'this', 'the', 'first', 'document']] ## 2 统计词频 #[输入]: countlist = [] for i in range(len(word_list)): count = Counter(word_list[i]) countlist.append(count) countlist #[输出]: [Counter({'document': 1, 'first': 1, 'is': 1, 'the': 1, 'this': 1}), Counter({'document': 1, 'is': 1, 'second': 2, 'the': 1, 'this': 1}), Counter({'and': 1, 'one': 1, 'the': 1, 'third': 1}), Counter({'document': 1, 'first': 1, 'is': 1, 'the': 1, 'this': 1})] ## 3 定义tfidf公式 # word可以通过count得到,count可以通过countlist得到 # count[word]可以得到每个单词的词频, sum(count.values())得到整个句子的单词总数 def tf(word, count): return count[word] / sum(count.values()) # 统计的是含有该单词的句子数 def n_containing(word, count_list): return sum(1 for count in count_list if word in count) # len(count_list)是指句子的总数,n_containing(word, count_list)是指含有该单词的句子的总数,加1是为了防止分母为0 def idf(word, count_list): return math.log(len(count_list) / (1 + n_containing(word, count_list))) # 将tf和idf相乘 def tfidf(word, count, count_list): return tf(word, count) * idf(word, count_list) ## 4 计算每个词的tfidf值 #[输入]: import math for i, count in enumerate(countlist): print("Top words in document {}".format(i + 1)) scores = {word: tfidf(word, count, countlist) for word in count} sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True) for word, score in sorted_words[:]: print("\tWord: {}, TF-IDF: {}".format(word, round(score, 5))) #[输出]: Top words in document 1 Word: first, TF-IDF: 0.05754 Word: this, TF-IDF: 0.0 Word: is, TF-IDF: 0.0 Word: document, TF-IDF: 0.0 Word: the, TF-IDF: -0.04463 Top words in document 2 Word: second, TF-IDF: 0.23105 Word: this, TF-IDF: 0.0 Word: is, TF-IDF: 0.0 Word: document, TF-IDF: 0.0 Word: the, TF-IDF: -0.03719 Top words in document 3 Word: and, TF-IDF: 0.17329 Word: third, TF-IDF: 0.17329 Word: one, TF-IDF: 0.17329 Word: the, TF-IDF: -0.05579 Top words in document 4 Word: first, TF-IDF: 0.05754 Word: is, TF-IDF: 0.0 Word: this, TF-IDF: 0.0 Word: document, TF-IDF: 0.0 Word: the, TF-IDF: -0.04463
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
二、互信息
2.1 点互信息PMI
机器学习相关文献里面,经常会用到点互信息PMI(Pointwise Mutual Information)这个指标来衡量两个事物之间的相关性(比如两个词)。公式如下:
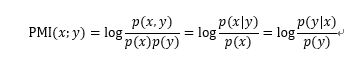
在概率论中,我们知道,如果x跟y不相关,则p(x,y)=p(x)p(y)。二者相关性越大,则p(x, y)就相比于p(x)p(y)越大。用后面的式子可能更
好理解,在y出现的情况下x出现的条件概率p(x|y)除以x本身出现的概率p(x),自然就表示x跟y的相关程度。
举个自然语言处理中的例子来说,我们想衡量like这个词的极性(正向情感还是负向情感)。我们可以预先挑选一些正向情感的词,
比如good。然后我们算like跟good的PMI。
2.2 互信息MI
互信息即:
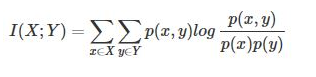
其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。所谓的随机变量,即随机试验结果的量的表示,可以简单理解为按照一个概率分布进行取值的变量,比如随机抽查的一个人的身高就是一个随机变量。
可以看出,互信息其实就是对X和Y的所有可能的取值情况的点互信息PMI的加权和。因此,点互信息这个名字还是很形象的。
2.3 对特征矩阵使用互信息进行特征筛选
sklearn.metrics.mutual_info_score
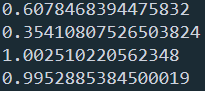
from sklearn import datasets from sklearn import metrics as mr iris = datasets.load_iris() x = iris.data label = iris.target x0 = x[:, 0] x1 = x[:, 1] x2 = x[:, 2] x3 = x[:, 3] # 计算各特征与label的互信息 print(mr.mutual_info_score(x0, label)) print(mr.mutual_info_score(x1, label)) print(mr.mutual_info_score(x2, label)) print(mr.mutual_info_score(x3, label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
sklearn.feature_selection.mutual_info_classif
from sklearn import datasets
from sklearn.feature_selection import mutual_info_classif
iris = datasets.load_iris()
x = iris.data
label = iris.target
mutual_info = mutual_info_classif(x, label, discrete_features= False)
print(mutual_info)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
[0.50224304,0.24818039,0.99119509,1.00228772]
- 1

