
- 1RabbitMQ开通STOMP通道,为websocket整合rabbitmq做准备_rabbitmq管理后台开启stomp
- 2【EI会议征稿通知】2024计算建模与应用数学国际学术会议暨中俄微分方程及其应用学术会议(CMAM 2024 & DEIA)_计算数学数学建模与动力学国际会议
- 3关于ik分词器,修改自定义返回tokens的type值实现_ik 分词后的type有哪些
- 4鸿蒙笔记--装饰器
- 5SQLServer经典SQL大全_sqlserver常用sql
- 6Linux 使用技巧及示例
- 7springboot+webSocket对接chatgpt
- 8Flink-DataWorks第四部分:数据同步(第60天)_数据同步功能配置说明
- 9文件上传-.htaccess利用
- 10git error 解决方案_git error desktop-48flbtc
【深度学习】位置编码
赞
踩
前言
位置编码(Positional Encoding)是在使用Transformer等自回归模型处理序列数据(如自然语言)时,为输入序列中的每个位置添加额外信息以体现其在序列中的相对或绝对位置的方法。
1.什么是位置编码
位置编码是对一个句子中词汇的位置信息做编码的过程。因为transformer的attention与lstm、rnn这种天然的流式结构不同,为了更高效地处理序列信息,在做并行计算时是没有位置信息的。也就是transformer的attention结构丢失了词汇的位置信息。
如果不增加对位置信息的编码,则对于模型来说,乱序的词汇和正序的词汇没有分别。也即“今天 天气 真 好”和 "天气 真 今天 好 "没有区别。在transformer的self-attention模块中,序列的输入输出如下:
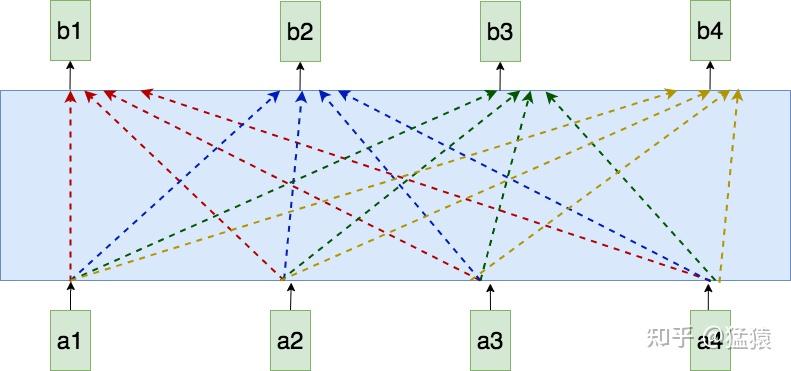
在self-attention模型中,输入是一整排的tokens,对于人来说,我们很容易知道tokens的位置信息,比如:
(1)绝对位置信息。a1是第一个token,a2是第二个token......
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位......
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置....
但是这些对于self-attention来说,是无法分辩的信息,因为self-attention的运算是无向的。所以要找出一种编码,将每个token的位置信息表达出来,并且让模型接收。
2.构造位置编码的方法
2.1 用整型值标记位置
一种自然而然的想法是,给第一个token标记1,给第二个token标记2...,以此类推。
这种方法产生了以下几个主要问题:
(1)模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
(2)模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
2.2 用[0,1]范围标记位置
为了解决整型值带来的问题,可以考虑将位置值的范围限制在[0, 1]之内,其中,0表示第一个token,1表示最后一个token。比如有3个token,那么位置信息就表示成[0, 0.5, 1];若有四个token,位置信息就表示成[0, 0.33, 0.69, 1]。
但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5;在序列长度为4时,token间的相对距离就变为0.33。
因此,我们需要这样一种位置表示方式,满足于:
(1)它能用来表示一个token在序列中的绝对位置
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
(3)可以用来表示模型在训练过程中从来没有看到过的句子长度。
2.3 用二进制向量标记位置
考虑到位置信息作用在input embedding上,因此比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。这时我们就很容易想到二进制编码。如下图,假设d_model = 3,那么我们的位置向量可以表示成:
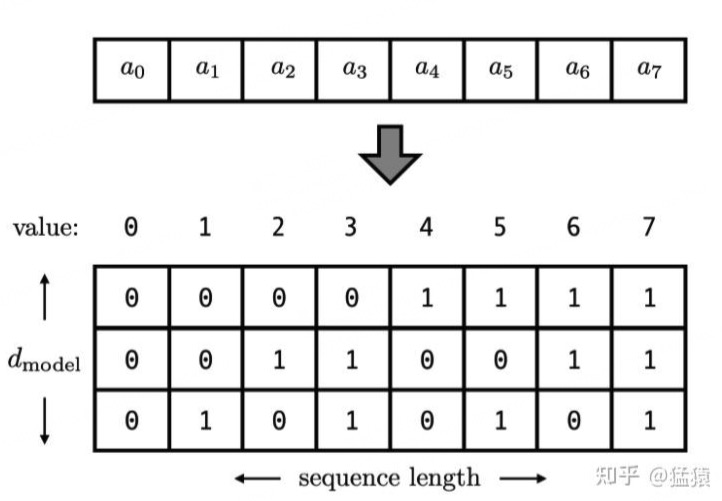
这下所有的值都是有界的(位于0,1之间),且transformer中的d_model本来就足够大,基本可以把我们要的每一个位置都编码出来了。
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的。假设d_model = 2,我们有4个位置需要编码,这四个位置向量可以表示成[0,0],[0,1],[1,0],[1,1]。我们把它的位置向量空间做出来:
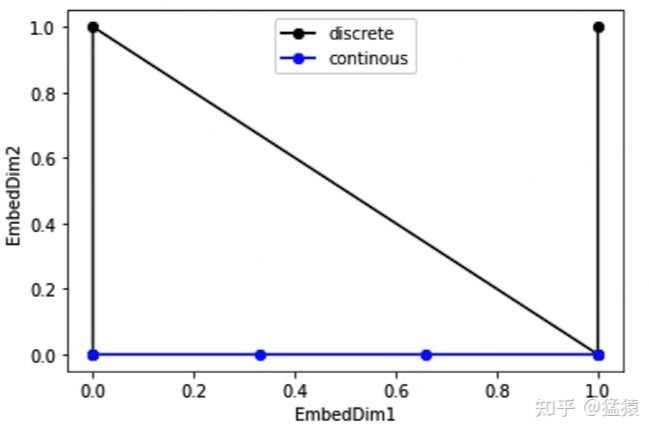
如果我们能把离散空间(黑色的线)转换到连续空间(蓝色的线),那么我们就能解决位置距离不连续的问题。同时,我们不仅能用位置向量表示整型,我们还可以用位置向量来表示浮点型。
2.4 用周期函数(sin)来表示位置
回想一下,现在我们需要一个有界又连续的函数,最简单的,正弦函数sin就可以满足这一点。我们可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量可以表示为:
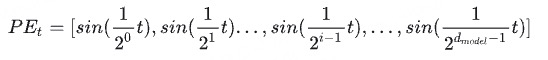

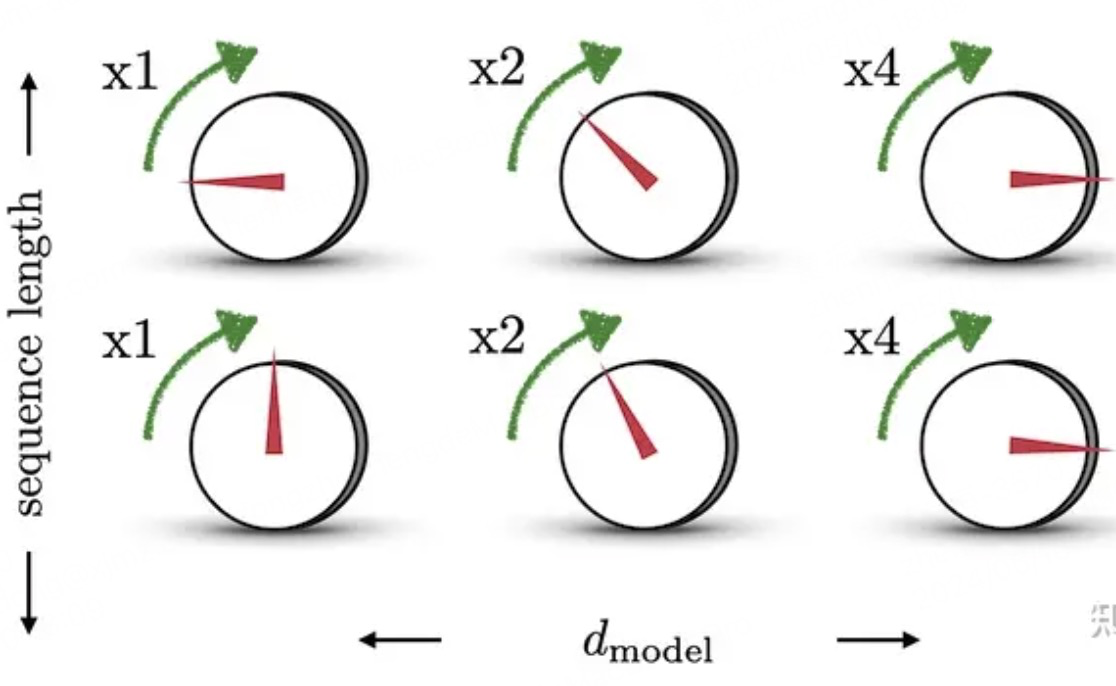
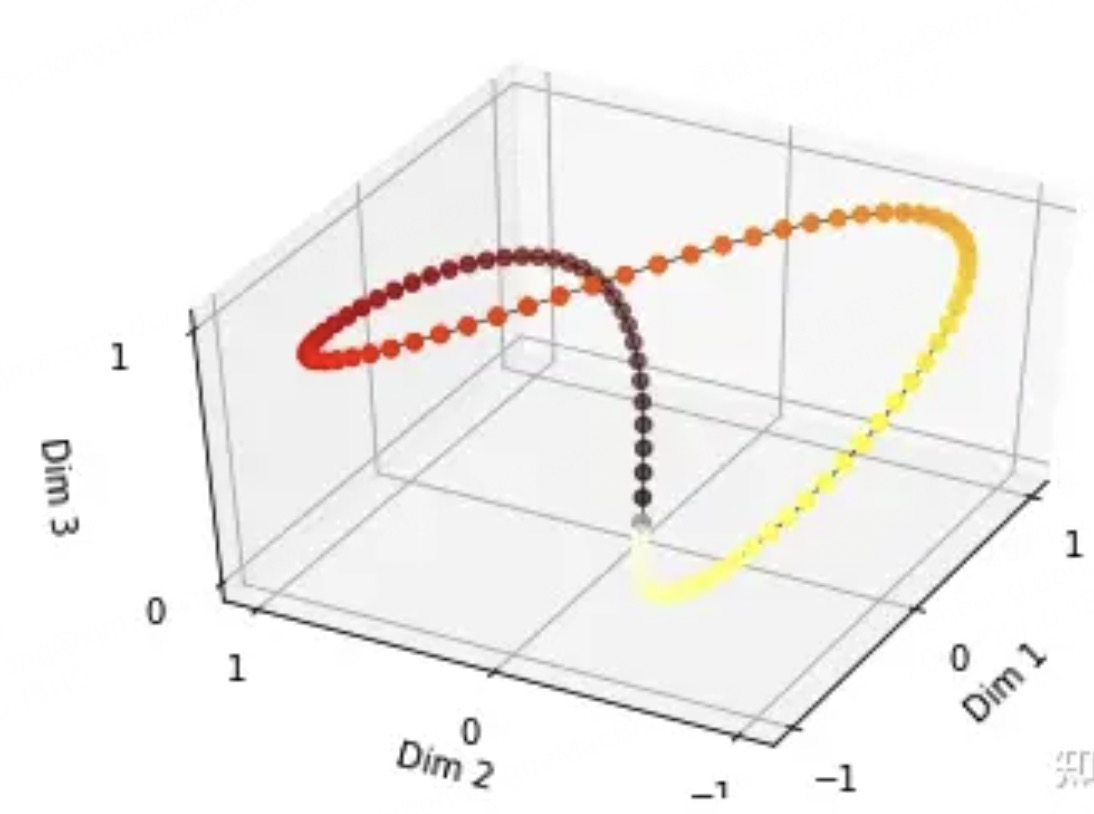
由于sin是周期函数,因此从纵向来看,如果函数的频率偏大,引起波长偏短,则不同t下的位置向量可能出现重合的情况。比如在下图中(d_model = 3),图中的点表示每个token的位置向量,颜色越深,token的位置越往后,在频率偏大的情况下,位置响亮点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:
为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在transformer的论文中,采用了 110000
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

