
热门标签
热门文章
- 1Modbus转BACnet IP网关与Kepware携手玩转智能楼宇监控_kepserver软件与智慧网关盒
- 2Git 安全远程访问:SSH 密钥对生成、添加和连接步骤解析
- 3【Python】数据加密解密技术_python数据的简单加密、解密。有一加密方法,其加密原理是 对于一个报文中出现_数据简单加密解密:有一简单加密方法,原理是:对于一个报文中出现的任何字母用其后(
- 4FPGA中应用LVDS信号_fpga lvds
- 5本地docker安装使用_docker本地安装
- 6这家网络公司开始聘用黑客?_朝鲜 网络
- 7SpringBoot依赖之Quartz Scheduler定时调度器使用MySQL存储Job
- 8OpenMV串口通讯
- 9C++ override及虚函数的讲解_c++ override和虚函数
- 10SysTick—系统定时器_systick寄存器
当前位置: article > 正文
Python爬虫实战,DecryptLogin模块,Python模拟登录实现载B站指定UP主的所有视频_python 登录b站下载4k视频
作者:小舞很执着 | 2024-08-01 06:53:55
赞
踩
python 登录b站下载4k视频
前言
下载B站上指定的UP主所上传的所有视频。废话不多说,让我们愉快地开始吧~
开发工具
** Python版本:**3.6.4
** 相关模块:**
DecryptLogin模块;
argparse模块;
以及一些python教程自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
原理简介
这里简单介绍一下原理吧,因为B站只有在用户登录状态下才能下载1080P的视频。所以我们首先要利用我开源的DecryptLogin库模拟登录B站(毕竟低画质的视频看着不舒服),这个很简单,几行代码就搞定了:
- from DecryptLogin import login
- _, session = login.Login().bilibili(username, password)
接下来就是老生常谈的抓包了,进入某个UP主的主页:
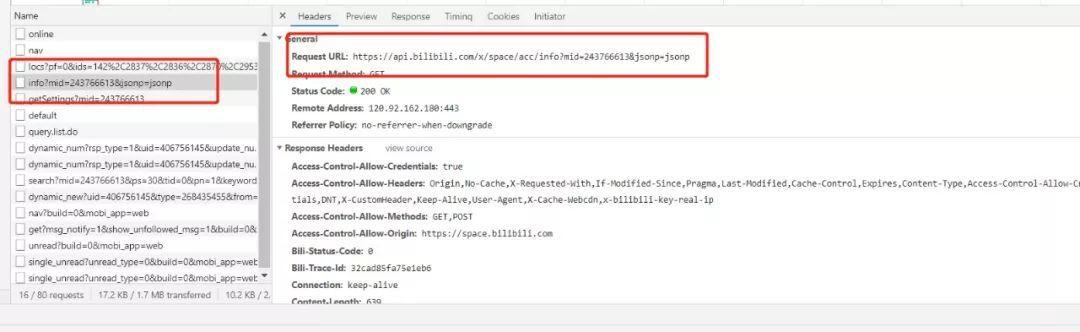
首先我们来抓取UP主的基本信息(抓取UP主所有的视频时完全不需要这些信息,只是用来确定你输入的userid是否和你想抓取的用户一致用的),这个很简单,刷新一下发现:
几行代码就搞定了:
- '''根据userid获得该用户基本信息'''
- def __getUserInfo(self, userid):
- params = {'mid': userid, 'jsonp': 'jsonp'}
- res = self.session.get(self.user_info_url, params=params, headers=self.headers)
- res_json = res.json()
- user_info = {
- '用户名': res_json['data']['name'],
- '性别': res_json['data']['sex'],
- '个性签名': res_json['data']['sign'],
- '用户等级': res_json['data']['level'],
- '生日': res_json['data']['birthday']
- }
- return user_info
接下来就是下载该UP主的所有视频了,因为感觉搞起来可能比较费时间(年底了时间比较紧张T_T),所以就直接去you-get的源码里找了找有没有现成的API了,发现主要需要以下三个接口:
- 'https://space.bilibili.com/ajax/member/getSubmitVideos'
- 'https://api.bilibili.com/x/web-interface/view'
- 'https://api.bilibili.com/x/player/playurl'
第一,二个接口用来获取用户所有的视频的基本信息,根据这些信息然后再利用第三个接口来获得视频的下载链接,最后利用调用aria2c下载这些视频就OK了。具体而言,代码实现如下:
- '''下载目标用户的所有视频'''
- def __downloadVideos(self, userid):
- if not os.path.exists(userid):
- os.mkdir(userid)
- # 非会员用户只能下载到高清1080P
- quality = [('16', '流畅 360P'),
- ('32', '清晰 480P'),
- ('64', '高清 720P'),
- ('74', '高清 720P60'),
- ('80', '高清 1080P'),
- ('112', '高清 1080P+'),
- ('116', '高清 1080P60')][-3]
- # 获得用户的视频基本信息
- video_info = {'aids': [], 'cid_parts': [], 'titles': [], 'links': [], 'down_flags': []}
- params = {'mid': userid, 'pagesize': 30, 'tid': 0, 'page': 1, 'order': 'pubdate'}
- while True:
- res = self.session.get(self.submit_videos_url, headers=self.headers, params=params)
- res_json = res.json()
- for item in res_json['data']['vlist']:
- video_info['aids'].append(item['aid'])
- if len(video_info['aids']) < int(res_json['data']['count']):
- params['page'] += 1
- else:
- break
- for aid in video_info['aids']:
- params = {'aid': aid}
- res = self.session.get(self.view_url, headers=self.headers, params=params)
- cid_part = []
- for page in res.json()['data']['pages']:
- cid_part.append([page['cid'], page['part']])
- video_info['cid_parts'].append(cid_part)
- title = res.json()['data']['title']
- title = re.sub(r"[‘’\/\\\:\*\?\"\<\>\|\s']", ' ', title)
- video_info['titles'].append(title)
- print('共获取到用户ID<%s>的<%d>个视频...' % (userid, len(video_info['titles'])))
- for idx in range(len(video_info['titles'])):
- aid = video_info['aids'][idx]
- cid_part = video_info['cid_parts'][idx]
- link = []
- down_flag = False
- for cid, part in cid_part:
- params = {'avid': aid, 'cid': cid, 'qn': quality, 'otype': 'json', 'fnver': 0, 'fnval': 16}
- res = self.session.get(self.video_player_url, params=params, headers=self.headers)
- res_json = res.json()
- if 'dash' in res_json['data']:
- down_flag = True
- v, a = res_json['data']['dash']['video'][0], res_json['data']['dash']['audio'][0]
- link_v = [v['baseUrl']]
- link_a = [a['baseUrl']]
- if v['backup_url']:
- for item in v['backup_url']:
- link_v.append(item)
- if a['backup_url']:
- for item in a['backup_url']:
- link_a.append(item)
- link = [link_v, link_a]
- else:
- link = [res_json['data']['durl'][-1]['url']]
- if res_json['data']['durl'][-1]['backup_url']:
- for item in res_json['data']['durl'][-1]['backup_url']:
- link.append(item)
- video_info['links'].append(link)
- video_info['down_flags'].append(down_flag)
- # 开始下载
- out_pipe_quiet = subprocess.PIPE
- out_pipe = None
- aria2c_path = os.path.join(os.getcwd(), 'tools/aria2c')
- ffmpeg_path = os.path.join(os.getcwd(), 'tools/ffmpeg')
- for idx in range(len(video_info['titles'])):
- title = video_info['titles'][idx]
- aid = video_info['aids'][idx]
- down_flag = video_info['down_flags'][idx]
- print('正在下载视频<%s>...' % title)
- if down_flag:
- link_v, link_a = video_info['links'][idx]
- # --视频
- url = '"{}"'.format('" "'.join(link_v))
- command = '{} -c -k 1M -x {} -d "{}" -o "{}" --referer="https://www.bilibili.com/video/av{}" {} {}'
- command = command.format(aria2c_path, len(link_v), userid, title+'.flv', aid, "", url)
- process = subprocess.Popen(command, stdout=out_pipe, stderr=out_pipe, shell=True)
- process.wait()
- # --音频
- url = '"{}"'.format('" "'.join(link_a))
- command = '{} -c -k 1M -x {} -d "{}" -o "{}" --referer="https://www.bilibili.com/video/av{}" {} {}'
- command = command.format(aria2c_path, len(link_v), userid, title+'.aac', aid, "", url)
- process = subprocess.Popen(command, stdout=out_pipe, stderr=out_pipe, shell=True)
- process.wait()
- # --合并
- command = '{} -i "{}" -i "{}" -c copy -f mp4 -y "{}"'
- command = command.format(ffmpeg_path, os.path.join(userid, title+'.flv'), os.path.join(userid, title+'.aac'), os.path.join(userid, title+'.mp4'))
- process = subprocess.Popen(command, stdout=out_pipe, stderr=out_pipe_quiet, shell=True)
- process.wait()
- os.remove(os.path.join(userid, title+'.flv'))
- os.remove(os.path.join(userid, title+'.aac'))
- else:
- link = video_info['links'][idx]
- url = '"{}"'.format('" "'.join(link))
- command = '{} -c -k 1M -x {} -d "{}" -o "{}" --referer="https://www.bilibili.com/video/av{}" {} {}'
- command = command.format(aria2c_path, len(link), userid, title+'.flv', aid, "", url)
- process = subprocess.Popen(command, stdout=out_pipe, stderr=out_pipe, shell=True)
- process.wait()
- os.rename(os.path.join(userid, title+'.flv'), os.path.join(userid, title+'.mp4'))
- print('所有视频下载完成, 该用户所有视频保存在<%s>文件夹中...' % (userid))

文章到这里就结束了,感谢你的观看,下篇文章分享网易云个人歌单下载器
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/912820
推荐阅读
- b站视频下载 ...
赞
踩
相关标签

