
- 1推荐8款好用的Python库,助你成为编程大师!_好用的python库推荐
- 2什么是互联网泡沫_互联网泡沫什么意思
- 3华为云ECS服务器中通过docker搭建nacos server_华为云ecs如何配置nacos
- 4Django-simple-captcha 验证码插件_django使用simpleui的登陆界面如何增加短信验证
- 5Cloudflare配置CDN+SSL+代理_cloudflare ssl
- 6ZIP技巧:如何解压Zip分卷压缩文件
- 7Go语言Web框架Gin(Day7)_7天gin框架
- 8SEO工具MIPCMS搜索引擎提交器 v1.1
- 9【ML】模型指标与评估_ml 模型评估java
- 10Flutter框架分析(一)--架构总览(1)
LLM-01 大模型 本地部署运行 ChatGLM2-6B-INT4(6GB) 简单上手 环境配置 单机单卡多卡 2070Super8GBx2 打怪升级!_微调后的大模型本地部署运行
赞
踩
写在前面
其他显卡环境也可以!但是最少要有8GB的显存,不然很容易爆。
如果有多显卡的话,单机多卡也是很好的方案!!!
背景介绍
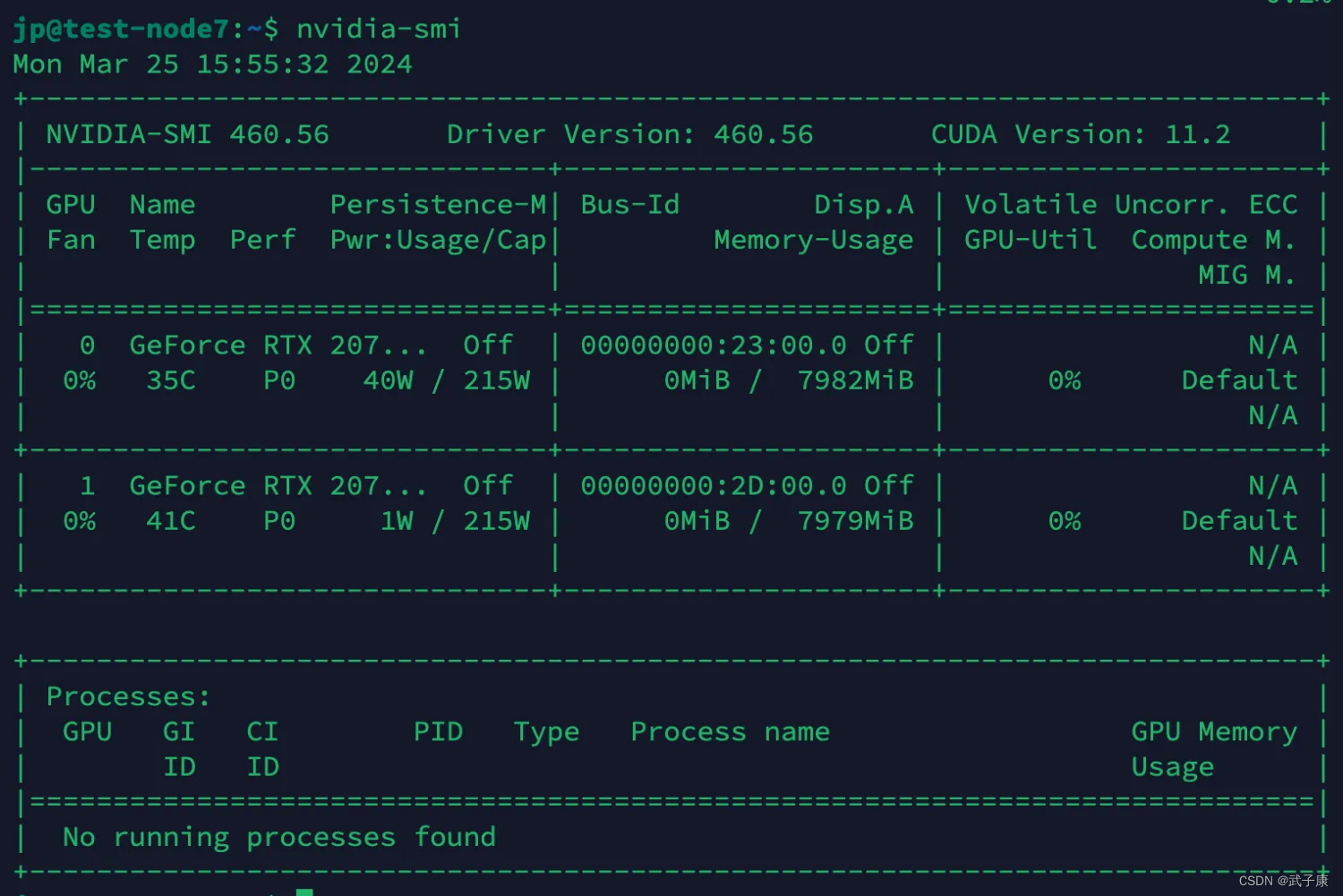
目前借到一台算法组的服务器,我们可以查看一下目前显卡的情况
nvidia-smi
- 1
(后续已经对CUDA等进行了升级,可看我的其他文章,有升级的详细过程)
项目地址
# 需要克隆项目
https://github.com/THUDM/ChatGLM2-6B
# 模型下载(如果你没有科学,麻烦一点需要手动下载)
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b-int4&mode=list
# 模型下载(如果可以科学,官方下载的体验是比较舒适的)
https://huggingface.co/THUDM/chatglm2-6b-int4
- 1
- 2
- 3
- 4
- 5
- 6
我们需要对项目进行克隆,同时需要下载对应的模型,如果你有科学,可以忽略模型的下载,因为你启动项目的时候它会自己下载。
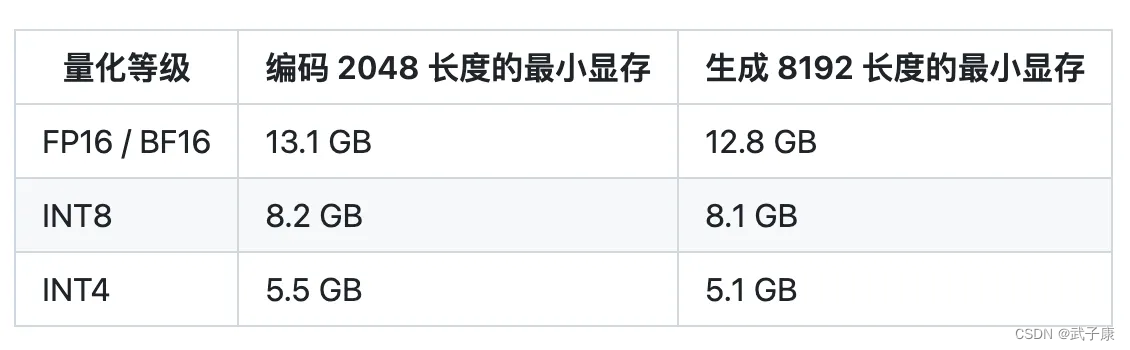
配置要求
根据官方的介绍,可以看到对应的显卡要求,根据我的情况(2070Super 8GB * 2),我这里选择下载了 INT4的模型。
环境配置
由于很多不同的项目队python版本的要求不同,同时对版本的要求也不同,所以你需要配置一个独立的环境。
这里你可以选择 Conda,也可以选择pyenv,或者docker。我选的方案是:pyenv
安装 Pyenv
项目地址是:Pyenv GitHhub
# 自动完成安装
curl https://pyenv.run | bash
- 1
- 2
安装完成后,需要配置一下环境变量。
如果你是Bash
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
- 1
- 2
- 3
如果你是ZSH
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
- 1
- 2
- 3
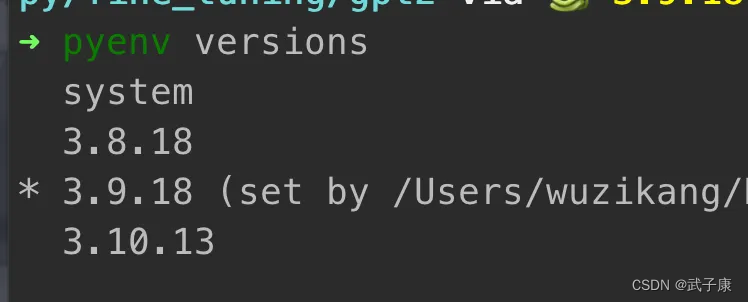
测试 Pyenv
# 查看当前系统中的Python情况
pyenv versions
- 1
- 2
使用 Pyenv
# Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
你将看到类似于如下图的内容:(我这里是在MacBook上)
安装依赖
我们进入项目的目录,确保配好了上述的独立目录:
(使用Pyenv章节,这里保险起见,再放一次)
# Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
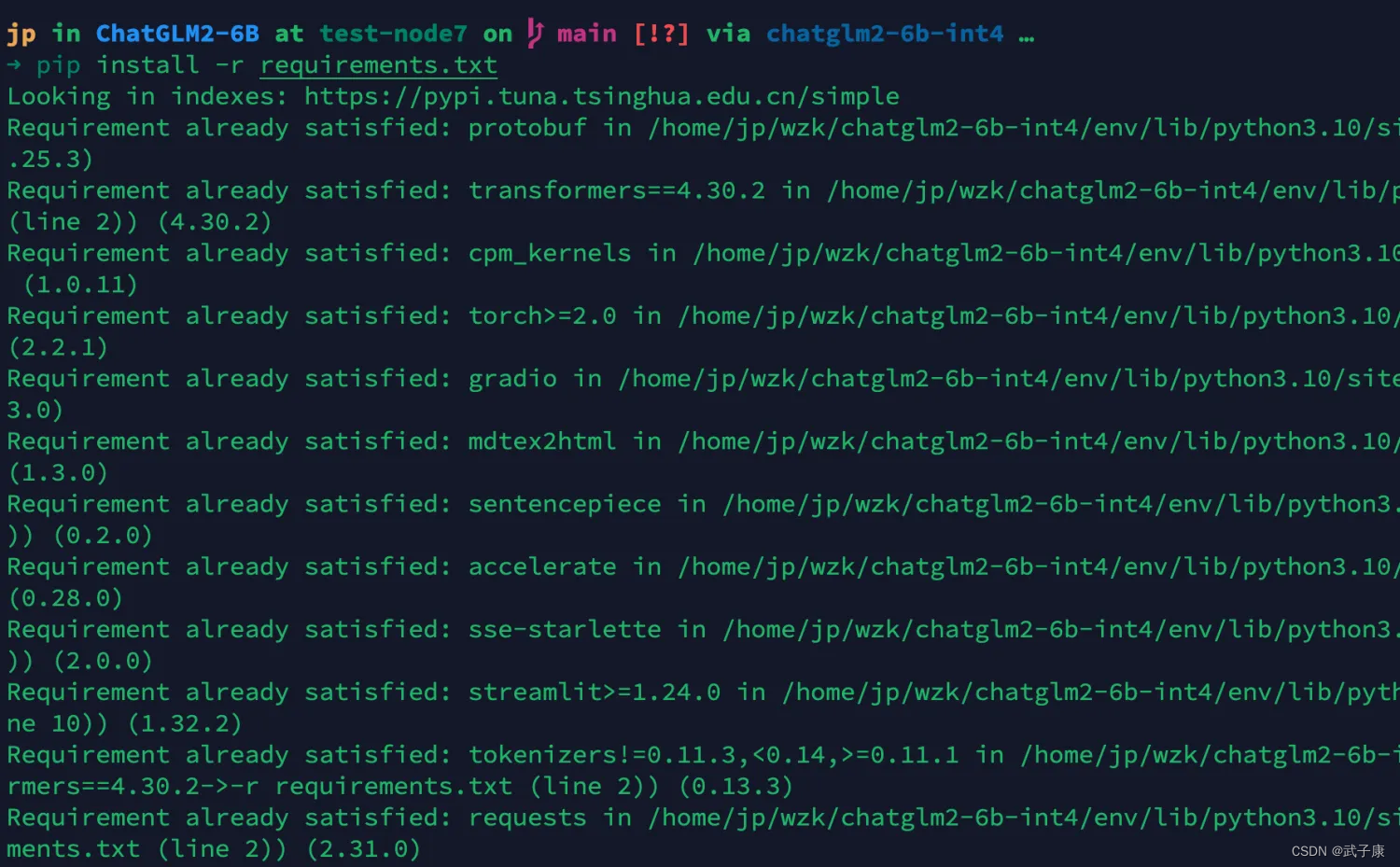
注意,这里是两个部分:(这是我服务器的配置,你也要搞清楚你的内容放置在哪里) 如下图:
- 项目文件夹 /home/jp/wzk/chatglm2-6b-int4/ChatGLM2-6B
- 模型文件夹 /home/jp/wzk/chatglm2-6b-int4/chatglm2-6b-int4
项目文件夹

模型文件夹

启动项目
在项目的目录下,我们利用现成的直接启动:web_demo.py
# 先打开看一眼
vim web_demo.py
- 1
- 2
model_path是你下载的模型文件夹(如果你不是手动下载的话,可以不改,这样的话会自动下载)
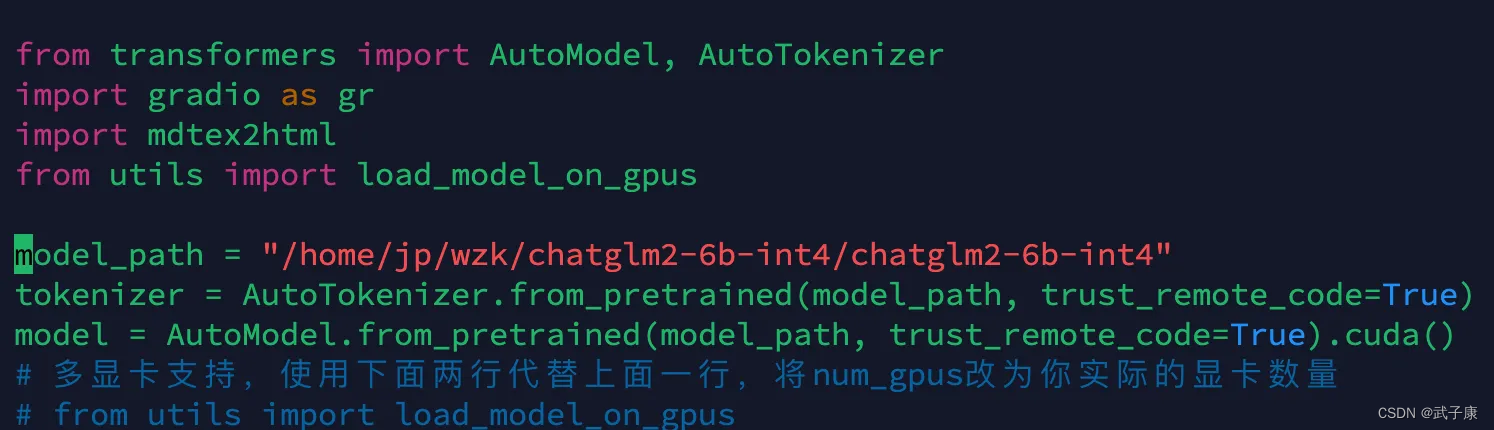
此时需要到最后一行,修改对外暴露服务
# 代码修改为这样
demo.queue().launch(server_name="0.0.0.0", server_port=7861, share=False, inbrowser=True)
- 1
- 2
使用Esc -> :wq!退出vim,运行该脚本
python web_demo.py
- 1
使用项目
完成上述的操作,稍等后看到:
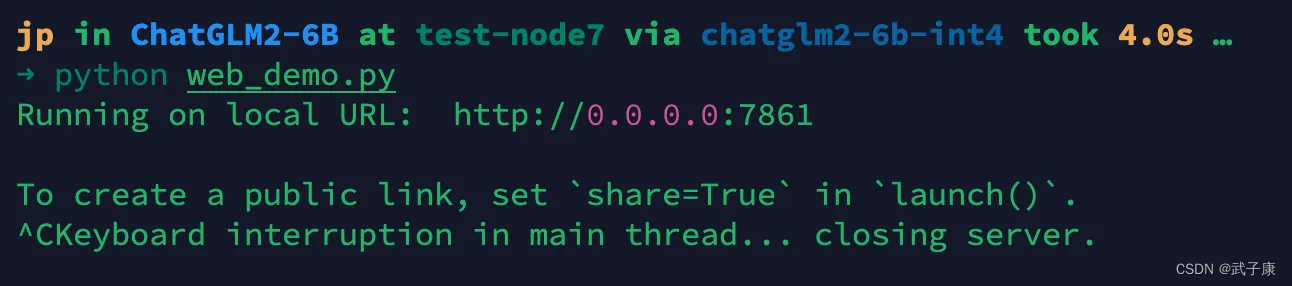
根据你的服务器IP和端口,访问即可。
多卡启动
由于单卡很容易爆 OOM,正好这里是 2 * 2070Super 8GB,我们简单的修改一下代码,就可以将模型分到两张显卡中。
官方给的方案是,通过accelerate库来启动。
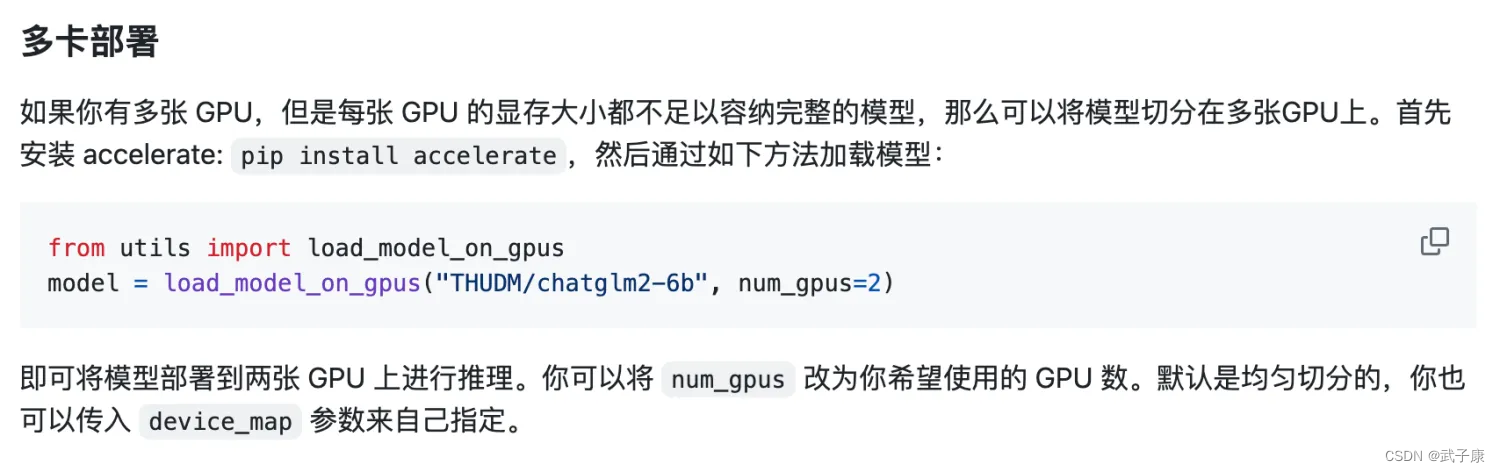
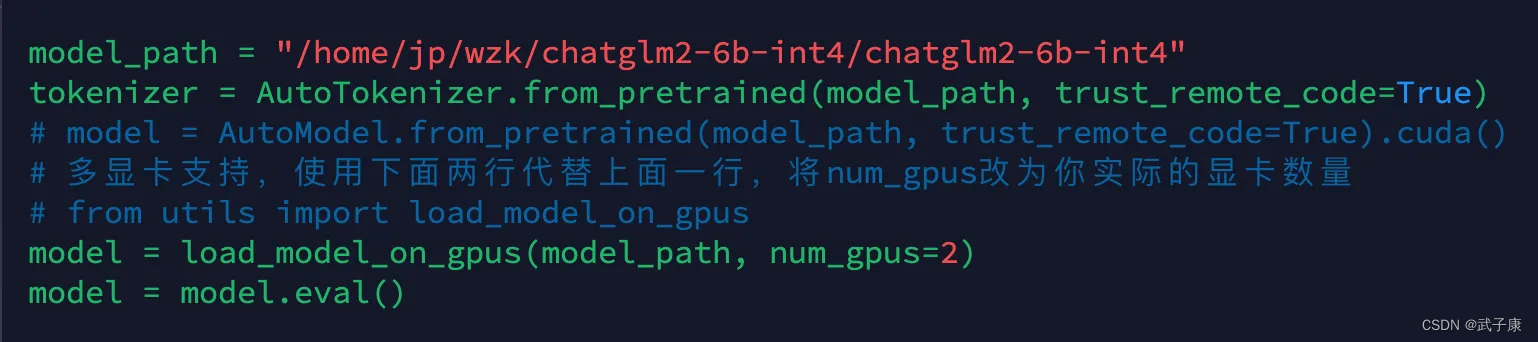
我们修改刚才的 web_demo.py,详细位置请看图:
# GPU 数量修改为2
model = load_model_on_gpus(model_path, num_gpus=2)
- 1
- 2
运行项目
python web_demo.py
- 1

