
- 1【机器学习和数据分析与可视化课程设计】基于天气预报的数据分析与可视化课程设计(Python实现)_机器学习课程设计
- 2智能车竞赛技术报告 | 智能车视觉 - 山东大学(威海) - 山魂五队_智能车比赛常用的视觉算法
- 3如何用OpenAI 接口开发聊天机器人_使用openai api完成聊天机器人开发
- 4STM32--SPI通信协议_stm32 spi模式1
- 5java使用openOffice将excel转为pdf_java 开源excel转pdf
- 6基于GJK算法空域冲突检测与消解的matlab实现_空战场管控中空域冲突检测
- 7python图像边缘检测_Python进行图片水平边缘检测prewitt算子法
- 8Java知识点学习(第8天)_一个对象从加载到jvm,再到被gc清除,都经历了什么过程
- 9RabbitMQ交换机详解_rabbitmq 交换机
- 10【Bert + BiLSTM + CRF】实现实体命名识别,后续封装Dataset,DataLoader,进行批次训练_bert+bilstm+crf
从AI 顶会AAAI 2024 洞察泛交通领域研究热点
赞
踩
AAAI 2024 泛交通领域论文整理
AAAI会议作为全球AI领域的顶级学术盛会,被中国计算机学会(CCF)评为A类会议。AAAI 2024的会议论文投稿量达到了历史新高,主赛道收到了12100篇投稿论文,9862篇论文经过严格评审后共有2342篇论文被录用,录用率达到23.75%。这一数据不仅反映了学术界对AAAI会议的高度重视,也显示了人工智能领域的蓬勃发展。

核心论文
1. NuScenes-QA: A Multi-Modal Visual Question Answering Benchmark for Autonomous Driving Scenario
NuScenes-QA:自动驾驶场景下的多模态视觉问答基准测试
作者:Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, Yu-Gang Jiang
机构:Academy for Engineering and Technology,Fudan University、Shanghai Key Lab of Intelligent Information Processing、School of Computer Science, Fudan University
摘要:文章介绍了一个在自动驾驶背景下的新视觉问答(VQA)任务,旨在基于街道视图线索回答自然语言问题。与传统的VQA任务相比,自动驾驶场景中的VQA呈现出更多挑战。首先,原始视觉数据是多模态的,包括由摄像头和激光雷达捕获的图像和点云。其次,数据是多帧的,因为它们是连续、实时获取的。第三,户外场景展示了移动的前景和静态的背景。现有的VQA基准测试未能充分解决这些复杂性。为了弥补这一差距,作者提出了NuScenes-QA,这是第一个针对自动驾驶场景的VQA基准测试,包括34K视觉场景和460K问答对。具体来说,作者利用现有的3D检测注释来生成场景图,并手动设计问题模板。随后,基于这些模板,文章中通过程序化方法生成了问答对。全面的统计数据证明了NuScenes-QA是一个具有多样化问题格式的平衡的大规模基准测试。在此基础上,作者开发了一系列基线模型,采用了先进的3D检测和VQA技术。作者的广泛实验突出了这一新任务带来的挑战。代码和数据集可在https://github.com/qiantianwen/NuScenes-QA获取。
关键词:视觉问答(VQA)、自动驾驶场景、多模态数据(图像和点云)、多帧数据、户外场景
NuScenes-QA基准测试、场景图、问题模板、程序化问答生成、基线模型、3D检测、VQA技术
文章获取网址:
https://arxiv.org/abs/2305.14836
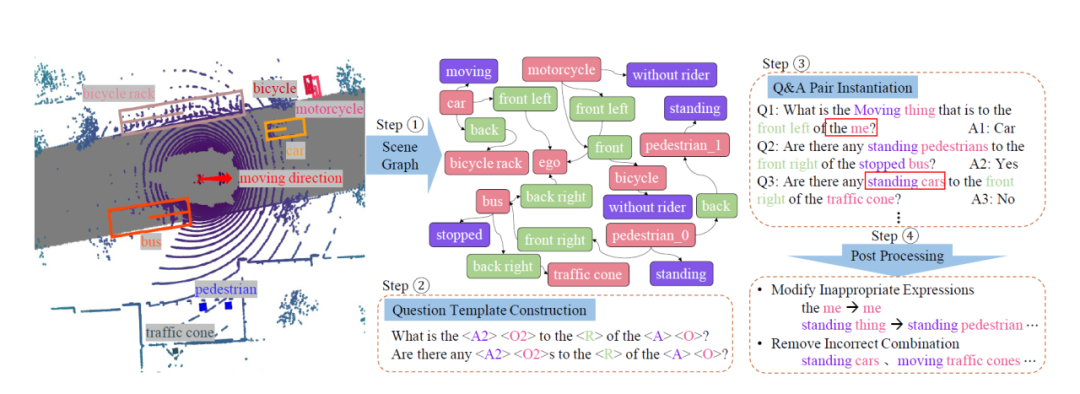
NuScenes-QA 的数据构建流程
2. SlowTrack: Increasing the Latency of Camera-based Perception in Autonomous Driving Using Adversarial Examples
SlowTrack:使用对抗性示例增加自动驾驶中基于相机的感知延迟
作者:Chen Ma, Ningfei Wang, Qi Alfred Chen, Chao Shen
机构:Xi’an Jiaotong University 、University of California, Irvine
摘要:在自动驾驶(AD)中,实时感知是负责检测周围物体以确保安全驾驶的关键组成部分。虽然现有研究广泛探讨了由于安全影响AD感知的完整性,但在可用性(实时性能)或延迟方面的关注有限。现有的基于延迟的攻击主要集中在目标检测上,即相机基础AD感知的一个组成部分,忽视了整个相机基础AD感知,这阻碍了他们实现有效的系统级效果,如车辆碰撞。在本文中,文章中提出了SlowTrack,这是一种新颖的框架,用于生成增加相机基础AD感知执行时间的对抗性攻击。文章中提出了一种新颖的两阶段攻击策略以及三种新的损失函数设计。文章中的评估在四个流行的相机基础AD感知管道上进行,结果表明SlowTrack在保持可比的不可见性水平的同时,显著优于现有的基于延迟的攻击。此外,文章中在百度Apollo,一个工业级的全栈AD系统,以及LGSVL,一个生产级AD模拟器上进行评估,比较SlowTrack和现有攻击的系统级效果。文章中的评估结果表明,系统运行效果显著提高,即SlowTrack的车辆碰撞率平均约为95%,而现有研究中只有约30%。its relevance in different scenarios.
关键词:自动驾驶、实时感知、延迟攻击、对抗性攻击、系统级效果
文章获取网址:
https://arxiv.org/abs/2312.09520

SlowTrack对抗性的展
3. BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning
BEVGPT:生成式预训练大模型,用于自动驾驶的预测、决策和规划
作者:Pengqin Wang, Meixin Zhu, Hongliang Lu, Hui Zhong, Xianda Chen, Shaojie Shen, Xuesong Wang, Yinhai Wang
机构:The Hong Kong University of Science and Technology、The Hong Kong University of Science and Technology (Guangzhou)、Tongji University、 University of Washington、Guangdong Provincial Key Lab of Integrated Communication, Sensing and Computation for Ubiquitous Internet of Things
摘要:预测、决策和运动规划对于自动驾驶至关重要。在大多数当代工作中,它们被视为单独的模块或结合到具有共享骨干但任务头分离的多任务学习范式中。然而,作者认为应该将它们整合到一个全面的框架中。尽管最近的几种方法遵循了这种方案,但它们受到复杂输入表示和冗余框架设计的影响。更重要的是,它们无法对未来的驾驶场景进行长期预测。为了解决这些问题,作者重新考虑了自动驾驶任务中每个模块的必要性,并仅将所需模块整合到一个极简的自动驾驶框架中。作者提出了BEVGPT,一个生成式预训练的大型模型,整合了驾驶场景预测、决策和运动规划。该模型以鸟瞰图(BEV)图像作为唯一的输入源,并基于周围交通场景做出驾驶决策。为了确保驾驶轨迹的可行性和平滑性,作者开发了一种基于优化的运动规划方法。作者在Lyft Level 5数据集上实例化BEVGPT,并使用Woven Planet L5Kit进行真实驾驶模拟。所提出框架的有效性和鲁棒性通过在100%的决策指标和66%的运动规划指标上超越先前方法得到了验证。此外,通过驾驶场景预测任务,展示了作者框架准确生成长期BEV图像的能力。这是第一个仅以BEV图像为输入的自动驾驶预测、决策和运动规划的生成式预训练大型模型。
关键词:自动驾驶、预测、决策、运动规划、BEVGPT、生成式预训练、多任务学习、长期预测
文章获取网址:
https://arxiv.org/abs/2310.10357

BEVGPT的两阶段训练流程
4. M-BEV: Masked BEV Perception for Robust Autonomous Driving
M-BEV: 遮蔽鸟瞰图感知—提高自动驾驶鲁棒性的新框架
作者:Siran Chen, Yue Ma, Yu Qiao, Yali Wang
机构:Shenzhen Institute of Advanced Technology, Chinese Academy of Science, Shenzhen, China
School of Artificial Intelligence, University of Chinese Academy of Science, Beijing, China
Shanghai Artificial Intelligence Laboratory, Shanghai, China
Tsinghua Shenzhen International Graduate School, Tsinghua University, Shenzhen, China
摘要:三维感知是自动驾驶中的一个关键问题。近期,由于低成本部署和理想的视觉检测能力,鸟瞰图(BEV)方法引起了广泛关注。然而,现有模型忽略了驾驶过程中的一个现实场景,即一个或多个视角的摄像头可能会失败,这会大幅降低性能。为了解决这个问题,文章中提出了一个通用的遮蔽鸟瞰图(M-BEV)感知框架,通过端到端训练中的随机遮蔽和重建摄像头视角,可以有效提高对这一挑战场景的鲁棒性。更具体地说,文章中为M-BEV开发了一个新颖的遮蔽视角重建(MVR)模块。它通过随机遮蔽不同摄像头视角的特征,然后利用这些视角的原始特征作为自监督,并在视角间不同的时空背景下重建被遮蔽的特征。通过这样的即插即用MVR,文章中的M-BEV能够从剩余视角中学习缺失的视角,因此在测试中对鲁棒视角恢复和准确感知具有良好的泛化能力。文章中在流行的NuScenes基准测试上进行了广泛的实验,文章中的框架可以显著提升最先进的模型在各种缺失视角情况下的三维感知性能,例如,在缺少后视图的情况下,文章中的M-BEV将PETRv2模型的mAP提升了10.3%。
关键词:自动驾驶、三维感知、鸟瞰图(BEV)、遮蔽视角重建(MVR)、鲁棒性、NuScenes基准测试
文章获取网址:
https://arxiv.org/abs/2312.12144
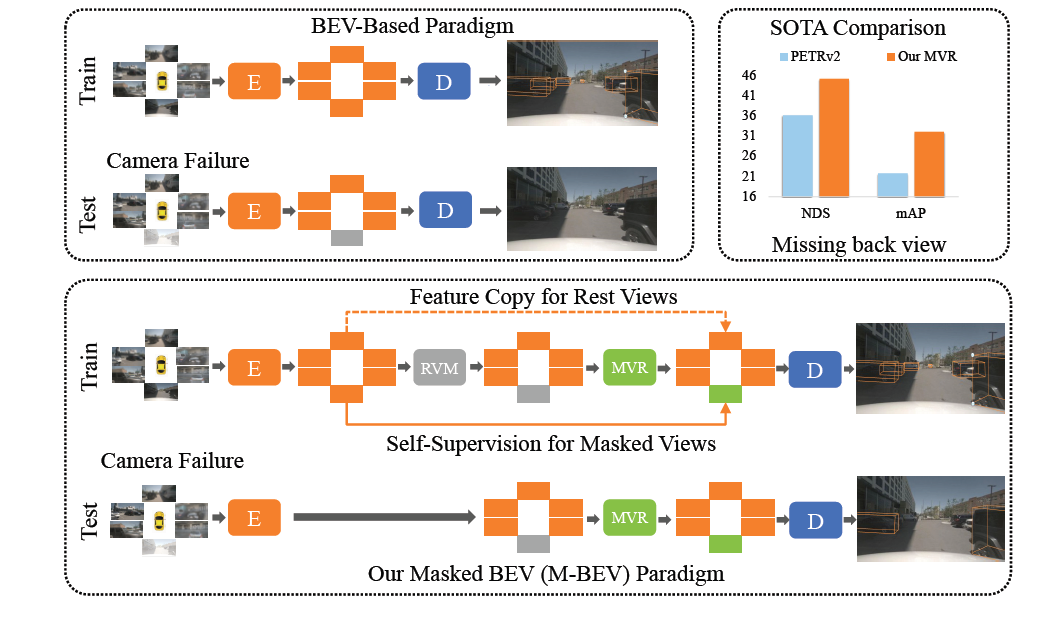
M-BEV框架及其核心组件MVR模块
5. DeepAccident: A Motion and Accident Prediction Benchmark for V2X Autonomous Driving
DeepAccident:一种用于V2X自动驾驶的运动与事故预测基准测试方法
作者:Tianqi Wang, Sukmin Kim, Wenxuan Ji, Enze Xie, Chongjian Ge, Junsong Chen, Zhenguo Li, Ping Luo
机构:The University of Hong Kong , Huawei Noah’s Ark Lab, Dalian University of Technology
摘要:安全是自动驾驶的首要任务。然而目前没有发布的数据集能够直接支持自动驾驶的可解释安全评估。在这项工作中,作者提出了DeepAccident,这是一个通过真实模拟器生成的大规模数据集,包含了在现实世界驾驶中频繁发生的多样化事故场景。提出的DeepAccident数据集包括57K个标注帧和285K个标注样本,大约是大规模nuScenes数据集40k标注样本的7倍。此外,作者提出了一个新的任务,端到端的运动和事故预测,可以用来直接评估不同自动驾驶算法的事故预测能力。此外,对于每个场景,作者设置了四辆车和一套基础设施来记录数据,从而为事故场景提供了多样化的视角,并使得车辆对所有V2X的研究能够在感知和预测任务上进行。最后,文章中提出了一个名为V2XFormer的基线V2X模型,与单车模型相比,在运动和事故预测以及3D物体检测方面表现出优越的性能。
关键词:DeepAccident、安全评估、V2X(车辆通信)、端到端运动和事故预测、V2XFormer、大数据集、多样化场景
文章获取网址:
https://arxiv.org/abs/2304.01168
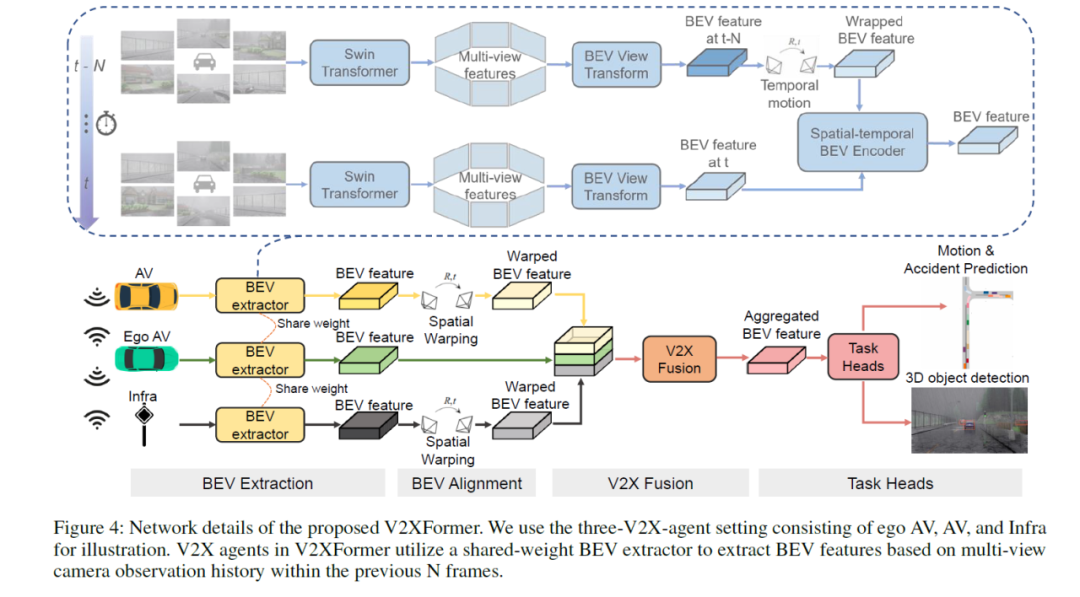
V2XFormer网络细节
6. Traffic Flow Optimisation for Lifelong Multi-Agent Path Finding
交通流优化与终身多智能体路径寻找
作者:Zhe Chen, Daniel Harabor, Jiaoyang Li, Peter J. Stuckey
机构:Department of Data Science and Artificial Intelligence, Monash University, Melbourne, Australia、Robotics Institute, Carnegie Mellon University, Pittsburgh, USA、3OPTIMA Australian Research Council ITTC, Melbourne, Australia
摘要:多智能体路径寻找(MAPF)是机器人学中的一个基本问题,它要求文章中为在共享地图上移动的一组智能体计算无冲突路径。尽管这个领域有很多研究,但随着智能体数量的增加,所有当前算法都面临挑战。主要原因是现有方法通常规划无拥堵最优路径,这会导致交通拥堵。为了解决这个问题,文章中提出了一种新的MAPF方法,通过遵循避免拥堵的路径来引导智能体到达目的地。文章中在两个大规模设置中评估了这个想法:一次性MAPF,每个智能体都有一个单一的目的地,以及永久性MAPF,智能体不断被分配新目的地。从经验上讲,文章中报告了一次性MAPF解决方案质量的大幅改进,以及永久性MAPF整体吞吐量的提高。
关键词:多智能体路径寻找(MAPF)、机器人学、无冲突路径、交通拥堵、智能体、一次性MAPF、永久性MAPF
文章获取网址:
https://arxiv.org/abs/2308.11234
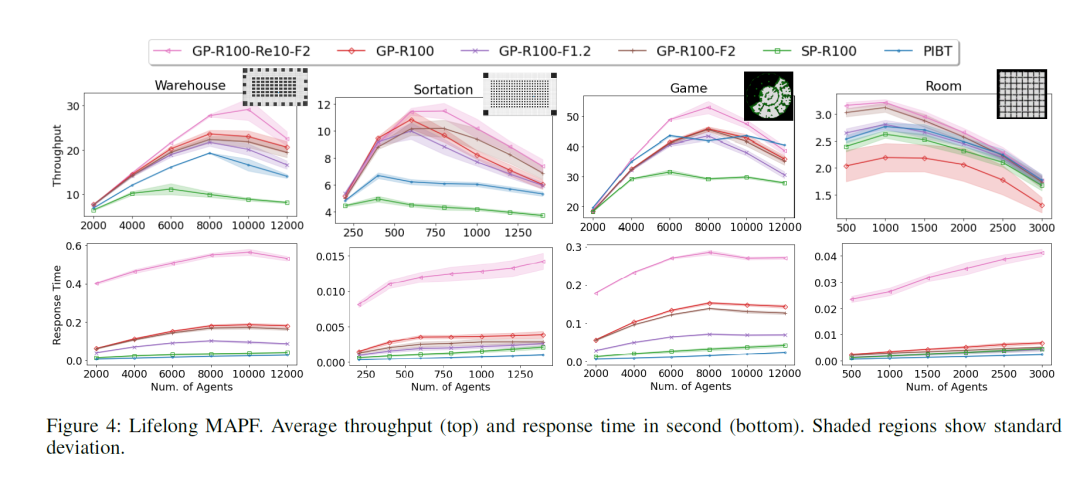
永久性MAPF性能表现
7. Prompt to Transfer: Sim-to-Real Transfer for Traffic Signal Control with Prompt Learning
基于提示学习的交通信号控制模拟到现实转移
作者:Longchao Da, Minquan Gao, Hao Mei, Hua Weio
机构:Arizona State University, 350 E Lemon St, Tempe, AZ 85287, U.S., Johns Hopkins University, 3400 N. Charles Street Baltimore, MD 21218, U.S.
摘要:在交通信号控制(TSC)任务中,针对实现高效的交通通行并减少拥堵浪这一问题,已经有多种解决方案。强化学习(RL)取得了不错的结果,这增强了研究人员解决城市拥堵问题的信心。然而,当将训练模拟器部署到真实世界时,仍然存在性能差距。这个问题主要是由训练模拟器与真实世界环境之间的系统动态差异引起的。大型语言模型(LLMs)是在大量先验知识上训练的,并被证明具有惊人的推理能力。在这项工作中,作者利用LLMs模型并通过基于提示的有根据的动作转换来理解和分析系统动态。接受完形填空提示模板,然后根据可访问的上下文填写答案,利用预训练LLM的推理能力,应用于理解天气条件、交通状态和道路类型如何影响交通动态,基于真实动态采取行动,从而使代理学习到更真实的策略。作者使用DQN进行实验,展示了所提出的PromptGAT在减少从模拟到现实(sim-to-real)的性能差距方面的有效性。
关键词:交通信号控制(TSC)、强化学习(RL)、系统动态差异、大型语言模型(LLMs)、基于提示的地面行动转换(PromptGAT)、模拟到现实转移(sim-to-real)
文章获取网址:
https://arxiv.org/abs/2308.14284
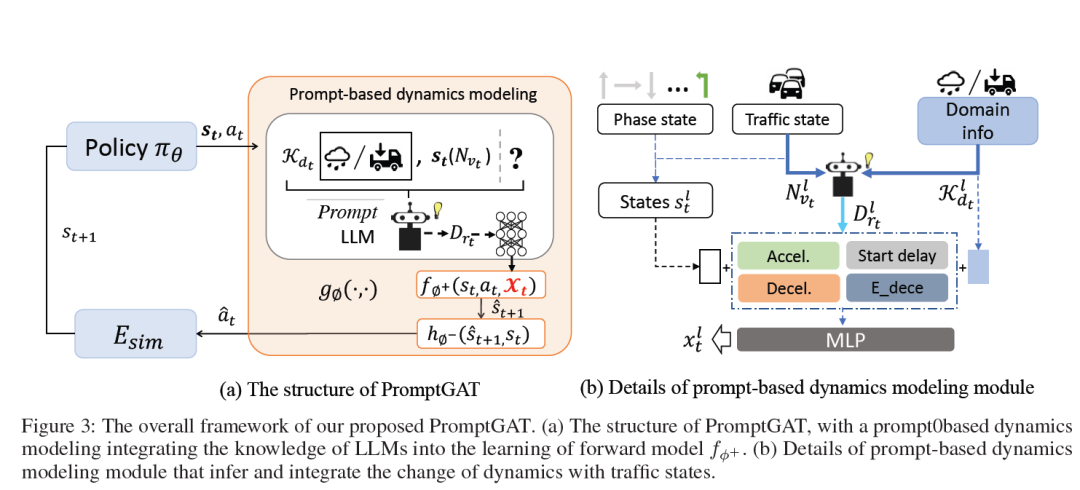
PromptGAT的整体框架
8. PSTN: Periodic Spatial-temporal Deep Neural Network for Traffic Condition Prediction
周期性时空深度神经网络在交通状况预测中的应用
作者:Tiange Wang, Zijun Zhang, Kwok-Leung Tsui
机构:City University of Hong Kong, Virginia Polytechnic Institute and State University
摘要:预测、决策和运动规划对于自动驾驶至关重要。在大多数当代工作中,它们被视为单独的模块或结合到具有共享骨干但任务头分离的多任务学习范式中。然而,作者认为应该将它们整合到一个全面的框架中。尽管最近的几种方法遵循了这种方案,但它们受到复杂输入表示和冗余框架设计的影响。更重要的是,它们无法对未来的驾驶场景进行长期预测。为了解决这些问题,作者重新考虑了自动驾驶任务中每个模块的必要性,并仅将所需模块整合到一个极简的自动驾驶框架中。作者提出了BEVGPT,一个生成式预训练的大型模型,整合了驾驶场景预测、决策和运动规划。该模型以鸟瞰图(BEV)图像作为唯一的输入源,并基于周围交通场景做出驾驶决策。为了确保驾驶轨迹的可行性和平滑性,作者开发了一种基于优化的运动规划方法。作者在Lyft Level 5数据集上实例化BEVGPT,并使用Woven Planet L5Kit进行真实驾驶模拟。所提出框架的有效性和鲁棒性通过在100%的决策指标和66%的运动规划指标上超越先前方法得到了验证。此外,通过驾驶场景预测任务,展示了作者框架准确生成长期BEV图像的能力。这是第一个仅以BEV图像为输入的自动驾驶预测、决策和运动规划的生成式预训练大型模型。
关键词:自动驾驶、预测、决策、运动规划、BEVGPT、生成式预训练、多任务学习、长期预测
文章获取网址:
https://arxiv.org/abs/2310.10357
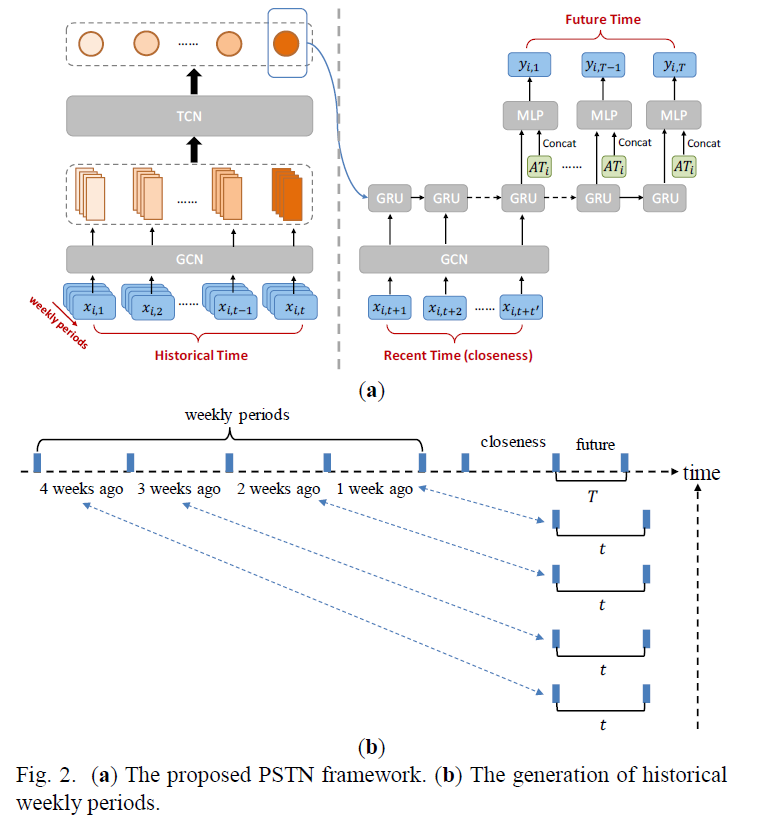
PSTN框架和过去每周各时段集成
作者介绍:周密,西北工业大学在读研究生,研究方向为智能车辆及城市交通系统
终审:张一豪


诚邀加盟
TRZ青年讲堂是交通邦创办的系列专栏,旨在深化读者对交通行业前沿技术的认知,激发在读学生、高校青年教师和行业人士交流合作的动力。
欢迎有意向成为演讲嘉宾的全球英才联系我们!
联系方式
交通邦小助手
(微信号:jiaotongbang)
”
欢迎投稿&合作 Welcome
创立宗旨:交通邦旨在构建泛交通领域最大的交流分享平台,促进产学研融合,最小化信息不对称。欢迎各位学生/教授/专家/企业在学术成果、招生计划、书籍推介、内推岗位、比赛冠名、会议合作等与交通邦合作!
联系方式:添加交通邦小助手微信(jiaotongbang),备注“姓名-学校-合作内容”。
TRAFFIC ZONE
往期作品集
详见公众号主页下方菜单栏
青年讲堂|前沿资讯 会议合作|论文辅导
软件测评|工具推荐 论文书籍期刊推荐
保研夏令营|考研辅导 留学辅导|职业规划
论文书籍期刊推荐 招聘信息|企业推荐
数据集|专业术语 期刊会议整理

