
- 1web应用安全基线-tomcat安全配置
- 2stm32智能小车前进,后退,左转,右转,停止_stm32右箭头
- 3Gilbert Strang-Linear Algebra-Orthogonality_null space and the measurement space are orthogona
- 4TDengine 入门教程⑤——数据库SQL操作 | 建库、建表、数据读写_tdengine教程
- 5BUUCTF做题Upload-Labs记录pass-11~pass-20_buuctf lab upload
- 6【产品经理修炼之道】-AI时代下,产品经理的成长之路_产品经理的修炼之路
- 7python的os模块详细解读_python os
- 8已解决RNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python_凝思系统出现pip is configured with locatio
- 9文件上传漏洞靶场upload-labs学习(pass16-pass21)_upload-labs靶场第16关
- 10一项关于图神经网络在时间序列中的应用的调查:预测、分类、填补和异常检测 A Survey on Graph Neural Networks for Time Series: Forecasting,
Segment Anything:SAM系列模型(SAM、EfficientSAM、MobileSAM、MobileSAM-v2、FastSAM)
赞
踩

Segment Anything | Meta AI https://segment-anything.com/
https://segment-anything.com/
Segment Anything(sam)项目整理汇总 - 知乎0.背景sam是一个无监督的分割图像的基础模型,分割效果非常好,具体细节可看论文解读。 https://zhuanlan.zhihu.com/p/620355474自从sam模型发布以来,基于sam的二次应用及衍生项目越来越多,将其应用于各种任务,…https://zhuanlan.zhihu.com/p/630529550
SAM
https://arxiv.org/pdf/2304.02643.pdf
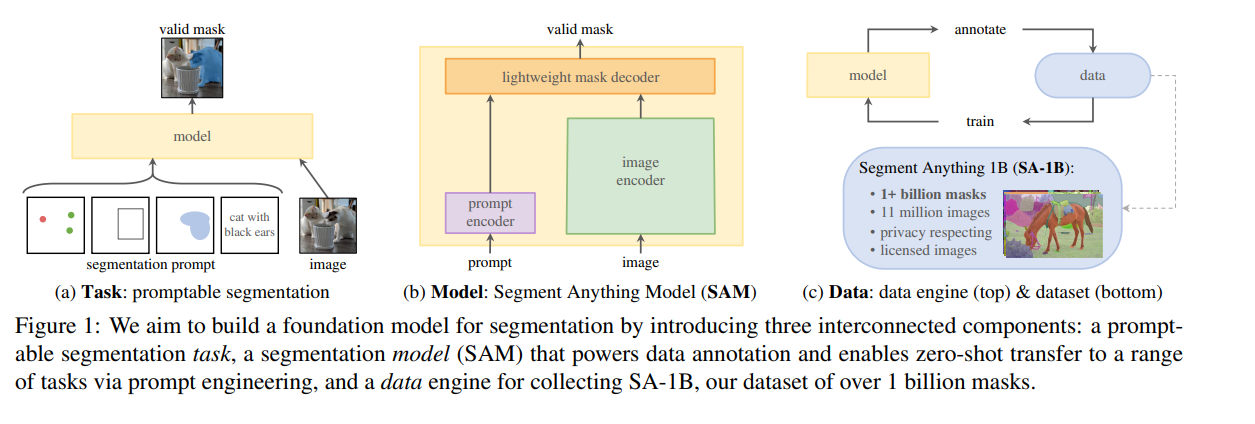
- 新的图像分割任务:这样的任务需要实现零样本泛化。
- 新的模型:Segment Anthing Model。目前分为vit_b,vit_l,vit_h
- 新的数据集:SA-1B。其中包括10亿个掩码和1100万张图像
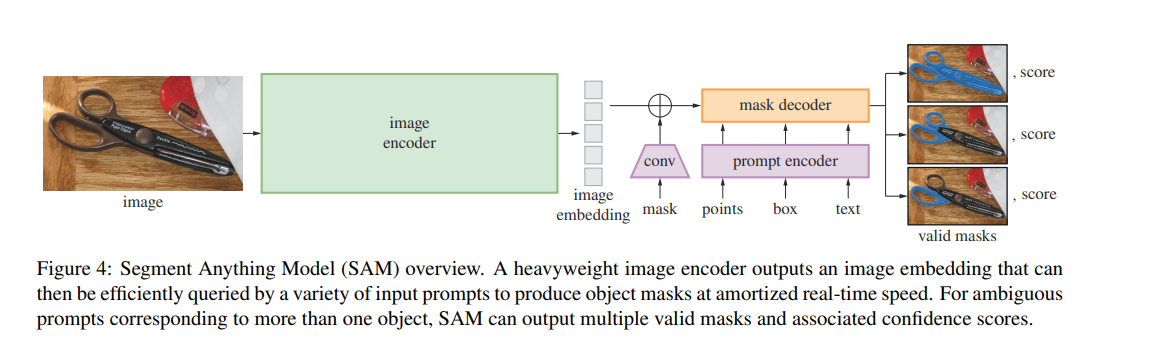
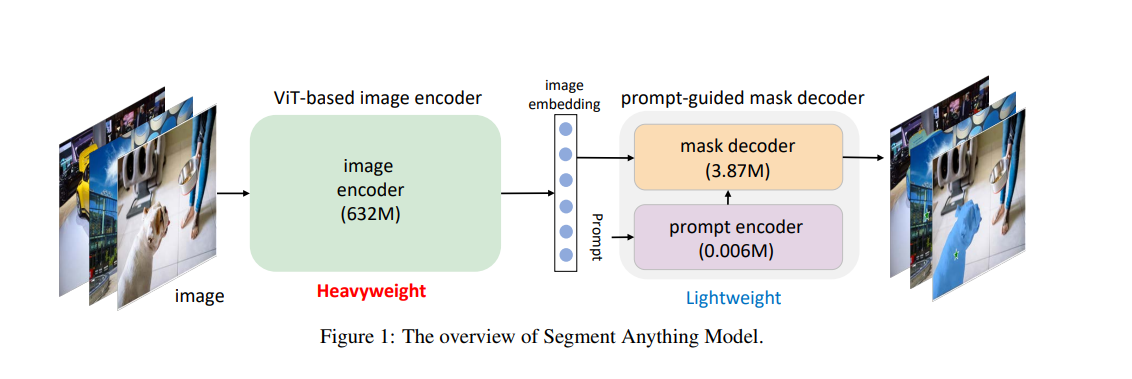
图像编码器 作者使用经过MAE预训练的Vision Transformer (ViT) ,并对其进行微调以处理高分辨率输入 。图像编码器在每张图像上运行一次,并可以在对模型进行提示之前应用。
提示编码器 作者考虑两种类型的提示:稀疏提示(点、框、文本)和密集提示(掩码)。使用位置编码表示点和框,与每种提示类型的学习嵌入相加,而对于自由文本,则使用来自CLIP的现成文本编码器。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素求和。
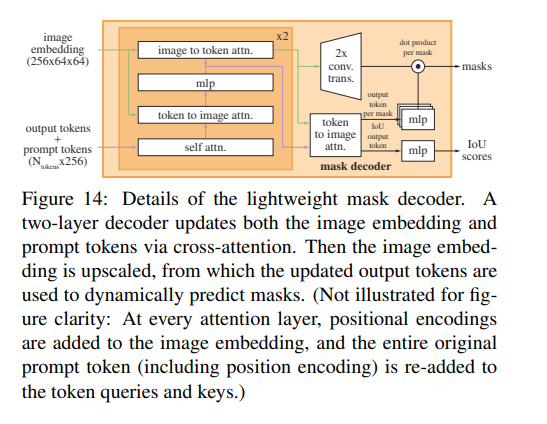
掩码解码器 掩码解码器高效地将图像嵌入、提示嵌入和输出标记映射到一个掩码上。这种设计受到《基于Trasformers的端到端目标检测》和Maskformer的启发,使用了一个修改的Transformer解码器block,后跟一个动态掩码预测头。修改后的解码器block在两个方向(提示到图像嵌入和图像嵌入到提示)上使用自注意力和交叉注意力来更新所有嵌入。在运行两个Block后,对图像嵌入进行上采样,并通过MLP层将输出标记映射到一个动态线性分类器(该分类器用于计算每个图像位置的掩码前景概率)。
相关解读链接:
【Paper日记】Segment Anything - 知乎
EfficientSAM
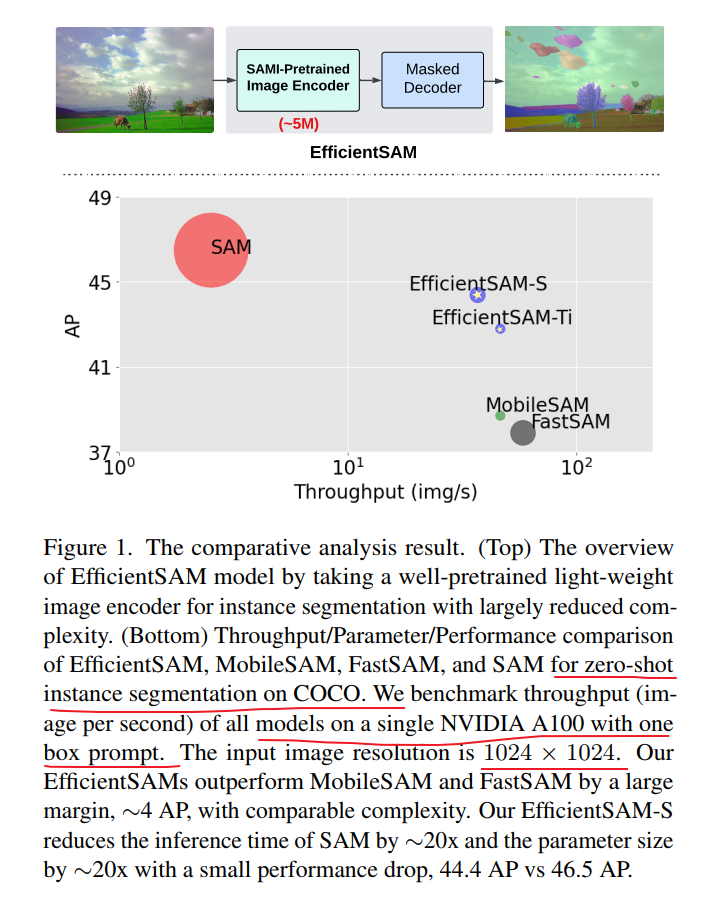
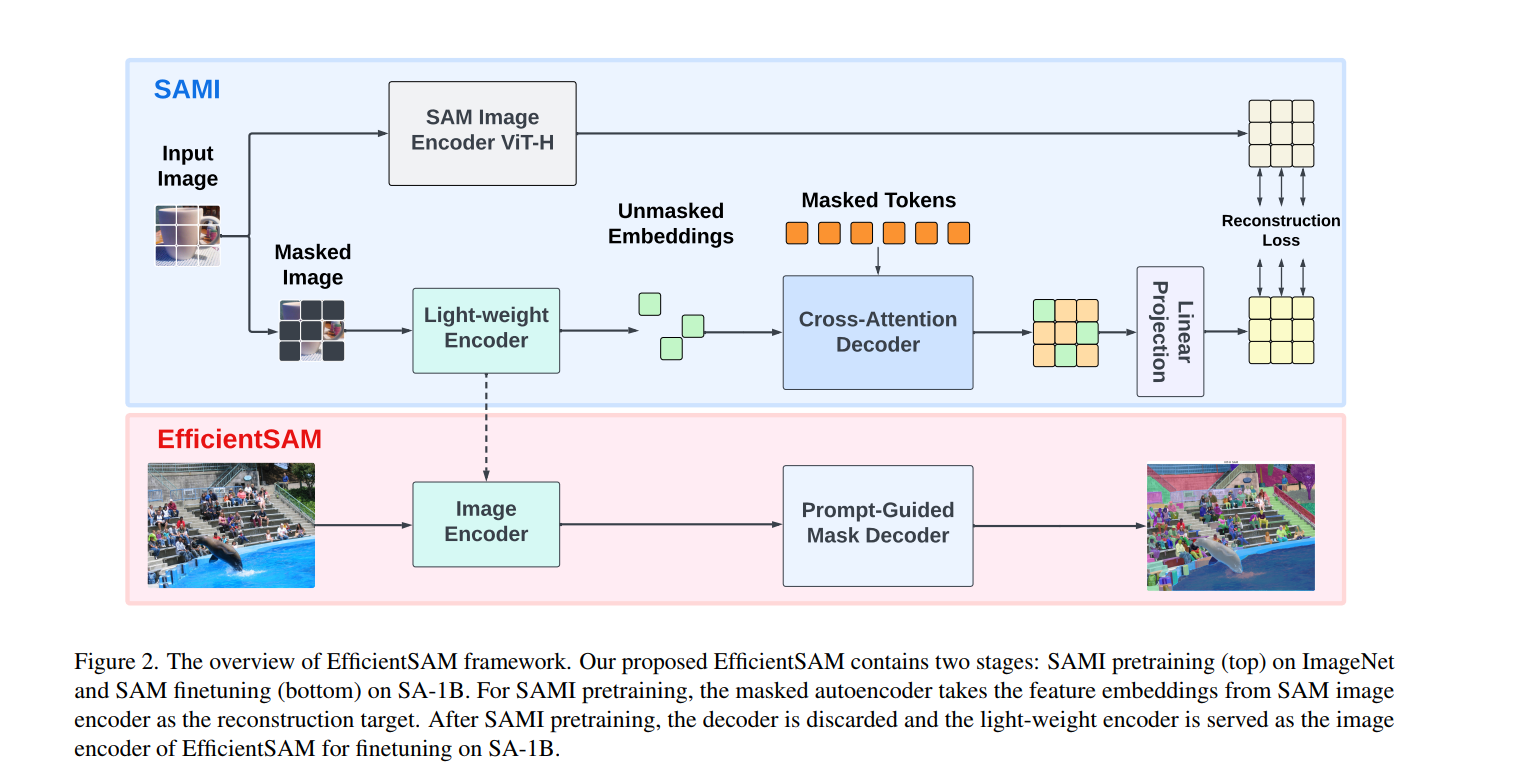
图2-EfficientSAM框架概述。我们提出的EfficientSAM包含两个阶段:ImageNet上的SAMI预训练(上)和SA-1B上的SAM调优(下)。
对于SAMI预训练,掩码自编码器以SAM图像编码器的特征嵌入作为重构目标。SAMI预训练完成后,丢弃解码器,将轻量级编码器作为EfficientSAM的图像编码器,在SA-1B上进行微调。
EfficientViT-SAM
论文链接:https://arxiv.org/abs/2402.05008
代码和预训练:https://github.com/mit-han-lab/efficientvit

轻量化EfficientViT-SAM开源,清华&MIT&英伟达发布,速度提升48.9倍
MobileSAM
MobileSAM模型是在2023年6月27日发布的
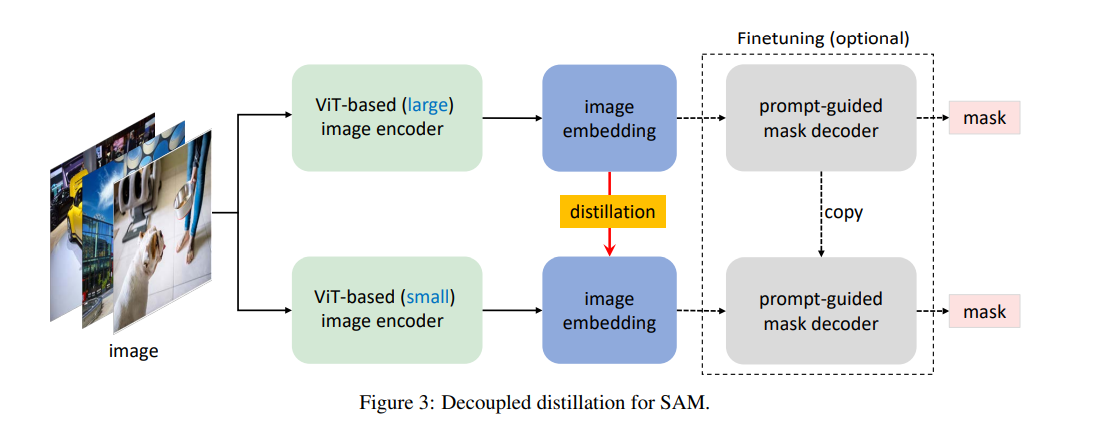
将原始SAM中的图像编码器ViT-H提取到轻量级图像编码器中,可以自动与原始SAM中的mask解码器相兼容。训练可以在不到一天的时间内完成,由此产生的轻量级SAM被称为MobileSAM,它要小60倍以上,但性能与原来的SAM相当。就推理速度而言,MobileSAM每张图像的运行时间约为10ms:图像编码器为8ms,掩码解码器为2ms。凭借卓越的性能和更高的通用性,我们MobileSAM比同期的FastSAM小7倍,快4倍,使其更适合移动端的应用。
直接把 ViT-H 蒸馏到小型的图像编码器中


相关解读链接:
论文解读:MobileSAM | FASTER SEGMENT ANYTHING: TOWARDS LIGHTWEIGHT SAM FOR MOBILE APPLICATIONS-CSDN博客
MobileSAM-v2
感觉就是yolov8目标检测框作为提示+SAM分割SegEvery
采用目标检测算法的边界框作为提示框来进行分割
SegEvery与SAM的效率瓶颈在于其掩模解码器,因为它需要首先使用冗余的网格搜索提示生成大量掩模,然后执行过滤以获得最终的有效掩模。
文章作者提出通过直接使用仅包含有效提示的方法生成最终的掩模(检测边界框),从而提高其效率,这可以通过目标发现获得有效提示。作者提出的方法不仅能够将掩模解码器的总时间减少至少16倍,而且还能够实现卓越的性能。

mask解码器随着分割的点个数增多,时间也在增多
作者提出了具有对象感知的框提示,以替代默认的网格搜索点提示,从而显著提高了其速度,同时实现了整体上更优越的性能。用对象感知提示采样替换默认的网格搜索提示采样

FastSAM
网络结构上和SAM基本上没什么关系
在线demo链接:Examples – casia-iva-lab/fastsam – Replicate
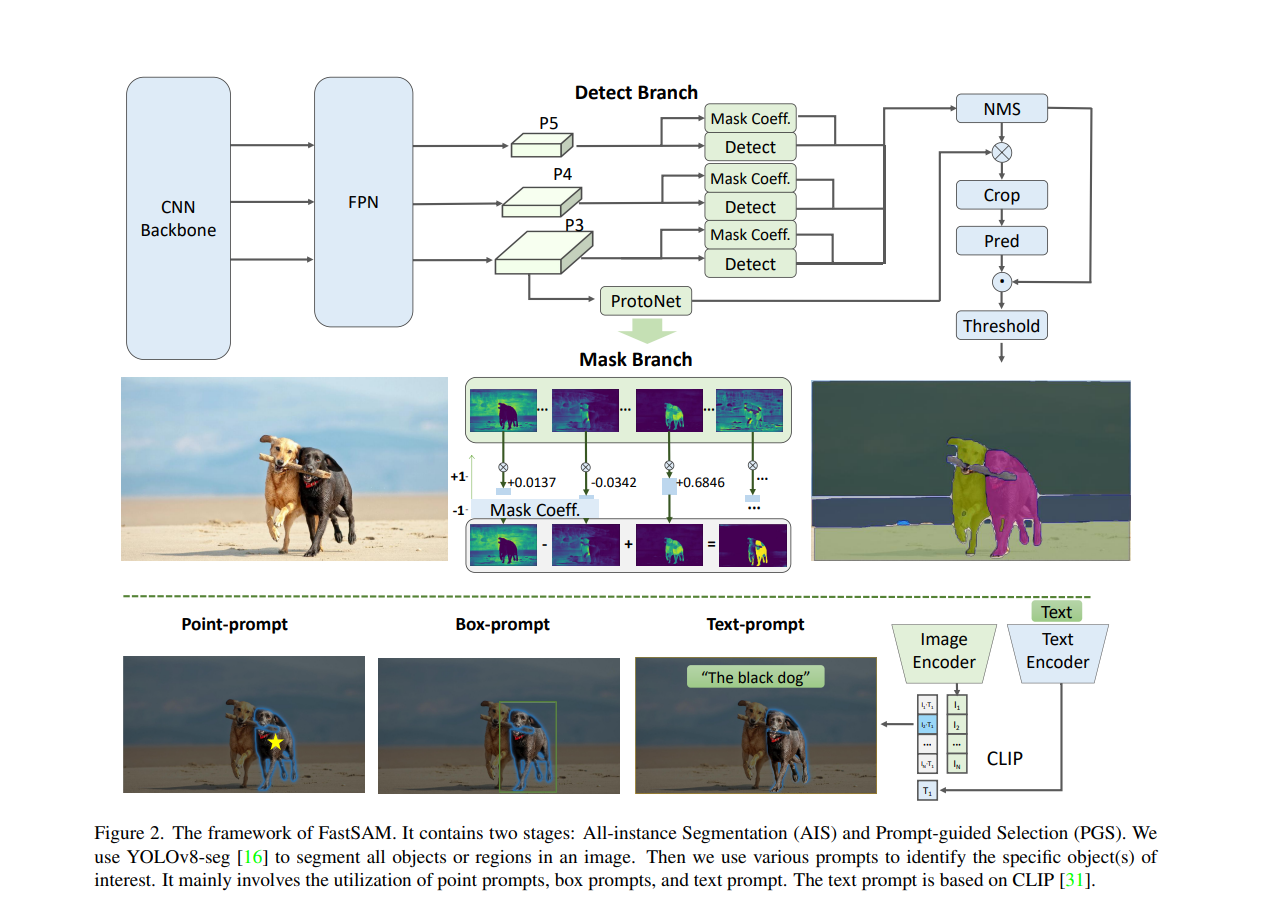
将SAM分成两个相对独立的任务:实例分割和prompt。因此使用yolo这种CNN的模型就可以完成类似SAM的任务。
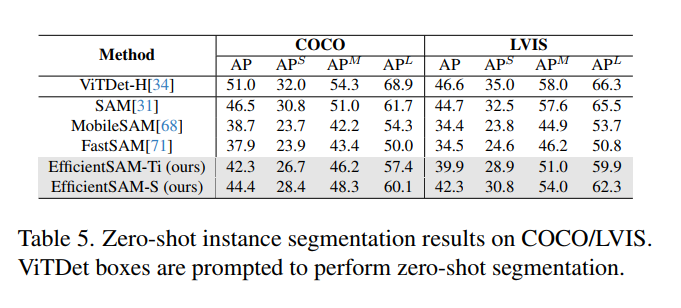
- 基于YOLOv8-seg实现了FastSAM,它比SAM快50倍,且训练数据只有SAM的1/50,同时运行速度不受point输入数量的影响
- FastSAM定义Segment Anything Task(SAT)为根据提示进行语义分割任务,提示指:前景|背景点、bounding boxes、mask、text;
- 将SAT分解为2阶段,第一阶段为对输入图像的全景实例分割,第二阶段为根据提示输入对全景实例分割结果进行稀疏化选择
相关解读链接:论文解读:FastSAM | Fast Segment Anything | 基于yolov8-seg实现 比SAM快50倍-CSDN博客
EdgeSAM
SlimSAM
Tokenize Anything via Prompting
顶配版SAM,由分割一切迈向感知一切
近日,智源研究院视觉团队推出以视觉感知为中心的基础模型 TAP (Tokenize Anything via Prompting), 利用视觉提示同时完成任意区域的分割、识别与描述任务。将基于提示的分割一切基础模型 (SAM) 升级为标记一切基础模型 (TAP),高效地在单一视觉模型中实现对任意区域的空间理解和语义理解。相关的模型、代码均已开源,并提供了 Demo 试用,更多技术细节请参考 TAP 论文。
论文地址:https://arxiv.org/abs/2312.09128
项目&代码:
https://github.com/baaivision/tokenize-anything
模型地址:
https://huggingface.co/BAAI/tokenize-anything
Demo:
https://huggingface.co/spaces/BAAI/tokenize-anything
简单点击或涂鸦图片中感兴趣的目标,TAP 即可自动生成目标区域的分割掩码、类别标签、以及对应的文本描述,实现了一个模型同时完成任意的分割、分类和图像描述。

SAM-Lightening
论文链接:https://arxiv.org/pdf/2403.09195.pdf
代码:https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/

