
热门标签
热门文章
- 1C#界面设计之文本阅读器的设计_文本阅读器 可排版 c#
- 2java毕业设计基于微信小程序的汽车租赁[附源码]_关于租车小程序的背景及意义论文中怎么写
- 3情感分析代码(阅读+书写+注释)_情感分析代码01怎么得到
- 4python3:csv的读写_python csv
- 5从上到下打印二叉树(二叉树层序遍历)_二叉树下层序遍历
- 6java.io.FileNotFoundException 系统找不到指定的文件_java.io.filenotfoundexception: log4j.properties (系
- 7【二十二】搭建SpringCloud项目六(Config)配置中心_springcloud入门实战- springcloud config配置中心
- 8Java高级 / 架构师 场景方案 面试题(二)_java场景设计面试题
- 9【NLP】第4章 从头开始预训练 RoBERTa 模型_roberta模型
- 10日志分析技能不足:安全团队缺乏足够的技能来分析和理解日志内容
当前位置: article > 正文
Python将网页导出为pdf文件,不安装额外的外部依赖(完整代码)_python puppeteer pdf
作者:小舞很执着 | 2024-07-21 20:07:16
赞
踩
python puppeteer pdf
目录
使用pyppeteer库导出pdf
pyppeteer是一个Python库,它提供了一个高级API来控制puppeteer(一个Node库,用于通过Chrome或Chromium浏览器自动化)。此外,
pyppeteer需要Chromium或Chrome浏览器及其对应的chromedriver。你可以使用webdriver_manager来管理chromedriver的版本
安装
- pip install pyppeteer
- pip install webdriver_manager
使用
- import asyncio
- from pyppeteer import launch
- from webdriver_manager.chrome import ChromeDriverManager
-
- # 在你的代码中设置chromedriver路径
- executable_path = ChromeDriverManager().install()
-
-
- async def generate_pdf(url, output_path):
- browser = await launch()
- page = await browser.newPage()
- # 使用 networkidle2 作为等待条件,这意味着在网络空闲超过两秒后认为页面加载完成
- await page.goto(url, waitUntil='networkidle2')
- await page.pdf({'path': output_path, 'format': 'A4'})
- await browser.close()
-
- # 运行事件循环并生成PDF
- asyncio.get_event_loop().run_until_complete(generate_pdf("https://www.baidu.com", "output.pdf"))
效果如下
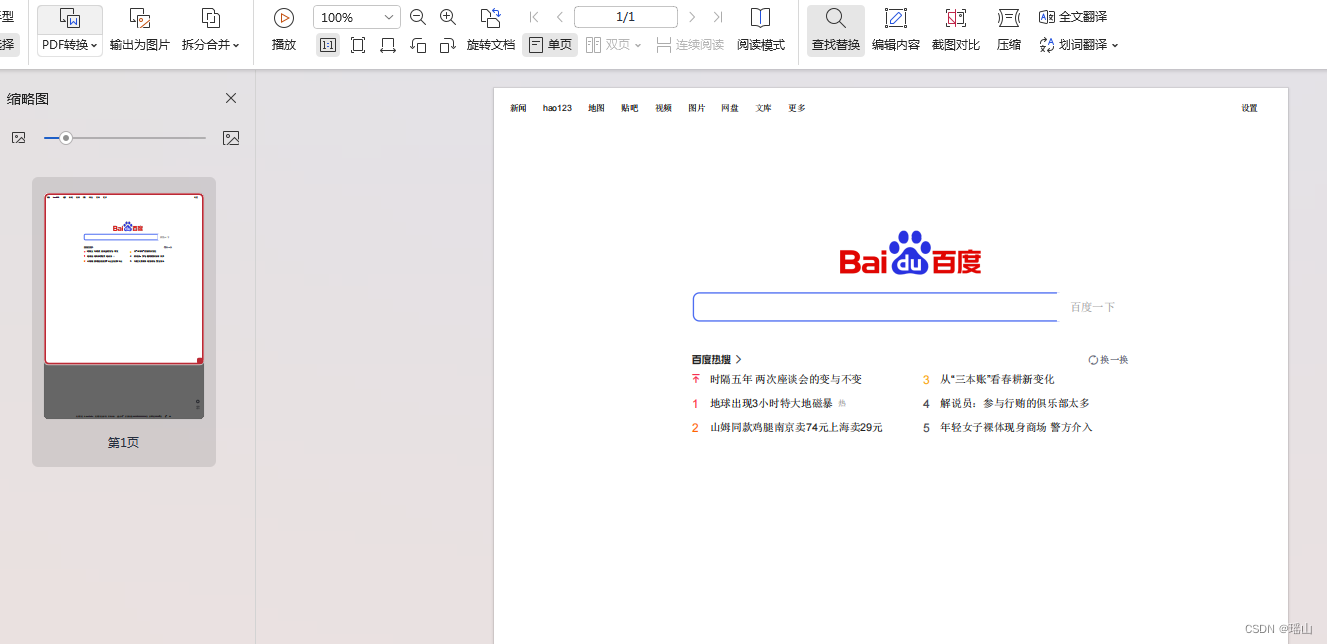
结语
在Python中将网页导出为PDF有多种方案,
- 使用Selenium WebDriver可以打开浏览器,加载网页,然后截取屏幕内容保存为PDF。这种方法的好处是生成的PDF与浏览器中的显示效果一致,包括动态加载的内容。
wkhtmltopdf是一个命令行工具,可以将HTML转换为PDF。它支持CSS样式,并且生成的PDF质量很高。pdfkit是一个Python库,它基于wkhtmltopdf提供了更简洁的接口。你可以直接使用Python代码将HTML转换为PDF,而不需要手动调用命令行工具。选择哪种方法取决于具体需求。如果需要处理动态加载的内容或需要与浏览器交互,那么Selenium WebDriver可能是更好的选择。如果只是需要将静态的HTML转换为PDF,并且关心生成的PDF质量,那么
wkhtmltopdf或pdfkit可能更适合。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/862090
推荐阅读
相关标签

