
- 1通义灵码-IDEA的使用教程_idea 通义灵码
- 2ollama调用本地模型时出现502_ollama serve报错
- 3npu算力如何计算_麒麟990 5G芯片的NPU如何做到算力暴涨?华为自研达芬奇架构详解...
- 4通过远程桌面连接Windows实例,提示“为安全考虑,已锁定该用户账户,原因是登录尝试或密码更改尝试过多”_为安全考虑,已锁定该用户帐户,原因是登录尝试或密码更改尝试过多。请稍候片刻再重
- 5MySQL入门篇
- 6Yolov5笔记--检测bilibili下载好的视频_yolo检测视频
- 751-LED点阵屏_hc595驱动led点阵
- 8企业数字化转型AI能力中台(总体架构、系统功能)建设方案_ai中台系统架构
- 9封装了一个仿照抖音效果的iOS评论弹窗
- 10Loading class `com.mysql.jdbc.Driver‘. This is deprecated._loading class `com.mysql.jdbc.driver'. this is dep
Structure-Aware Transformer for Graph Representation Learning 简单笔记
赞
踩
SAT 2022
Motivations
1、Transformer with positional encoding do not necessarily capture structural similarity between them(对于一些即便处于不同位置,但是有相似环境、相似结构的结点,应该有相似的表示)
2、suffer from problems of limited expressiveness, over-smoothing, and over-squashing(一般的图神经网络不能太深)
2、a new self-attention mechanism: extracting a subgraph representation rooted at each node before computing the attention(先提取基于每个结点的子图的表示)
Contributions
1、reformulate the self-attention mechanism as a kernel smoother
2、automatically generating the subgraph representations
3、making SAT an effortless enhancer of any existing GNN
4、SAT is more interpretable
Methods
Structure-aware self-attention
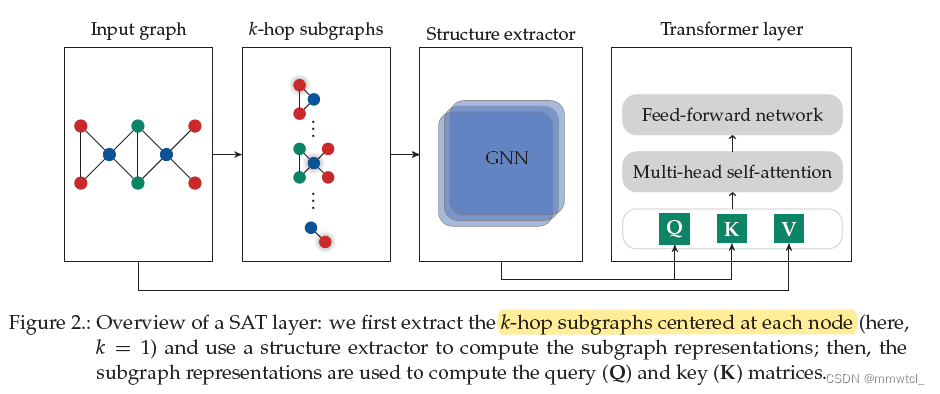
structure extractor
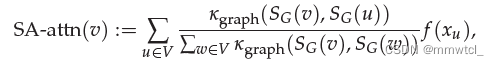
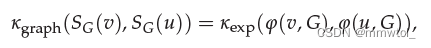
1、k-subtree GNN extractor
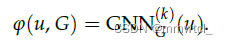
take the output node representation at u as the subgraph representation at u
2、k-subgraph GNN extractor
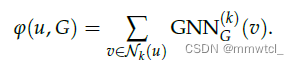
aggregates the updated node representations of all nodes within the k-hop neighborhood using a pooling function
Structure-aware transformer
1、include the degree factor in the skip-connection, reducing the overwhelming influence of highly connected graph components
Combination with absolute encoding
1、absolute positional encoding is not guaranteed to generate similar node representations even if two nodes have similar local structures
2、subgraph representations used in the structure-aware attention can be tailored to measure the structural similarity between nodes
Conclusions
1、The structure-aware framework achieves SOTA performance
2、k-subtree and k-subgraph SAT improve upon the base GNN
3、incorporating the structure via our structure-aware attention brings a notable improvement
4、a small value of k already leads to good performance, while not suffering from over-smoothing or over-squashing
5、a proper absolute positional encoding and a readout method improves performance, but to a much lesser extent than incorporating the structure into the approach
Limitations
it suffers from the same drawbacks as the Transformer, namely the quadratic complexity of the self attention computation

