
- 1Nuxt3实现多语言与事件总线(EventBus)_nuxt3 多语言
- 2使用 Python 和 AI 开发一个 PPT 生成器_python ai 生成ppt
- 3C#-WebForm-WebForm开发基础、如何给控件注册事件?——事件委托写法、http无状态性、三层结构...
- 4Git解决冲突_clask git
- 5怎样利用MATLAB制作图中图(局部放大图片)_matlab图中图
- 6华为OD机考题(HJ74 参数解析)
- 7AGI 之 【Hugging Face】 的【问答系统】的 [Haystack构建问答Pipeline] 的简单整理
- 8手把手教你复现顶会论文 —— RandLA-Net (CVPR 2020 Oral)_randlanet复现pytorch
- 9大数据最全【Rust指南】快速入门 开发环境 hello world_rust开发是啥_rust开发环境
- 10VS2015应用Github扩展_vs2015下载github插件
初识Sora,学习新技术记住官网最靠谱「快且准」,Sora是什么?它和ChatGPT一样吗?_gpt和sora的区别
赞
踩
曾经我遇到一位技术大牛,他说:“学习一项新技术直接爬官网,是最快最靠谱的方式”,后来实践证明,他说的一点儿没错。
下面这张图,大家估计都见过吧?哈哈哈~
我是从这儿知道Sora这款产品的……

一、什么是Sora?
Sora是继ChatGPT4之后openaAI的又一人工智能模型产品。简单说它可以通过文本生成视频。官方说明它可以根据文本指令创建逼真和富有想象力的场景。
二、Sora概述
官网介绍解读,为自己和没有时间和英语有限的朋友们准备哈~
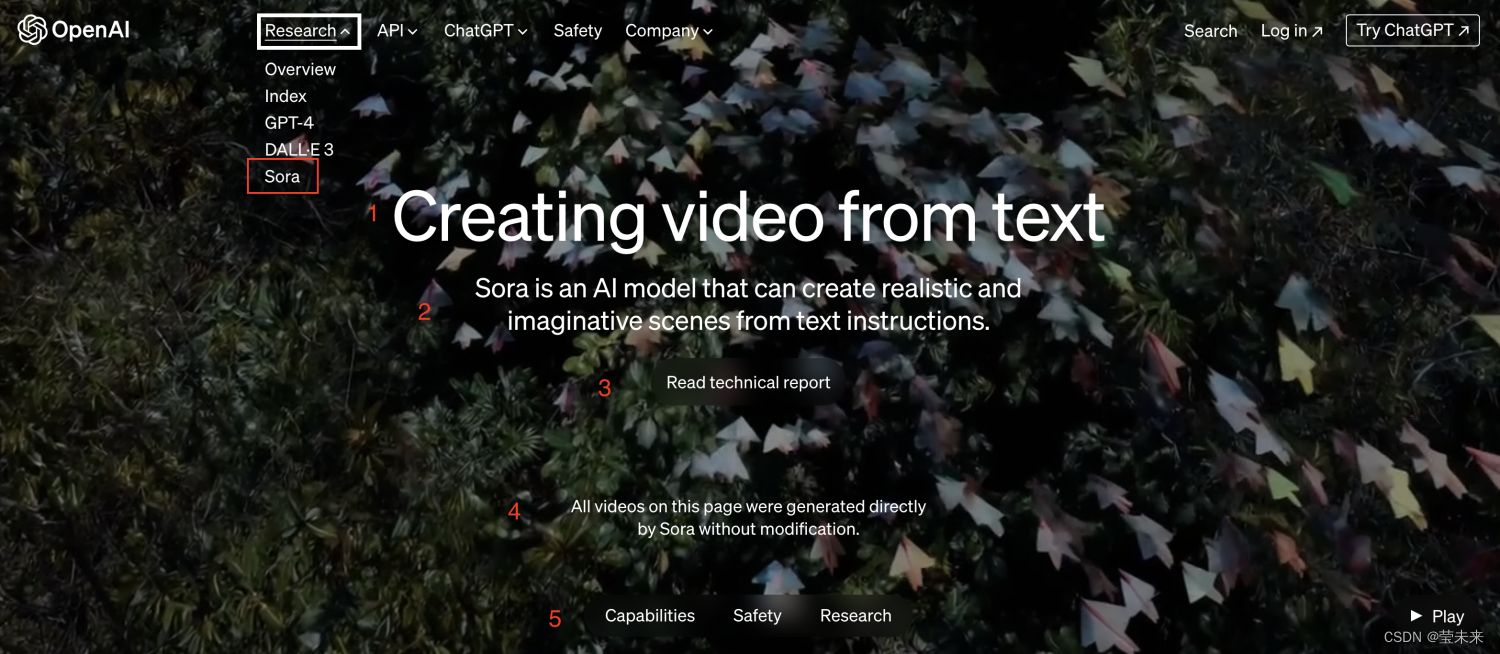
从官网这张图,我们了解到以下内容:
改网页的所有内容都是通过Sora直接生成的,没有经过修改。
能力、安全性、检索探索
1、能力说明

我们正在教授人工智能理解和模拟运动中的物理世界,目的是训练模型,帮助人们解决需要现实世界互动的问题。

我们的文生视频模型Sora,可以根据用户的提示词,生成长达1分钟的高质量视频。

这一段提示词就是现在网上很火的那个在街道上行走女人的宣传视频,视频太大就不放了,可以网络查询。

Sora能够生成具有多个角色、特定运动类型以及主题和背景的,拥有准确细节的复杂场景。该模型不仅了解用户在提示中的要求,还了解这些东西在物理世界中是如何存在的。

该模型对语言有深刻的理解、使其能准确地理解提示词,并生成令人信服的人物,表达充满活力的情感。Sora还可以在一个视频中创建多个镜头,准确地保持角色和视觉风格。

目前的模型有缺点,它可能难以准确模拟复杂场景的物理特性,也可能无法理解因果关系的具体实例。例如,一个人可能咬了一口饼干,但之后,饼干可能没有咬痕。
该模型还可能混淆提示的空间细节,例如,混淆左右,并可能难以准确描述随着时间的推移发生的事件,例如遵循特定的相机轨迹。
2、安全性

在OpenAI的产品中提供Sora之前,我们将采取几个重要的安全措施。我们正在与红队合作 出模型报告。 在错误信息、仇恨内容和偏见等领域的领域专家 将对模型进行对抗性测试。

我们也在构建工具来帮助检测误导性内容检查,例如检测分类器,它可以判断视频是由Sora生成的。如果我们在OpenAI产品中部署该模型,我们计划在未来包括C2PA(该协议是由“内容来源和真实性联盟”创建的,该协议能为AI生成内容上的标签,目前已经获得微软和Adobe支持)元数据。

除了开发新技术为部署做准备外,我们还是利用构建现有的已使用的DALL·E 3的产品构建的安全方法,这些方法对Sora也适用。

例如,一旦在OpenAI产品中,我们的文本分类器就会检查并拒绝违反我们使用政策的文本输入提示,比如那些要求极端暴力、性内容、仇恨图像、名人肖像或他人IP的提示。我们还开发了强大的图像分类器,用于审查生成的每个视频的帧,以帮助确保它在向用户显示之前符合我们的使用策略。
3、技术检索

Sora是一个扩散模型,它从一个看起来像静态噪声的视频开始生成视频,并通过多次去除噪声来逐渐变换视频。

Sora能够一次生成整个视频,也可以扩展已生成的视频长度。通过一次为模型提供多帧的前瞻性,我们解决了一个具有挑战性的问题,即确保使在暂时离开也可以生成相同主题的视频。

与GPT模型类似,Sora使用了转换器架构,释放了卓越的扩展性能。

我们将视频和图像表示为补丁(较小数据单元的集合),每个数据单元类似于GPT中的令牌。通过统一我们表示数据的方式,我们可以在比以前更广泛的视觉数据上训练扩散转换器,跨越不同的持续时间、分辨率和纵横比。

Sora建立在过去对DALL·E和GPT模型的研究基础上。它使用了DALL·E 3中的重述技术,该技术涉及为视觉训练数据生成的高度描述性的字幕。结果,模型能够更忠实地遵循用户在生成的视频中的文本指令。

除了能够仅根据文本指令生成视频外,该模型还能够获取现有的静止图像并从中生成视频,从而准确地动画化图像内容,并注意小细节。该模型还可以获取现有视频并对其进行扩展或填充缺失的帧。在我们的技术报告中了解更多信息。

Sora服务是一个能够理解和模拟真实世界的模型的基础,我们相信这一能力将是实现AGI的重要里程碑。

