
热门标签
热门文章
- 1如何培养程序员的领导力?_程序员如何培养自己的管理能力
- 2【1】MongoDB的安装以及连接_mongodb怎么连接
- 3Linux 安装 Gitblit_gitblit linux 安装
- 42022卡塔尔世界杯互动游戏|运营策略_世界杯 运营 活动 游戏
- 5vivado的RTL设计与联合modelsim仿真_vivado可以生成rtl
- 6目前常见的Linux操作系统_linux操作系统分类
- 7京东软件测试岗:不忍直视的三面,幸好做足了准备,月薪18k,已拿offer_京东测开三面
- 8视觉应用线扫相机速度反馈(倍福CX7000PLC应用)
- 9GPT3.5、GPT4、GPT4o的性能对比_gpt3.5和gpt4o
- 10【C语言题解】1、写一个宏来计算结构体中某成员相对于首地址的偏移量;2、写一个宏来交换一个整数二进制的奇偶位
当前位置: article > 正文
当当网Python图书数据分析_python分析图书大数据图书编号对应图书简表
作者:小舞很执着 | 2024-07-06 15:00:19
赞
踩
python分析图书大数据图书编号对应图书简表
1.检视网页 爬虫 要看是否允许爬取
- 进入页面,输入python进行搜索,查看源码
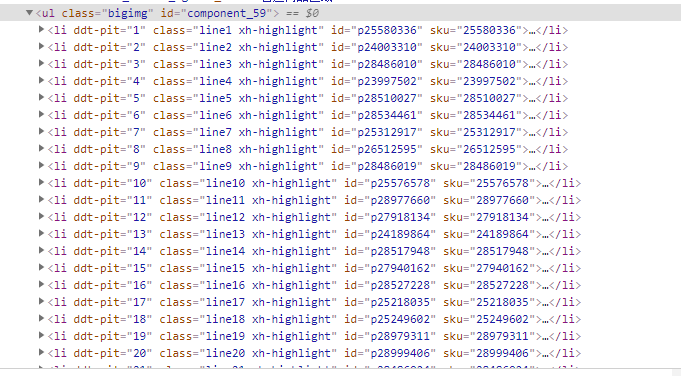
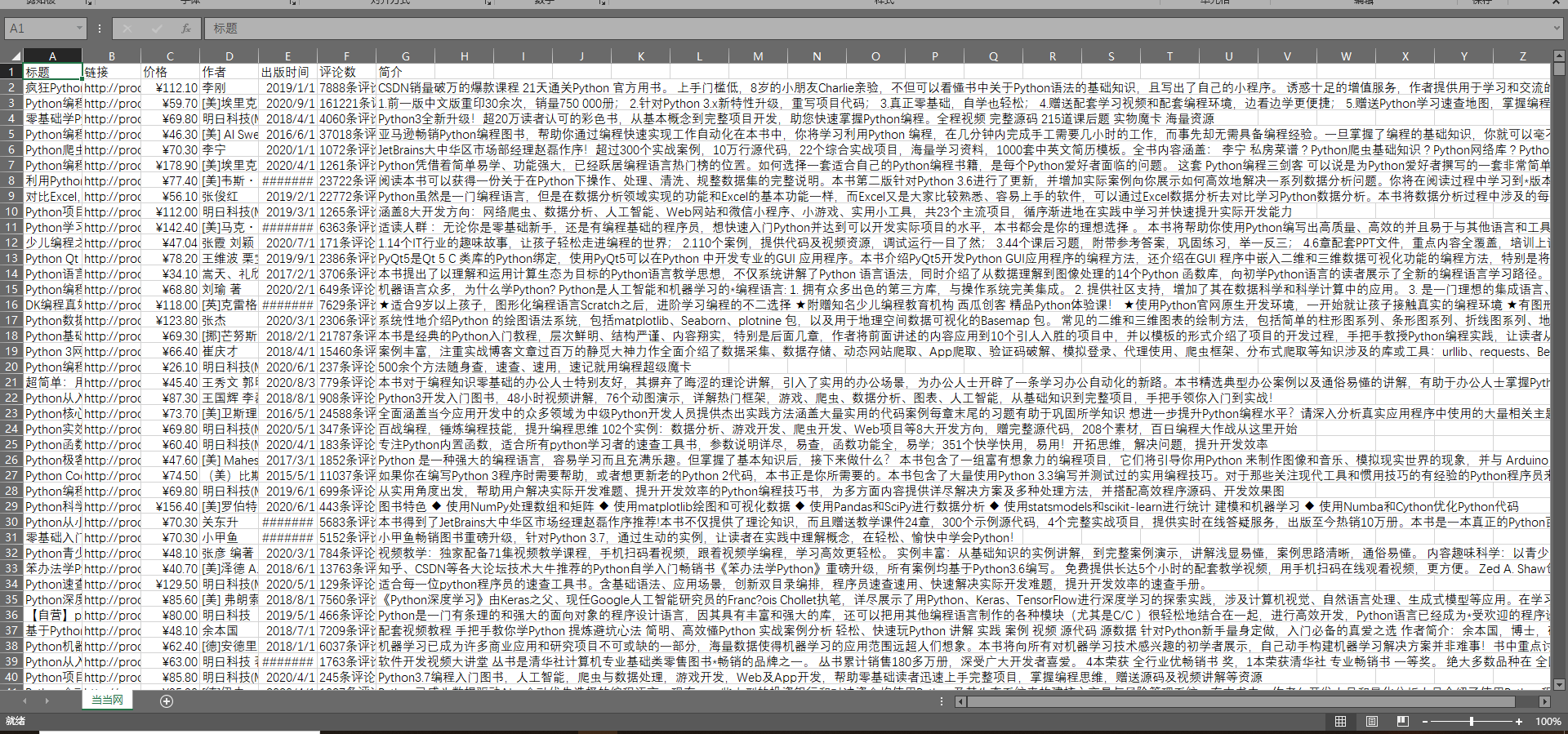
- xpth查看,//ul[@class="bigimg"]/li,里面包含的是全部的信息,我们需要将标题'链接,价格,作者,出版时间,评论数,简介全部分类爬取

- 标题 尝试2页
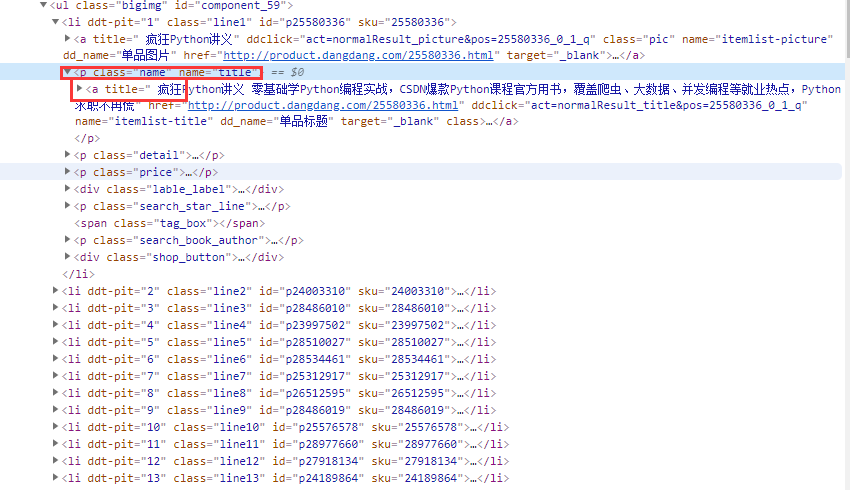

def parse_page(response):
tree = etree.HTML(response.text)
li_list = tree.xpath('//ul[@class="bigimg"]/li')
# print(len(li_list)) # 测试
for li in li_list:
data = []
time.sleep(.5)
# 获取书的标题,并添加到列表中
title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
print(title)
- 同理,爬取价格,作者,出版时间,评论数
for li in li_list:
data = []
# 获取书的标题,并添加到列表中 title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
# 获取商品链接,并添加到列表中 commodity_url = li.xpath('./p[@class="name"]/a/@href')[0]
data.append(commodity_url)
# 获取价格,并添加到列表中 price = li.xpath('./p[@class="price"]/span[1]/text()')[0]
data.append(price)
# 获取作者,并添加到列表中 author = ''.join(li.xpath('./p[@class="search_book_author"]/span[1]//text()')).strip()
data.append(author)
# 获取出版时间,并添加到列表中 time = li.xpath('./p[@class="search_book_author"]/span[2]/text()')[0]
pub_time = re.sub('/','',time).strip()
data.append(pub_time)
# 获取评论数,并添加到列表中 comment_count = li.xpath('./p[@class="search_star_line"]/a/text()')[0]
# 获取书本的简介,并添加到列表中.由于有些书本没有简介,所以要用try commodity_detail = '' commodity_detail = li.xpath('./p[@class="detail"]/text()')[0]
data.append(commodity_detail)
- 标题 尝试2页
- 查看csv文件
-
- xpth查看,//ul[@class="bigimg"]/li,里面包含的是全部的信息,我们需要将标题'链接,价格,作者,出版时间,评论数,简介全部分类爬取
- 全部爬取
- 最终简化代码
import requests
from lxml import etree
import csv
import re
def get_page(key):
for page in range(1,101):
url = '%s-当当网 % (key,page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' }
response = requests.get(url = url,headers = headers)
parse_page(response)
print('page %s over!!!' % page)
def parse_page(response):
tree = etree.HTML(response.text)
li_list = tree.xpath('//ul[@class="bigimg"]/li')
# print(len(li_list)) # 测试 for li in li_list:
data = []
try:
# 获取书的标题,并添加到列表中 title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
# 获取商品链接,并添加到列表中 commodity_url = li.xpath('./p[@class="name"]/a/@href')[0]
data.append(commodity_url)
- 最终简化代码
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/793178
推荐阅读
相关标签

