
- 1第⼆代 Spring Cloud 核⼼组件(SCA)Sentinel 分布式系统的流量防卫兵_sentinel 接口重试三次
- 2Rust 语言中的跨平台 GUI 库_rust 界面库
- 3毕业设计课题:学生成绩管理系统,基于java+SSM+mysql
- 4三级等保都有哪些要求?如何才能顺利通过?_信息系统等级保护第三级基本要求
- 5AT32F435 入门使用_自制atlink
- 6org.codehaus.jackson.JsonParseException: Illegal unquoted character ((CTRL-CHAR, code 10)): has to b_json parse error: illegal unquoted character ((ctr
- 7云计算复习一轮_分布式存储目前理论节点最多
- 8RT1052 BootLoader升级相关
- 9Redis跳跃表(SkipList)_redis 跳跃表
- 1030个落地案例告诉你,区块链到底怎么用_2021年区块链落地案例
Set之TreeSet与HashSet_hashset和treeset
赞
踩
上一篇我们讲到Java中的Set方法,他是一个不允许重复元素的集合,今天我们来围绕Set的TreeSet和HashSet进行。
HashSet
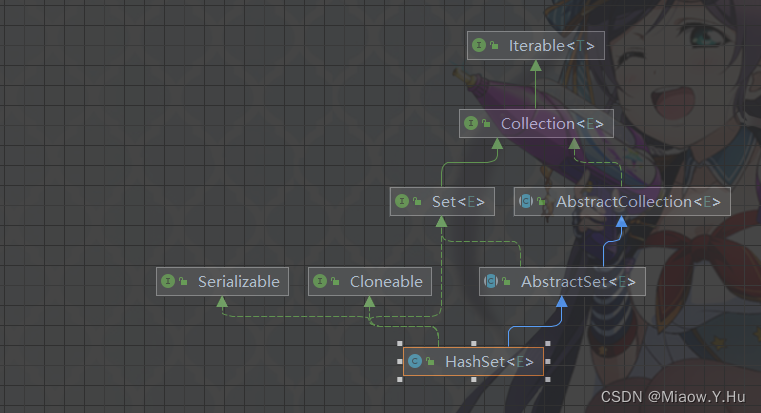
HashSet是基于哈希表实现的,他可以快速的进行插入、删除和查找操作,时间复杂度为O(1) ,HashSet不会保证元素的顺序,原因在于,他是根据元素的哈希值来存储和查询元素的,如果需要按照元素的顺序进行遍历集合,可以使用LinkedHashSet,他是HashSet的子类,内部使用的是链表维护元素的顺序。
HashSet的构造方法以及成员变量:
//成员变量 //元素均存入HashMap的实例m中 private transient HashMap<E,Object> map; //作为实例m每个key的value private static final Object PRESENT = new Object(); //构造方法 /** * 构造一个新的空 set,其底层HashMap 实例的默认初始容量是16,加载因子是0.75。 */ public HashSet() { map = new HashMap<E,Object>(); } /** * 构造一个包含指定 collection 中的元素的新 set */ public HashSet(Collection<? extends E> c) { map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } /** * 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。 */ public HashSet(int initialCapacity) { map = new HashMap<E,Object>(initialCapacity); } /** * 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。 */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<E,Object>(initialCapacity, loadFactor); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
抽奖demo
在Java中完成一个抽奖功能,奖品有10种,每人10次中奖机会,然后使用HashSet纪录某个人中奖的奖品类型,使用一个数来记录每个奖品的类型中奖次数
private static final int NUM_PRIZES = 10; private static final int NUM_WINS_PER_PERSON = 10; private static final int[] prizes = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; private static final Set<Integer> winners = new HashSet<>(); private static final int[] prizeCount = new int[NUM_PRIZES]; public static void main(String[] args) { // 模拟抽奖过程 for (int i = 0; i < NUM_WINS_PER_PERSON; i++) { int winner = pickRandomPrize(); winners.add(winner); prizeCount[winner - 1]++; } // 输出中奖者和中奖奖品 System.out.println("中奖者: " + winners); System.out.println("中奖奖品及次数: "); for (int i = 0; i < NUM_PRIZES; i++) { System.out.println("奖品 " + (i + 1) + ": " + prizeCount[i] + " 次"); } } private static int pickRandomPrize() { Random random = new Random(); int prize = prizes[random.nextInt(NUM_PRIZES)]; return prize; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

其使用方式:
-
创建HashSet对象:可以使用无参构造函数创建一个空的HashSet对象,也可以使用带有初始容量和负载因子的构造函数创建一个指定容量和负载因子的HashSet对象。
-
添加元素:使用add()方法向HashSet中添加元素,如果元素已经存在,则不会重复添加。
-
删除元素:使用remove()方法从HashSet中删除指定元素。
-
判断元素是否存在:使用contains()方法判断HashSet中是否包含指定元素。
-
遍历元素:可以使用迭代器或者增强for循环遍历HashSet中的元素。
public static void main(String[] args) { // 创建一个空的HashSet对象 HashSet<String> set = new HashSet<>(); // 添加元素 set.add("apple"); set.add("banana"); set.add("orange"); set.add("pear"); // 判断元素是否存在 System.out.println(set.contains("apple")); // true System.out.println(set.contains("grape")); // false // 删除元素 set.remove("orange"); // 遍历元素 for (String fruit : set) { System.out.println(fruit); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
true
false
banana
pear
apple
注意事项:
- HashSet是基于哈希表(HashMap)实现的。
- 元素存储无序,且再次进行哈希的时候,元素位置可能会发生改变。
- 允许插入Null值。
- 是非同步的,fail-fast机制的。
boolean add(E e):如果此 set 中尚未包含指定元素,则添加指定元素。
public boolean add(E e) {
//元素为key,PRESENT作为value存入HashMap中
return map.put(e, PRESENT)==null;
}
- 1
- 2
- 3
- 4
void clear():从此 set 中移除所有元素。
public void clear() {
map.clear();
}
- 1
- 2
- 3
boolean remove(Object o):如果指定元素存在于此 set 中,则将其移除。
public boolean remove(Object o) {
//通过hashMap移除元素,并匹配value值,判断set是否包含指定元素o
return map.remove(o) == PRESENT;
}
- 1
- 2
- 3
- 4
Iterator iterator():返回对此 set 中元素进行迭代的迭代器。返回元素的顺序并不是特定的。
public Iterator<E> iterator() {
return map.keySet().iterator();
}
- 1
- 2
- 3
boolean contains(Object o):如果此 set 包含指定元素,则返回 true。
public boolean contains(Object o) {
return map.containsKey(o);
}
- 1
- 2
- 3
- 4
TreeSet
TreeSet是基于红黑树实现的,它可以对元素进行排序,时间复杂度为O(log n)。TreeSet中的元素必须实现Comparable接口或者在创建TreeSet时提供一个Comparator比较器,用于对元素进行排序。TreeSet的元素是有序的,因此可以进行一些高级的操作,如范围查找、子集查找等。
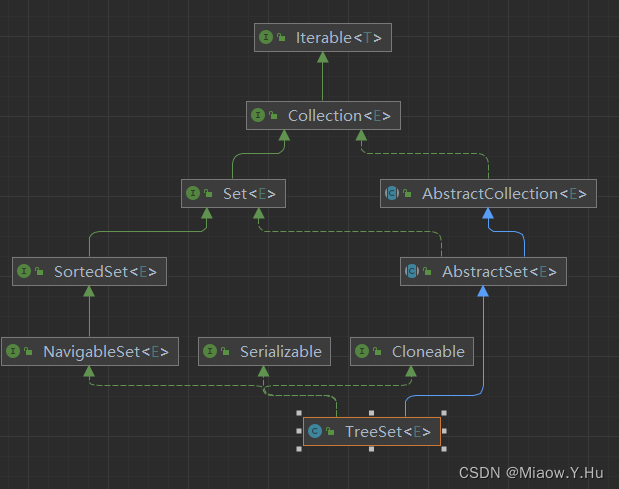
操作方法:
-
创建TreeSet对象:可以使用无参构造函数创建一个空的TreeSet对象,也可以使用带有Comparator比较器的构造函数创建一个指定比较器的TreeSet对象。
-
添加元素:使用add()方法向TreeSet中添加元素,元素会按照排序规则插入到红黑树中。
-
删除元素:使用remove()方法从TreeSet中删除指定元素。
-
获取元素:使用first()方法获取TreeSet中的第一个元素,使用last()方法获取TreeSet中的最后一个元素。
-
获取子集:使用subSet()方法获取TreeSet中的子集,可以指定子集的起始元素和结束元素。
public static void main(String[] args) { // 创建一个空的TreeSet对象 TreeSet<Integer> set = new TreeSet<>(); // 添加元素 set.add(5); set.add(3); set.add(8); set.add(1); set.add(6); // 获取元素 System.out.println("First element: " + set.first()); // 1 System.out.println("Last element: " + set.last()); // 8 // 获取子集 System.out.println("Subset: " + set.subSet(3, 6)); // [3, 5] // 删除元素 set.remove(8); // 遍历元素 for (Integer num : set) { System.out.println(num); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
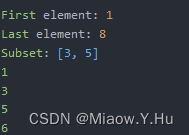
TreeSet中的元素是有序的,而且不允许重复。在上面的示例代码中,我们创建了一个空的TreeSet对象,然后向其中添加了五个元素,分别是5、3、8、1和6。接着,我们使用first()方法获取TreeSet中的第一个元素,使用last()方法获取TreeSet中的最后一个元素,使用subSet()方法获取TreeSet中的子集,使用remove()方法从TreeSet中删除指定元素,最后使用增强for循环遍历TreeSet中的元素。
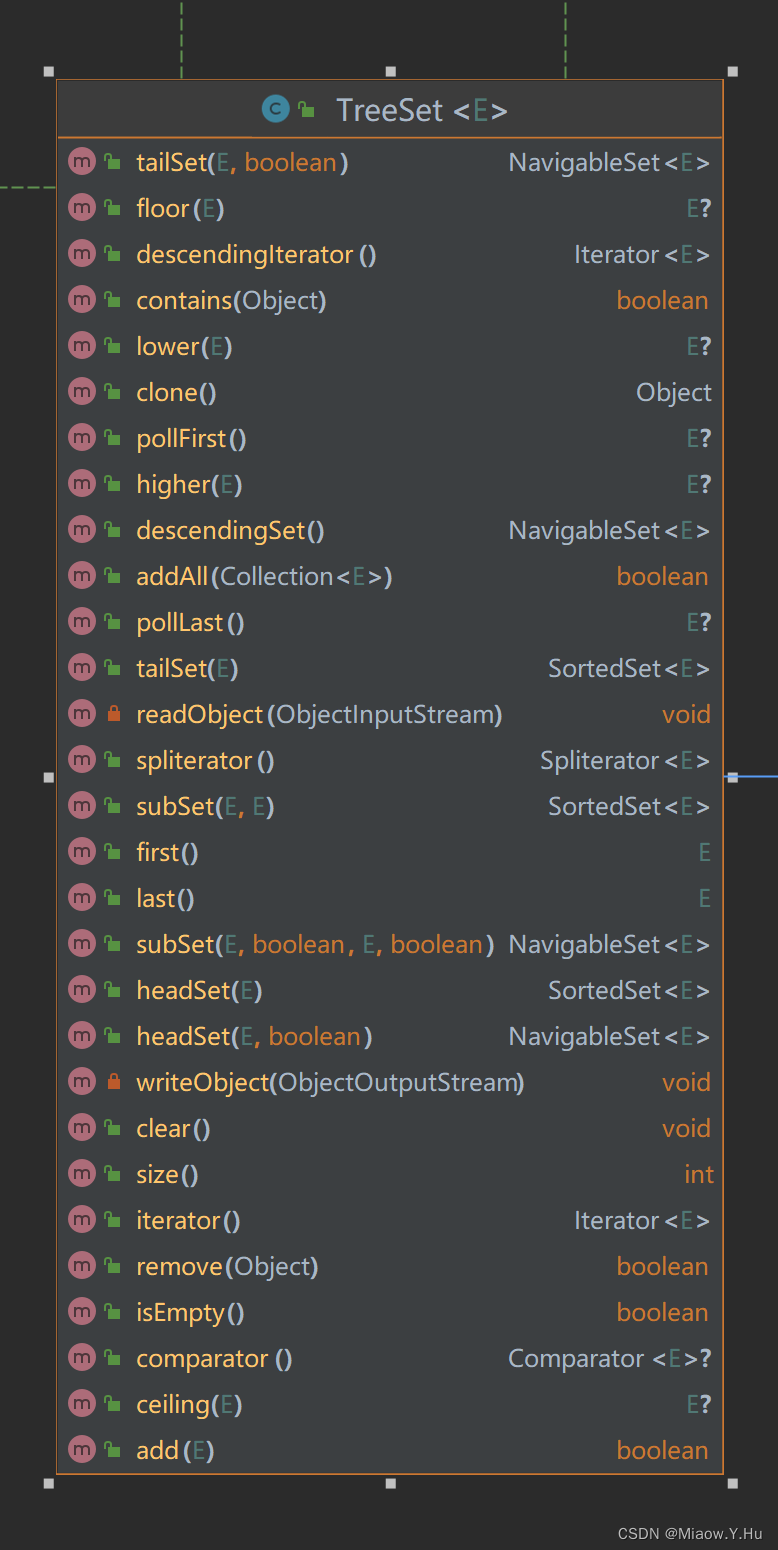
- add(E e):向TreeSet中添加指定元素,如果元素已经存在,则不会重复添加。时间复杂度为O(log n)。
- clear():从TreeSet中删除所有元素。
- contains(Object o):判断TreeSet中是否包含指定元素。
- descendingIterator():返回一个逆序迭代器,用于从后往前遍历TreeSet中的元素。
- descendingSet():返回一个逆序的TreeSet,用于按照逆序遍历TreeSet中的元素。
- first():返回TreeSet中的第一个元素。
- floor(E e):返回小于等于指定元素的最大元素,如果不存在这样的元素,则返回null。
- headSet(E toElement):返回一个子集,包含小于指定元素的所有元素。
- higher(E e):返回大于指定元素的最小元素,如果不存在这样的元素,则返回null。
- isEmpty():判断TreeSet是否为空。
- iterator():返回一个正序迭代器,用于遍历TreeSet中的元素。
- last():返回TreeSet中的最后一个元素。
- lower(E e):返回小于指定元素的最大元素,如果不存在这样的元素,则返回null。
- pollFirst():删除并返回TreeSet中的第一个元素。
- pollLast():删除并返回TreeSet中的最后一个元素。
- remove(Object o):从TreeSet中删除指定元素。
- size():返回TreeSet中元素的个数。
- subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive):返回一个子集,包含从指定元素到另一个指定元素之间的所有元素。
- tailSet(E fromElement):返回一个子集,包含大于等于指定元素的所有元素。
- toArray():将TreeSet中的元素转换为数组。
案例demo,抽奖排序
我们使用TreeSet完成一个抽奖排序功能:
public class LotterySorter { public static void main(String[] args) { // 初始化参与抽奖的人员名单 String[] names = {"Alice", "Bob", "Charlie", "David", "Eva", "Frank", "Grace", "Henry", "Ivy", "Jack"}; // 使用TreeSet存储参与抽奖的人员名单,并按照字典序排序 TreeSet<String> set = new TreeSet<>(); for (String name : names) { set.add(name); } // 随机抽取3名幸运儿,并按照字典序排序 String[] winners = new String[3]; Random random = new Random(); for (int i = 0; i < 3; i++) { int index = random.nextInt(set.size()); winners[i] = (String) set.toArray()[index]; set.remove(winners[i]); } TreeSet<String> sortedWinners = new TreeSet<>(); for (String winner : winners) { sortedWinners.add(winner); } // 输出中奖名单 System.out.println("中奖名单:"); for (String winner : sortedWinners) { System.out.println(winner); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
结语
HashSet和TreeSet的区别如下:
- HashSet是基于哈希表实现的,TreeSet是基于红黑树实现的。
- HashSet不保证元素的顺序,TreeSet中的元素是有序的。
- HashSet的插入、删除和查找操作的时间复杂度为O(1),TreeSet的时间复杂度为O(log n)。
- HashSet中的元素必须实现hashCode()和equals()方法,TreeSet中的元素必须实现Comparable接口或者在创建TreeSet时提供一个Comparator比较器。
- HashSet适用于需要快速插入、删除和查找元素的场景,而TreeSet适用于需要对元素进行排序和高级操作的场景。

