
- 1国家级博览会双重大奖!小米元宇宙与小米机器学习平台cloudML创佳绩
- 2【CPP】CPP的STL(前篇)
- 3Java 性能优化实战工具实践:如何获取代码性能数据?_代码的性能报告除了在代码中插入性能监测代码获取,还可以怎么获取
- 4GitLab: The project you were looking for could not be found. fatal: 无法读取远程仓库。 请确认您有正确的访问权限并且仓库存在。
- 5Hacker专用密码生成器—crunch常见命令使用详解
- 6CURL多线程的严重错误_curl库在多线程中异常
- 7学校管理系统项目——数据架构设计方案_数据库学校管理系统需求概述及简要分析
- 8手把手教你安装和使用NumPy库_numpy库怎么安装
- 9更新升级windows11提示“该电脑必须支持安全启动_游戏需要win11支持安全启动
- 10探索remotemoe:SSH的网络魔法工具
Python基础最详细总结(适合纯小白,博主目前只学了基础,等后面学了高级再补上!!!)_python课程总结
赞
踩
目录
2.多条件判断:if:...elif:...elif:...else:
六、容器:列表(list),元组(tuple),字符串(str),集合(set),字典(dict)
(3)元组的常见方法:因为元组一旦定义了就不能修改,所以只有查!
3.字符串(字符串定义那些前面已经介绍,这里就直接介绍方法了)
一、Python的起源和基本函数
1989年,为了打发圣诞节假期,Gudio van Rossum吉多· 范罗苏姆(龟叔)决心开发一个新的解释程序(Python雏形)
1991年,第一个Python解释器诞生
Python这个名字,来自龟叔所挚爱的电视剧Monty Python's Flying Circus
print函数:print(' 内容')
注:print是一个输出函数,可以把你想要展示的内容打印到控制台上。
input函数:input(' 请输入您的内容:')
注:input是一个输入函数,运行后在控制台上输入内容
二、数据类型的分类、查看、转换
1.数据类型分类
数字:整型(int),浮点型(float),复数(complex),布尔(bool)
字符串(String):用引号引起来的内容如"python"
字符串的三种定义方式
(1)单引号定义
a = '中国'
(2)双引号定义
b = "中国"
(3)三引号定义
c = """
中国
"""
字符串的拓展
字符串拼接:
- name = '李四'
- age = 20
- print(name + '的年龄为' + str(age) + '岁')
字符串占位和精度控制:
- print('%s的年龄为%d岁,身高为%.2f厘米' % (name, age, height))
- 字符串format和精度控制
- print(f'{name}的年龄为{age}岁,身高为{height:.2f}厘米')
字符串五种格式化:
- name = input('请输入姓名:')
- age = int(input('请输入年龄:'))
- weight = float(input('请输入体重:'))
- 1.print打印多个内容:print('姓名:', name, '年龄:', age, '体重:', weight, '公斤')
- 2.字符串拼接:print('姓名:' + name + ',' + '年龄:' + str(age) + ',' + '体重:' + str(weight) + '公斤')
- 3.都用%s占位输出:print('姓名:%s,年龄:%s,体重:%s公斤' % (name, age, weight))
- 4.用%s %d %f占位输出:print('姓名:%s,年龄:%d,体重:%.1f公斤' % (name, age, weight))
- 5.用format输出:print(f'姓名:{name},年龄:{age},体重:{weight:.1f}公斤')
列表(List):有序可重复可修改序列
元组(Tuple):有序可重复不可修改序列
字典(Dictionary):无序键不可重复可修改集合
集合(Set):无序不可重复可修改集合
注意:列表,元组,字典,集合后面会详细介绍。
2.查看数据类型
type():括号内为字面量或变量,如type("中国")或 a = 10,type(a)
3.转换
int():括号内为字面量或变量,只能是数字才能转成整型。
float():括号内为字面量或变量,只能是数字才能转成浮点型。
str(): 括号内为字面量或变量,任何类型都可以。
注意:字面量可以理解为常量,如整形,浮点型,布尔型,字符串。
三、判断语句
1.单条件判断:if:....else:
if是如果,else是否则,缩进4格,每个if里面的每一行要对齐,如果if后面的条件成立,执行内容1,否则执行内容2
if 条件:
内容1
else:
内容2
2.多条件判断:if:...elif:...elif:...else:
- score = int(input('请输入您的分数:'))
- if score >= 90 and score <= 100:
- print('您的成绩等级为优秀')
- elif score >= 70 and score < 90:
- print('您的成绩等级为良好')
- elif score >= 60 and score < 70:
- print('您的成绩等级为及格')
- elif score >= 0 and score < 60:
- print('您的成绩等级为不及格')
- else:
- print('输入有误')
if嵌套使用
- user_yizhi = 'binzi'
- pwd_yizhi = '123456'
- yzm_yizhi = 'qwer'
- # 定义输入的验证码
- yzm_shuru = input('请您输入验证码:')
- if yzm_shuru == yzm_yizhi: # 判断验证码是否正确
- print('验证码正确')
- user_shuru = input('请输入用户名:') # 定义输入的用户名
- pwd_shuru = input('请输入密码:') # 定义输入的密码
- if user_shuru == user_yizhi and pwd_shuru == pwd_yizhi: # 判断用户名和密码是否正确
- print('登陆成功!!!')
- else:
- print('用户名或者密码错误')
- else:
- print('验证码错误,请重新输入')
四、while和for循环
1.while循环
1.初始条件
2.while 条件判断:
3.循环体
4.条件控制
- #打印0-100的数
- = 0
- while i <= 100:
- print(i)
- i += 1
1-100偶数和:
- # 方式一:
- i = 2
- sum = 0
- count = 0
- while i <= 100:
- sum += i
- count += 1
- i += 2
- print(f'1-100的偶数和为{sum}')
- print(f'一共加了{count}次')
- #方式二
- i = 1
- sum = 0
- while i <= 100:
- if i % 2 == 0:
- sum += i
- i += 1
- print(f'1-100的偶数和为{sum}')
 '运行
'运行猜数字案例:
- import random
- suiji = random.randint(1, 100)
- count = 0
- while True:
- cai = int(input('请输入您要猜的数(1-100):'))
- count += 1
- if cai >= 1 and cai <= 100:
- if cai == suiji:
- print('恭喜您,猜中了!!!')
- print(f'您猜的总次数为:{count}次')
- break
- elif cai < suiji:
- print('您猜的数字比随机数小')
- else:
- print('您猜的数字比随机数大')
- else:
- print('您输入的数不在范围内,请重新输入:')
九九乘法表:
- i = 1
- j = 1
- while i <= 9:
- while j <= i:
- print(f'{i}*{j}={i * j}', end='\t')
- j += 1
- print()
- j = 1
- i += 1
2.for循环
#for 临时变量 in 可迭代对象:
循环体
for i in range(x,y,z)#x为左区间,y为右区间(不包含y本身),z为步长
统计字符串里面a出现的次数:
- count = 0
- zifu = "itheima is a brand of itcast"
- for i in zifu:
- if i == 'a':
- count += 1
- print(f'itheima is a brand of itcast中含有{count}个a')
九九乘法表:
- #九九乘法表:
- for i in range(1, 10):
- for j in range(1,i+1):
- print(f'{i}*{j}={i * j}',end='\t')
- print()
五、函数
1.概念:
组织好的,可重复使用的,用来实现特定功能的代码段
2.定义:
def 函数名(传入参数):
函数体
return 返回值
- def get_sum(a,b,c,d):#a,b,c,d为形式参数
- sum = a + b + c + d
- return sum #返回值为sum
- s=get_sum(10,20,10,20)#10,20为实际参数
- print(f'10,20,10,20的和为:{s}')
函数嵌套:在一个函数定义中调用另一个函数
- def show1():
- print('黄智欣')
- def show2():
- show1()
- print('24岁')
- print('手机号:18988849948')
- show2()
3.函数注意事项:
1.先定义函数,再调用函数
2.函数调用1次,执行一次
3.定义有参数的函数调用时必须传入参数
4.有返回值的函数调用时尽量用变量接收返回值
5.函数没有返回值默认为return None
5.返回值为None的时候直接调用函数就行,不用变量接受和print打印,不然打印出来就是None
4.全局变量和局部变量
全局变量:所有函数内和函数外都可以使用的变量
局部变量:只能在某个函数内使用的变量
- a = 10
- def show1():
- global a #声明为全局变量,没有的话为局部变量
- a = 20
- print('黄智欣')
- print(a)
-
- def show2():
- show1()
- print('24岁')
- print('手机号:18988849948')
- print(a)
-
- show2()
- show1()
- print(a)
5.函数进阶
1.多个返回值
return:
主职:结束当前函数
兼职:顺带把return后面的值返回到调用处
- def func():
- return [1, 2, 3, 4, 5]
-
- t = func()
- print(t,type(t))
2.多种命名参数:形式参数,实际参数
位置参数:实际参数和形式参数个数和顺序必须一致
- def func1(name, age, height):
- print(f'{name}的年龄是{age},身高是{height}cm')
- func1('张三', 18, 178)
- func1('李四', 19, 188)
关键字参数:实际参数和形式参数个数必须一致,顺序可以不一致
- def func1(name, age, height):
- print(f'{name}的年龄是{age},身高是{height}cm')
- func1(age=18, name='张三', height=188.8)
位置参数和关键字参数混合使用
func1('张三', height=188.8, age=18)
缺省参数:可以给形参提前设置默认值,实参和形参个数可以不一致
- def func1(name, age=18, height=188):
- print(f'{name}的年龄是{age},身高是{height}cm')
-
- func1('张三',age=18)
可变参数:*接收一个参数返回元组,args名字可以修改,**kwargs接收一对参数返回字典,kwargs名字可以修改
- def func1(*args,**kwargs):
- print(args,type(args))
- print(kwargs,type(kwargs))
- func1('张三',18,height=178,weight=55)
六、容器:列表(list),元组(tuple),字符串(str),集合(set),字典(dict)
1.列表
(1)列表的定义
变量名 = [元素1,元素2,元素3]
变量名 = list((元素1,元素2,元素3))
(2)列表的下标索引
列表正索引:从左往右,从0依次递增
列表负索引:左右往左,从-1一次递减
列表名[索引号]:name_list[0]
列表嵌套索引:
列表名[索引号][索引号]:list1[0][0]
(3)列表的常见方法:增删改查
append:每次在列表最后添加一个元素
- name_list = []
- name_list.append('张三')
- print(name_list)
- 结果为:['张三']
insert:在指定下标处,插入指定的元素
- name_list = []
- name_list.append('张三')
- print(name_list)
-
- name_list.extend(['李四','王五'])
- print(name_list)
-
- name_list.insert(0,'小二')
- print(name_list)
- 结果为:['小二', '张三', '李四', '王五']
del:删除列表指定下标元素
- name_list = []
- name_list.append('张三')
- print(name_list)
-
- name_list.extend(['李四','王五'])
- print(name_list)
-
- name_list.insert(0,'小二')
- print(name_list)
-
- del name_list[-1]
- print(name_list)
- 结果为:['小二', '张三', '李四']
pop:删除列表指定下标元素
- name_list = []
- name_list.append('张三')
- print(name_list)
-
- name_list.extend(['李四','王五'])
- print(name_list)
-
- name_list.insert(0,'小二')
- print(name_list)
-
- name_list.pop(0)
- print(name_list)
- 结果为:['张三', '李四']
remove:从前往后,删除此元素第一个匹配项
- name_list = []
- name_list.append('张三')
- print(name_list)
-
- name_list.extend(['李四','王五'])
- print(name_list)
-
- name_list.insert(0,'小二')
- print(name_list)
-
- del name_list[-1]
- print(name_list)
-
- name_list.pop(0)
- print(name_list)
-
- name_list.remove('李四')
- print(name_list)
- 结果为:['张三']
clear:清空列表
- name_list = []
- name_list.append('张三')
- print(name_list)
-
- name_list.extend(['李四','王五'])
- print(name_list)
-
- name_list.insert(0,'小二')
- print(name_list)
-
- del name_list[-1]
- print(name_list)
-
- name_list.pop(0)
- print(name_list)
-
- name_list.remove('李四')
- print(name_list)
-
- name_list.clear()
- print(name_list)
- 结果为:[]
修改列表中的元素
- name_list = ['张三','李四','王五','王五','赵六']
- print(name_list)
-
- name_list[0] = '熊大'
- print(name_list)
-
- name_list[1] = '熊二'
- print(name_list)
- 结果为:['熊大', '熊二', '王五', '王五','赵六']
count:统计此元素在列表中出现的次数
- name_list = ['张三','李四','王五','王五','赵六']
- print(name_list)
-
- name_list[0] = '熊大'
- print(name_list)
-
- name_list[1] = '熊二'
- print(name_list)
-
- count = name_list.count('王五')
- print(f'王五在列表出现的次数为:{count}次')
- 结果为:王五在列表出现的次数为:2次
index:查找指定元素在列表的下标
- name_list = ['张三','李四','王五','王五','赵六']
- print(name_list)
-
- name_list[0] = '熊大'
- print(name_list)
-
- name_list[1] = '熊二'
- print(name_list)
-
- count = name_list.count('王五')
- print(count)
-
- index = name_list.index('赵六')
- print(f'赵六元素在列表中的索引为:{index}')
- 结果为:赵六元素在列表中的索引为:4
len:统计容器中有多少个元素
- name_list = ['张三','李四','王五','王五','赵六']
- print(name_list)
-
- name_list[0] = '熊大'
- print(name_list)
-
- name_list[1] = '熊二'
- print(name_list)
-
- count = name_list.count('王五')
- print(f'王五在列表出现的次数为:{count}次')
-
- index = name_list.index('赵六')
- print(f'赵六元素在列表中的索引为:{index}')
-
- ll = len(name_list)
- print(f'该列表一共有{ll}个元素')
- 结果为:该列表一共有5个元素
(4)列表的特点
1.可以容纳多个元素
2.可以容纳不同类型的元素
3.数据是有序存储的
4.允许重复数据存在
5.可以修改
2.元组
(1)元组的最大特点
元组一旦定义,不能被修改!!!!!!!
(2)元组的定义
变量名 = ()
变量名 = tuple()
注意:元组只有一一个数据的时候,需要在这个数据后面添加一个逗号,如果不加就是普通变量
t2 = ('Hello',)
(3)元组的常见方法:因为元组一旦定义了就不能修改,所以只有查!
count:统计此元素在元组中出现的次数:
- name_tuple = ['张三', '李四', '王五', '王五', '赵六']
- print(name_tuple)
-
- count = name_tuple.count('王五')
- print(f'王五在元组中出现的次数为{count}次')
- 结果为:王五在元组中出现的次数为2次
index:查找指定元素在元组的下标
- name_tuple = ['张三', '李四', '王五', '王五', '赵六']
- print(name_tuple)
-
- count = name_tuple.count('王五')
- print(f'王五在元组中出现的次数为{count}次')
-
- index = name_tuple.index('赵六')
- print(f'赵六在元组中的索引为:{index}')
- 结果为:赵六在元组中的索引为:4
len:统计容器中有多少个元素
- name_tuple = ['张三', '李四', '王五', '王五', '赵六']
- print(name_tuple)
-
- count = name_tuple.count('王五')
- print(f'王五在元组中出现的次数为{count}次')
-
- index = name_tuple.index('赵六')
- print(f'赵六在元组中的索引为:{index}')
-
- ll = len(name_tuple)
- print(f'{name_tuple}中一共有{ll}个元素')
- 结果为:['张三', '李四', '王五', '王五', '赵六']中一共有5个元素
(4)元组的特点
1.可以容纳多个数据
2.可以容纳不同类型的数据
3.数据是有序存储的
4.允许重复数据存在
5.不可以修改
3.字符串(字符串定义那些前面已经介绍,这里就直接介绍方法了)
(1)字符串的常见方法
count:统计此元素在字符串中出现的次数
- str1 = '黑马程序员是传智旗下线下教育品牌'
- print(str1.count('下'))
- 结果为:2
index:查找指定元素在字符串的下标
- str1 = '黑马程序员是传智旗下线下教育品牌'
- print(str1.index('下'))
- 结果为:9
len:统计容器中有多少个元素
- str1 = '黑马程序员是传智旗下线下教育品牌'
- print(len(str1))
- 结果为:16
(2)字符串的特定方法
replace:将一个字符替换字符串中的某个字符
- s1 = '你TMD哦,我TMD真相刀你!'
- new_s1 = s1.replace('TMD', '挺萌的')
- print(new_s1)
- 结果为:你挺萌的哦,我挺萌的真相刀你!
split:根据分隔符来将字符串进行分割,然后存到一个列表中
- s2 = '苹果-梨-香蕉-火龙果-榴莲'
- new_s2=s2.split('-')
- print(new_s2)
- 结果为:['苹果', '梨', '香蕉', '火龙果', '榴莲']
join:通过一个字符将各个字符拼接在一起
- s2 = '苹果-梨-香蕉-火龙果-榴莲'
- new_s2=s2.split('-')
- s3 = '^'.join(new_s2)
- print(s3)
- 结果为:苹果^梨^香蕉^火龙果^榴莲
strip:清楚字符串左右两边的空格
- s4 = ' 张三 '
- print(s4)
- new_s4 = s4.strip()
- print(new_s4)
- 结果为:张三
startswith,endswith:以...开始,以...结束
- name_list = ['张三','张三丰','王五','王老五','赵六','赵子龙']
- for name in name_list:
- if name.startswith('张'):
- print(name)
- if name.endswith('五'):
- print(name)
- 结果为:
- 张三
- 张三丰
- 王五
- 王老五
upper,lower:把字母全部变成大写,小写
- #upper
- s5 = 'aBcDeFgH'
- s6 = s5.upper()
- print(s6)
- 结果为:ABCDEFGH
- #lower
- s5 = 'aBcDeFgH'
- s7 = s5.lower()
- print(s7)
- 结果为:abcdefgh
(3)字符串的特点
1.可以容纳多个数据
2.只能存储字符串类型数据
3.数据是有序存储的
4.允许重复数据存在
5.不可以修改
4.集合
(1)集合的定义
定义空集合
s1 = set()
print(s1,type(s1))
注意:定义空集合不能使用{},因为{}代表空字典
#定义非空集合
s2 = {'a','b','c','d','e'}
print(s2,type(s2))
注:不想元素重复可以用集合来去重!!!
(2)集合的常见方法
集合的增删操作:
- #需求:定义空集合
- s1 = set()
- #需求2:给集合添加元素
- s1.add('张三')
- s1.add('李四')
- s1.add('王五')
- s1.add('赵六')
- s1.add('田七')
- print(s1)
- #删除集合中的张三
- s1.remove('张三')
- print(s1)
- #随机删除一个元素
- s1.pop()
- print(s1)
- #清空元素
- s1.clear()
- print(s1)
集合的改查操作:
- #定义两个非空集合分别存储123,146
- s1 = {1,2,3}
- s2 = {1,4,6}
- #difference:s1中有,s2中没有的元素,生成新集合
- s3 = s1.difference(s2)
- print(s3)
- #difference_update:取s1和s2的交集,修改了s1集合
- s1.difference_update(s2)
- print(s1)
- #update:取s1和s2的并集,修改了s1集合
- s1.update(s2)
- print(s1)
-
- #union:取出s1和s2的元素并组成新集合
- s4 = s1.union(s2)
- print(s1)
(3)集合的特点
1.可以容纳多个数据
2.可以存储任何类型数据
3.数据是无序存储的
4.不允许重复数据存在
5.可以修改
1.可以容纳多个数据 2.可以存储任何类型数据 3.数据是无序存储的 4.不允许重复数据存在 5.可以修改
5.字典
(1)字典的定义
- my_dict = {}
- my_dict = dict()
- dict1 = {'张三':18,'李四':28,'王五':38,'赵六':48}
- print(dict1,type(dict1))
- #字典嵌套
- student_dict = {
- '张三': {'语文': 100, '数学': 34, '外语': 18},
- '李四': {'语文': 98, '数学': 37, '外语': 57},
- '王五': {'语文': 80, '数学': 94, '外语': 78}
- }
(2)字典的常用操作
增加和修改:
- stu_info = {'张三': 28, '李四': 28, '赵六': 48}
- stu_info['王五'] = 38
- print(stu_info)
- stu_info['王五'] = 30
- print(stu_info)
删除:
- stu_info = {'张三': 28, '李四': 28,'王五':38, '赵六': 48}
- print(stu_info)
-
- stu_info.pop('王五')
- print(stu_info)
-
- del stu_info['赵六']
- print(stu_info)
-
- stu_info.clear()
- print(stu_info)
查询:
- stu_info = {'张三': 28, '李四': 28,'王五':38, '赵六': 48}
- print(stu_info)
-
- print(stu_info['李四'])
-
- print(len(stu_info)) #计算字典有多少键值对
-
- print(stu_info.keys()) #将字典中的所有键取出来存到一个列表中
-
- print(stu_info.values()) #将字典中的所有键的值取出来存到一个列表中
-
- print(stu_info.items()) #将字典中的每个键值对的键和值取出来存到一个元组中,最后再放到一个列表中
(3)字典的特点
1.可以容纳多个数据
2.可以存储任何类型数据
3.数据是没有具体顺序,主要根据键找值
4.不允许键重复
5.可以修改
6.五种容器对比
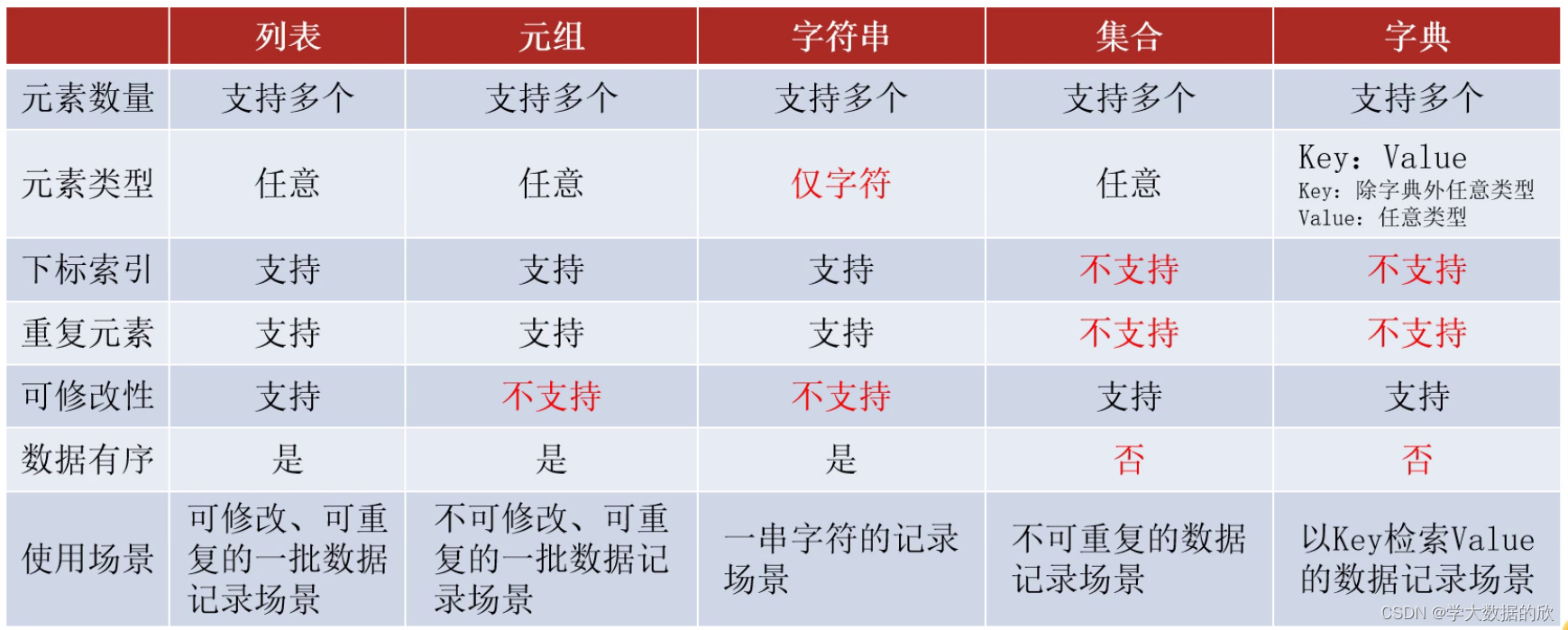
七、文件操作
1.文件的打开和关闭
- """
- open(): 如果报FileNotFoundError,文件没找到,要么文件路径写错了,要么文件确实没有
- 参数1-> 路径: 相对路径: 不以盘符开始的路径 绝对路径: 以盘符开始的路径
- 参数2->横式:默认r式: 如果文件不存在就报错 w和a式: 如果文件不存在,自动创建
- 参数3->编码: 默认cp936,本质就是gbk,一般编码都会使用utf8
- """
- f = open('w1.txt',mode='a')
- print(f)
-
- #关闭文件
- f.close()
2.文件的读写和写入
- #文件读取
- #一个个的读
- f = open('w1.txt',mode='r',encoding='utf8')
- data = f.read(7)
- print(data)
- #接着读后面的字符
- data = f.read(6)
- print(data)
- #一个个读剩余所有的字符
- data = f.read()
- print(data)
- f.close()
- #一行行的读
- f = open('w1.txt',mode='r',encoding='utf8')
- data = f.readline()
- print(data)
-
- datas = f.readlines()
- print(datas)
-
- for line in datas:
- print(line,end='')
- f.close()
- #文件的写入
- f = open('w2.txt',mode='w',encoding='utf8')
-
- f.write('hello!python\nHi!PyCharm\n')
-
- f.close()

