
- 1JESD204B参数说明与计算_204b lmfs
- 2Python操作SQLite介绍_python sqlite
- 3【Sentinel限流与降级】Sentinel入门与实战_awesome sentinel
- 4一张照片,AI生成抽象画(CLIPasso项目安装使用) | 机器学习_抽象画生成
- 5centos7中每天定时备份mysql数据库_centos 定时备份多个mysql数据库
- 6Python GUI框架---- PySide6安装与使用 - 打包部署
- 7引领未来:在【PyCharm】中利用【机器学习】与【支持向量机】实现高效【图像识别】_支持向量机回归模型 预测 pycharm
- 8【Git】gitlab复制已有项目、删除项目_gitlab复制项目
- 9CentOS7 搭建 pxe 环境,安装UOS_uos pxe
- 10C++并发编程(七)无锁数据结构_c++ 无锁编程
论文分享——Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
赞
踩
文章简介
文章发表于CPVR 2018,成为经典范式
1、背景介绍
研究背景

随着NLP和CV领域技术的发展,视觉和文本数据融合的多模态技术逐渐引起重视,如图片描述( image captioning [4],IC)和视觉问答(visual question answering (VQA) [12] )等。
概念介绍
Image caption的任务就是给定机器一张图片让机器感知图像中的物体并捕捉它们的联系,然后生成一段描述性的语言。
Visual question answering是指给定一张图片及其相关问题,根据图片信息做出相应回答。
问题描述

IC与VQA领域的主要挑战
-
评价指标不准确:由于该领域评价非常困难与主观,而且该领域的自动评价指标许多是照搬机器翻译领域的,与人工评价仍有诸多不符。
-
数据量大,训练困难:该领域涉及CV和NLP,需要大量的数据进行神经网络的训练,这对于机器资源和训练时间有一定的要求。
-
描述局限性:对应的描述风格单一,对图片的描述不够详尽以至于遗漏关键信息,描述的语言和背景单一等等。
2、相关研究
CNN+RNN体系架构
IC领域借鉴了机器翻译领域的Encoder-Decoder架构,即使用CNN提取图像特征喂给RNN,后者再根据这些图像信息以及其它额外信息生成对应的文字。
由于RNN无法处理较长上下文的信息,而且还会出现梯度消失或者梯度爆炸的情况,所以LSTM后来被引进替代RNN。

但是图像中的不同内容对于caption中的各个词的贡献是不同的,人们更关心那些重要的关键词,所以之后Attention机制又被引入,这也是本文涉及的主要内容。
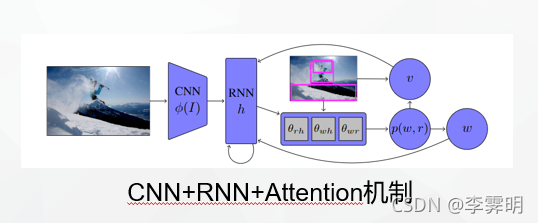
Attention mechanism
注意力模型(AM)最初被用于机器翻译[Bahdanau et al., 2014],现在已成为神经网络领域的一个重要概念。注意力机制可以利用人类视觉机制进行直观解释。例如,我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息[Xu et al., 2015]。
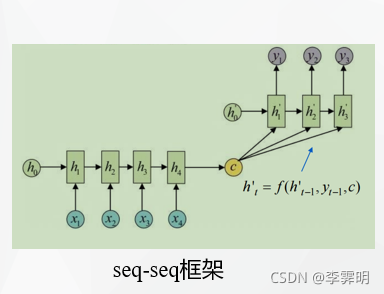
sequence-to-sequence模型由编码器-解码器体系结构[Cho et al., 2014b]组成,这种架构在机器翻译领域很流行,但是存在一些问题:定长的中间向量c限制了模型性能;输入序列的不同部分对于输出序列的重要性不同。
之后注意力机制被引用解决这些问题。解码器中的每个时刻不是输入固定的c,而是输入不同的ci;每个时刻的c自动选取与当前输出最相关的上下文。
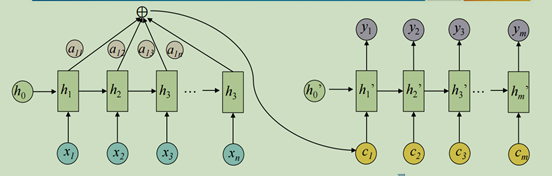
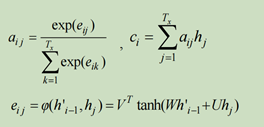
C是语义编码,权重aij表示target输出第i个单词yi时source输入句子中第j个单词xj的注意力分配系数;hj是source输入句子中第j个单词的语义编码;Tx表示句子长度;
计算每个hj对于hi‘的影响程度eij并归一化得aij
Bottom-Up and Top-Down Attention
Top-down attention由当前任务所决定,它会根据当前任务(生成caption或者是VQA中的问题),聚焦于与任务紧密相关的部分。Bottom-up attention指的是我们会被显著的、突出的、新奇的事物给吸引。
以前的方法用到的visual attention mechanisms大都属于top-down类型,即取问题作为输入,建模attention分布,然后作用于CNN提取的图像特征(image features)。然而,这种方法的attention作用的图像对应于下图的左图,没有考虑图片的内容。对于人类来说,注意力会更加集中于图片的目标或其他显著区域,所以作者引进Bottom-up attention机制,如下图的右图所示,attention用于object proposal。

Bottom-Up Attention
本文采用Faster R-CNN [33]来实现Bottom-Up attention机制,Faster R-CNN 是一种object detection模型,旨在识别属于某些类的对象实例并使用边界框对其进行定位。 Top-down的机制使用特定于任务的上下文来预测图像区域上的注意力分布。然后将参与的特征向量计算为所有区域的图像特征的加权平均值。
这篇工作中,采用基于ResNet-101 [14] 的Faster R-CNN 来提取图像特征,然后采用NMS对候选框进行筛选,此处Faster R-CNN 发挥着‘hard’ attention的作用,从大量的边界框中选择了少部分值得特别注意的候选框,大大减轻了后续模型处理的难度。相应的模型参数使用在ImageNet [38]上的分类模型参数进行初始化,然后再在Visual Genome数据库 [47]上进行微调。
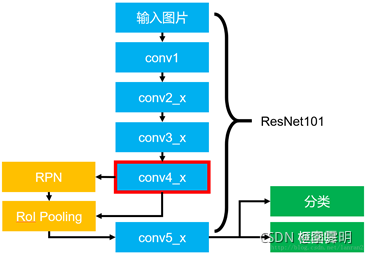
Bottom-Up and Top-Down Attention
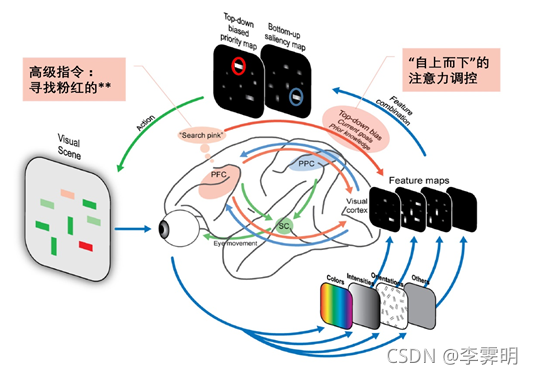
“自下而上”(bottom-up)和“自上而下”(top-down)的注意力调控途径示意图。蓝色、红色和绿色的箭头分别表示”自下而上”、”自上而下”的信号处理通路和眼睛运动相关的信号传递过程。注意力的认知神经机制是什么? - 东华君的回答 - 知乎 https://www.zhihu.com/question/33183603/answer/150792028
Faster RCNN
Faster RCNN于16年被提出,它是该系列的集大成者,将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中使得综合性能有较大提高,在检测速度方面尤为明显。
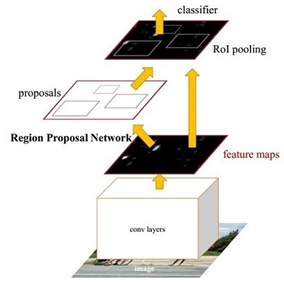
Faster RCNN基本结构如图所示。
- Conv layers。Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
3、本文方法
Overview of the proposed captioning model

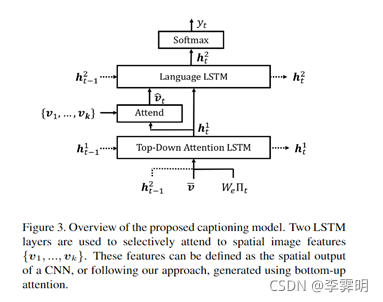


Overview of the proposed VQA Model
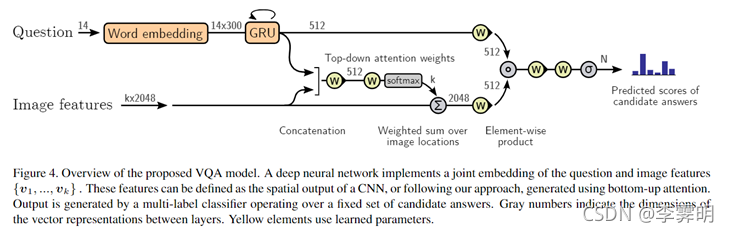

4、实验
Datasets & Metrics
Visual Genome[47] Dataset:该数据集包含108K图像,使用包含对象、属性和关系的场景图进行密集注释,以及170万个视觉问题答案。该数据集在文中主要用来预训练bottom-up attention model以及在训练VQA模型时进行数据增强。
Image Caption:
MS-COCO captions 数据集 [23] 的‘Karpathy’ splits [19]版本:此拆分包含 113,287 个训练图像,每个图像带有 5 个标题,并且分别包含 5K 个用于验证和测试的图像。
Image caption的自动衡量指标有
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

