
- 1Ncnn框架在c++的推理及其认识
- 2UCAS - AI学院 - 自然语言处理专项课 - 第9讲 - 课程笔记_情景语义学 场景变量
- 3vue Tesseract的 ocr 文字识别_vue图片识别文字
- 4突破编程界限:探索AI编程新境界_comate和通义灵码
- 5数据结构:树(Tree)【详解】_数据结构 树
- 6毕业设计 基于stm32的RFID与指纹识别的门禁系统 (项目开源)_基于rfid的门禁系统设计
- 7TypeScript的静态类型_ts全局静态变量
- 8【射影几何06】齐次坐标下“点-线”几何表示_射影几何中的坐标怎么求
- 9Unity背景模糊图片高斯模糊高性能的实现方案_unity高斯模糊
- 10信息学奥赛一本通 1981:【18NOIP普及组】对称二叉树 | 洛谷 P5018【NOIP2018 普及组】 对称二叉树_p5018 [noip2018 普及组] 对称二叉树
【大数据 复习】第7章 MapReduce(重中之重)(含编程题)_使用mapreduce完成对下表中及格同学
赞
踩
一、概念
1.MapReduce 设计就是“计算向数据靠拢”(也就是拿到数据就计算),而不是“数据向计算靠拢”,因为移动,数据需要大量的网络传输开销。
2.Hadoop MapReduce是分布式并行编程模型MapReduce的开源实现。
3.MapReduce也是用来处理数据的。
4.MapReduce处理海量数据时,中间数据存储在磁盘中。
3.特点
(1)非共享式,容错性好。
(2)普通PC机,便宜,扩展性好。
(3)只有what,没有how,简单。
(4)使用场景:批处理、非实时、数据密集型。
4.MapReduce 采用“分而治之”策略
一个存储在分布式文件系统中的 大规模数据集,会被切分成许多独立的分片 (split), 这些分片可以被多个Map 任务并行处理。
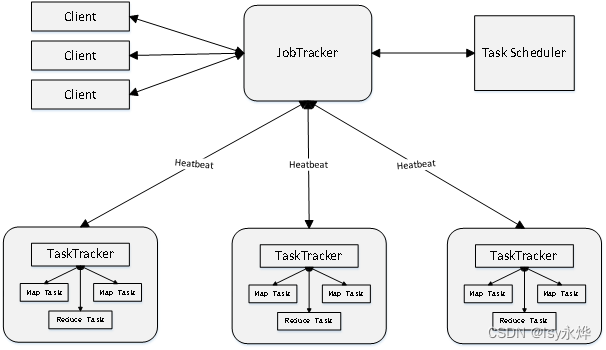
5.MapReduce 1.0体系结构
(1)Hadoop MapReduce采用Master/Slave结构。
Master:是整个集群的唯一的全局管理者,功能是作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。
Slave:负责任务的执行和任务状态的报告,即MapReduce中的TaskTracker。
(2)MapReduce体系结构主要由四个部分组成,分别是: Client 、JobTracker 、TaskTracker 以及Task。
(3)TaskTracker是JobTracker和Task(在下图最下面的看不清的那部分)之间的桥梁:
(4)JobTracker负责:
a.负责资源监控和作业调度
b.监控所有TaskTracker与Job的健康状况
c.跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度(TaskScheduler)。
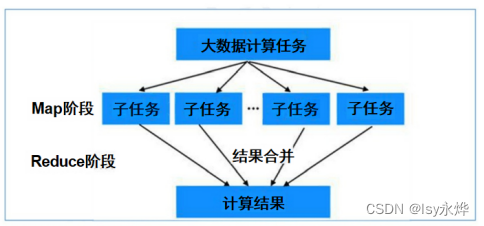
6.map函数和reduce函数:(重中之重)
(1)map接收原始的键值对进行一层处理,然后reduce只接受处理过的键值对,进行二次处理,大致流程如下:
(2)可以连着使用:
Map是映射,负责数据的过滤分法,将原始数据转化为键值对;
Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
(3)Map 和Reduce操作需要我们自己定义相应Map 类和Reduce 类,而shuffle则是系统自动帮我们实现的。
(4)shuffle可以简单的理解为map的售后,但是同样是reduce的“售前”。
在map端主要是写入缓存,溢写操作,合并操作。
而reduce端主要是询问shuffle“前辈”,那个map的任务完成了吗,其中如果溢写了就帮reduce提前归并好然后发给reduce。
7.slot
(1)是执行 Map 或 Reduce 任务的计算资源单位。
(2)Map slot 用于处理输入数据的切片并生成中间结果,而 Reduce slot 则用于处理中间结果并生成最终输出。
(3)每个节点都有一定数量的 Map slot 和 Reduce slot,它们的数量可以根据集群配置和需求动态分配。
(4)有效地利用这些 slot 可以提升 MapReduce 作业的执行效率和性能。
二、习题
主观题
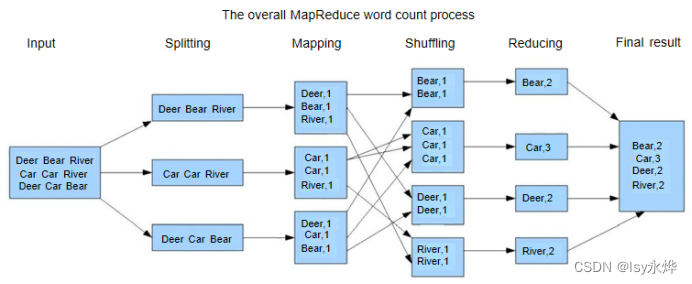
1. 试画出使用MapReduce对英语段落 ”Whatever is worth doing best Whatever is worth doing well”进行单词统计过程
答:
(1)Map阶段:
Mapper将输入的英语段落按照空格分割为单词,并对每个单词生成一个键值对,其中键为单词,值为1。
输入: "Whatever is worth doing best Whatever is worth doing well"
输出中间键值对:
(Whatever, 1), (is, 1), (worth, 1), (doing, 1), (best, 1), (Whatever, 1), (is, 1), (worth, 1), (doing, 1), (well, 1)
(2)Shuffle阶段:
对中间键值对按照键进行排序和分组,键值对会被组织成如下形式:
输入中间键值对:
(Whatever, [1, 1]), (best, [1]), (doing, [1, 1]), (is, [1, 1]), (well, [1]), (worth, [1, 1])
(3) Reduce阶段:
Reducer对每个单词的键值对进行聚合,计算每个单词出现的总次数。
输入中间键值对:
(Whatever, [1, 1]), (best, [1]), (doing, [1, 1]), (is, [1, 1]), (well, [1]), (worth, [1, 1])
输出最终结果:
(Whatever, 2), (best, 1), (doing, 2), (is, 2), (well, 1), (worth, 2)



其实就是Text,Intwritabe,Longwritable都是Hadoop内置的数据类型,然后就是弄懂Iterator是个迭代器。
其次就是明确任务就是让次数改变,出现相同的+1,所以就有了for(循环函数),其中就是(起始,判断条件,执行函数)循环体。
4. 使用MapReduce完成对下表中及格同学的筛选,描述编程设计实现过程(文字描述即可,不用写代码)。
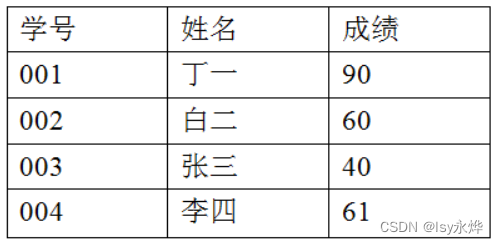
答:
(1)Map阶段:
Mapper函数读取每一行学生记录,将学号和成绩作为输入。
对于每个学生记录,Mapper检查成绩是否及格(大于等于60分)。
如果成绩及格,Mapper输出键值对(学号,成绩)。
(2)Shuffle阶段
中间结果根据学号进行排序和分组,以便后续Reduce阶段对每个学生的成绩进行聚合处理。
(3)Reduce阶段:
Reducer接收每个学生的学号和成绩列表,输出每个学号和成绩。
总感觉reduce啥也没干。。。。。
7.分析描述Shuffle的执行过程。
答:
(1)Map任务输出:Map任务生成键值对,并根据键的哈希值将其分区。
(2)本地排序:每个分区的键值对在本地磁盘上按键排序。
(3)数据传输:将map数据传输给reduce。
(4) 数据合并:Reduce任务将拉取到的数据进行合并,准备进行Reduce处理。
单选题
2. Shuffle过程不包括下列哪个过程?()
A. 分区
B. 排序
C. 合并归并
D. 切分
正确答案:D
切分应该是map干的吧,虽然没说
3. Map和Reduce函数都是以( )作为输入。
A. Key
B. Text
C. 键值对
D. 文件块
正确答案:C
5. Reduce函数的任务是()
A. 通过Hash函数对数据进行排序
B. 对数据进行分区
C. 将输入的一系列具有相同Key的键值对以某种方式组合起来,输出处理后的键值对
D. 对数据进行解析得到键值对
正确答案:C
1.MapReduce的核心思想是 ( )
A. 分而治之
B. 流计算
C. 分布式存储
D. 批处理
正确答案: A
2.MapReduce处理海量数据的时候,中间数据存储在()
A. 内存
B. 磁盘
C. ResourceManager
D. Container
正确答案: B
3.属于MapReduce的设计理念的是。()
A. 数据向计算靠拢
B. 自行进行工作调度
C. 计算向数据靠拢
D. 无需负载均衡
正确答案: C
4.Map函数将输入的元素转换成键值对,下列说法不正确的是( )
A. 一个Map函数只能转换出一个键值对
B. Map转换出的键没有唯一性
C. 同一输入元素,可以通过一个Map任务生成具有相同键的多个键值对
D. 键不可以作为输出的身份标识
正确答案: A
5.每个MapReduce程序都需要一个()
A. Task
B. Partitioner
C. Job
D. Combiner
正确答案: C
多选题
6. 编写MapReduce程序时,()。
A. 编写Map处理逻辑
B. 编写Reduce处理逻辑
C. 编写main方法
D. 提前生成输出文件夹
正确答案:A,B,C

