
热门标签
热门文章
- 1STM32 学习记录一:初识STM32_普中的stm32和正点的区别
- 2软件-vscode-plantUML-IDEA
- 3国产版Sora复现——智谱AI开源CogVideoX-2b 本地部署复现实践教程_cogvideo 部署
- 4Qwen2 -微调 Qwen2_qwen2 微调
- 5HBase与Hive:数据仓库和OLAP
- 6数据结构循环顺序队列的入队出队代码实现7.22(分文件 c语言)_循环顺序队列函数实现指定入队元素个数
- 7jpa mysql_Spring boot通过JPA访问MySQL数据库
- 8Element-ui container常见布局_body > .el-container
- 9sqlserver 数据误删除恢复_sqlserver数据库删了怎么恢复
- 10文本搜索系统的评估_搜索评估是做什么
当前位置: article > 正文
Spark MLlib 特征工程(下)_特征工程输出向量
作者:小惠珠哦 | 2024-08-18 11:00:48
赞
踩
特征工程输出向量
Spark MLlib 特征工程(下)
前面我们提到,典型的特征工程包含如下几个环节,即预处理、特征选择、归一化、离散化、Embedding 和向量计算,如下图所示。
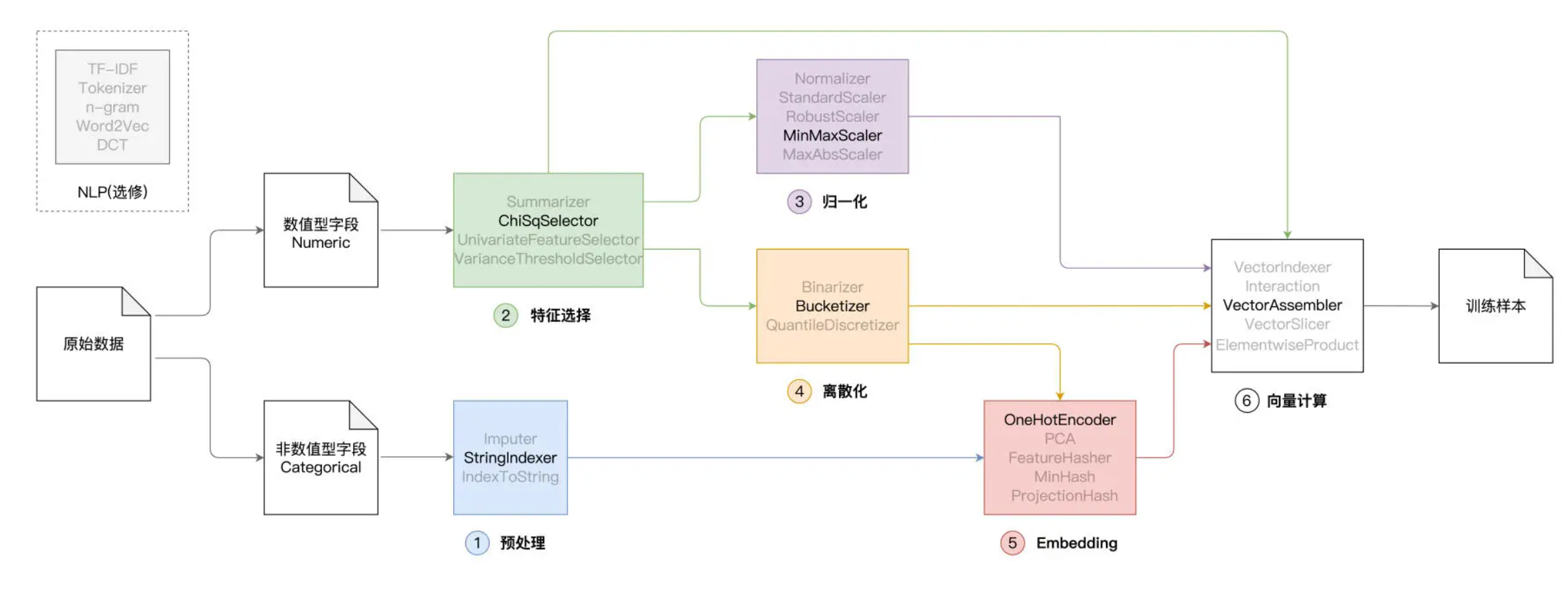
在上一讲,我们着重讲解了其中的前 3 个环节,也就是预处理、特征选择和归一化,今天这一讲,咱们继续来说说剩下的离散化、Embedding 与向量计算。
特征工程
离散化:Bucketizer
与归一化一样,离散化也是用来处理数值型字段的。离散化可以把原本连续的数值打散,从而降低原始数据的多样性(Cardinality)。举例来说,“BedroomAbvGr”字段的含义是居室数量,在 train.csv 这份数据样本中,“BedroomAbvGr”包含从 1 到 8 的连续整数。
现在,我们根据居室数量,把房屋粗略地划分为小户型、中户型和大户型
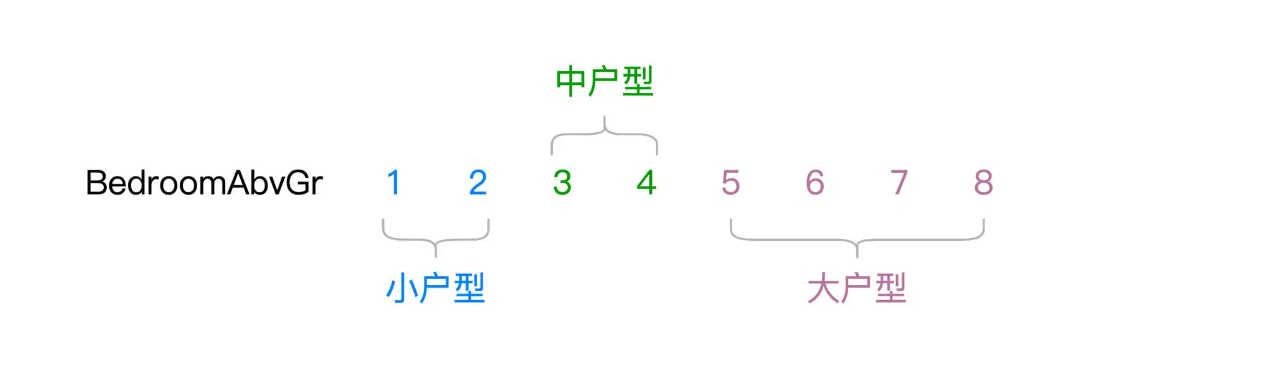
不难发现,“BedroomAbvGr”离散化之后,数据多样性由原来的 8 降低为现在的 3。那么问题来了,原始的连续数据好好的,为什么要对它做离散化呢?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/997224?site
推荐阅读
相关标签

