
- 1C++排序算法之基数排序_基数排序c++
- 2STM32—— AHB、APB详解_stm32的ahb
- 3【Android ContentProvider】ContentProvider_安卓contentprovider
- 4RabbitMQ 端口号解析
- 5Redis面试题超详细(2024最新)_题redis面试提
- 6HarmonyOS(鸿蒙)——全面入门,始于而不止于HelloWorld_鸿蒙应用 没有config.json
- 7Hdfs存储负载均衡_datanode卷选择策略平衡阀值
- 8Qt 将生成的exe文件自动复制到其它目录下
- 9vscode 配置git bash终端_vscode git-bash
- 10MySQL8.0 创建用户及授权 - 看这篇就足够了_mysql8.0 创建用户并授权
CentOS7安装Spark3.3.0 ON YARN集群并整合HIVE, Spark-On-HIVE_centos7安装sparkony集群详细
赞
踩
CentOS7安装Spark3.3.0 ON YARN集群并整合HIVE, Spark-On-HIVE
最近在学习Spark,在此记录一下Spark3.3.0集群在CentOS7的安装。
集群:
node1 192.168.88.100
node2 192.168.88.101
node3 192.168.88.102
1.下载bin压缩包
注意: Spark3.3.0的环境依赖Java 8/11/17, Scala 2.12/2.13, Python 3.7+、 R 3.5+等, 根据情况自行下载安装。
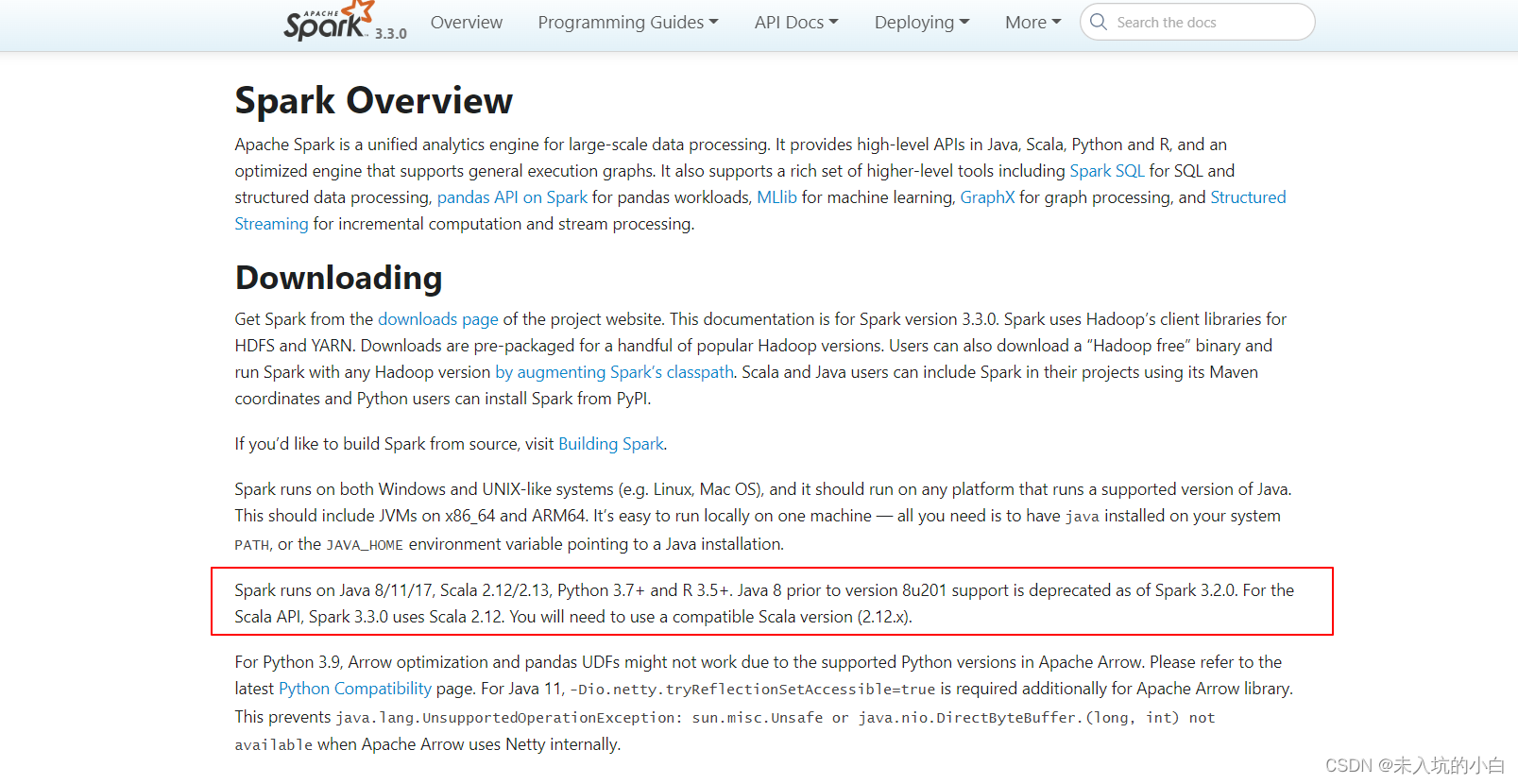
- 在spark的downloads页面下载spark-3.3.0-bin-hadoop3.tgz压缩包.
- 将下载好的压缩包上传到服务器node1的 /export/software/ 目录下。(可根据情况自行调整,也可以通过wget直接在服务器下载)
- 解压并设置软连接
tar -zxvf spark-3.3.0-bin-hadoop3.tgz -C /export/server/
cd /export/server/
ln -s spark-3.3.0-bin-hadoop3 spark
- 1
- 2
- 3
进入Spark目录可看到有以下文件
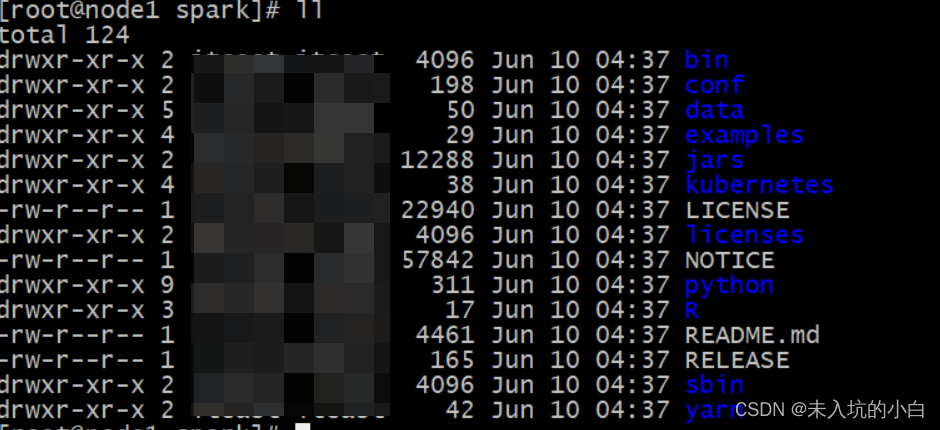
bin: 可执行脚本.
conf: 配置文件.
data: 示例程序使用数据.
examples: 示例程序
jars: 依赖的jar包
python: python API包
sbin: 集群管理命令
yarn: 整合yarn相关内容
2. 测试local模式
Spark的local模式, 开箱即用, 直接启动bin目录下的spark-shell脚本
cd /export/server/spark/bin
./spark-shell.sh
- 1
- 2
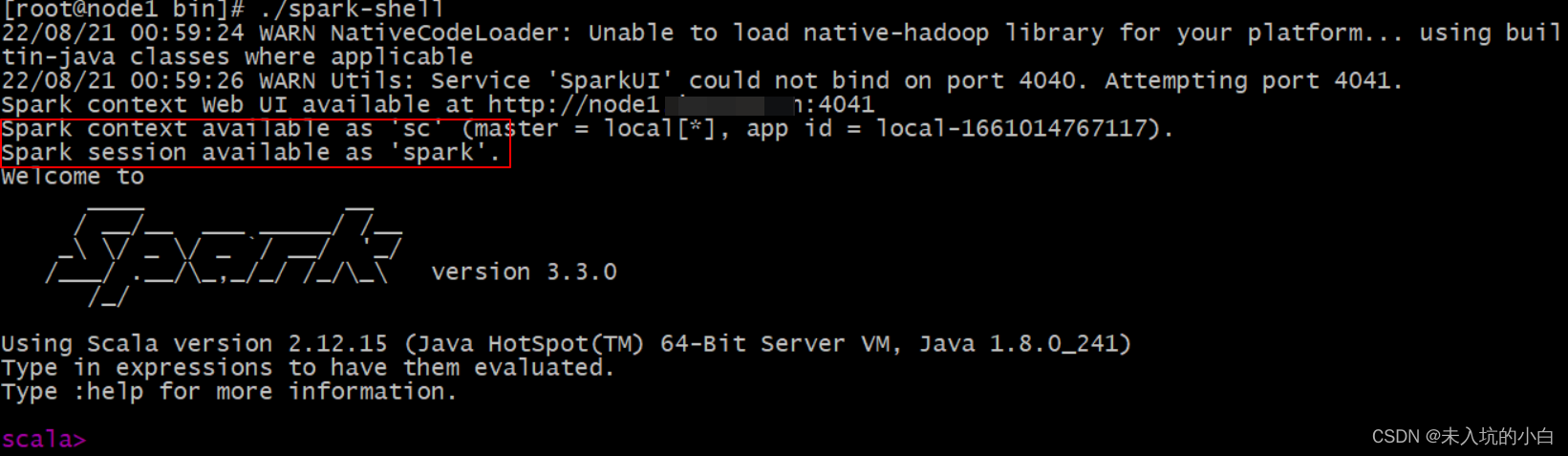
说明: 在spark-shell命令行中
sc:SparkContext实例对象:
spark:SparkSession实例对象
●Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell --master local[] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell --master local[]
4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://node01:7077,node02:7077
5.退出spark-shell
使用 :quit (快捷键 ctrl + D)
2 安装python3
由于CenOS7自带的python版本是2.X版本的,3台服务器都需要安装python3,安装python3是为了后面的pyspark,具体安装python3参考此博客。
我安装目前最新版python3.10.6
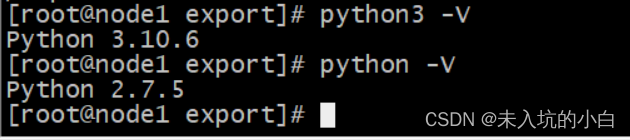
安装完毕后输入 python3 -V
python3 -V
- 1
会有以下界面(注意: 别覆盖CenOS7自带的python2.7.5版本, 因为yum命令需要python2的!)
安装python3完毕后,回到/spark/bin目录,输入
cd /export/server/spark/bin
./pyspark
- 1
- 2
会出现类似spark-shell的界面,只不过spark-shell的界面是scala语言的,pyspark是python的shell界面.
3. Spark On Yarn 模式 的环境搭建
经过以上测试,spark-shell与pyspark都没问题,下面开始搭建Spark On Yarn:
3.1 修改 spark-env.sh 文件
注意: 每台服务器的spark-env.sh 都要修改,为方便,最好在node1修改后分发到node2和node3,我这里是spark先在node1上安装spark,配置完成后统一将spark分发到node2和node3。
cd /export/server/spark/conf
cp spark-env.sh.template spark-env.sh
vim /export/server/spark/conf/spark-env.sh
- 1
- 2
- 3
往文件中添加Hadoop的配置文件路径以及Yarn的配置文件路径:
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
- 1
- 2
3.2 修改hadoop的yarn-site.xml
注意: 与以上3.1一样,每台服务器的yarn-site.xml 都要修改,为方便,最好在node1修改后分发到node2和node3。
cd /export/server/hadoop-3.3.0/etc/hadoop/
vim /export/server/hadoop-3.3.0/etc/hadoop/yarn-site.xml
- 1
- 2
添加以下配置:
<configuration> <!-- 配置yarn主节点的位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置yarn集群的内存分配方案 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <!-- 开启日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置聚合日志在hdfs上的保存时间 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 关闭yarn内存检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

