
热门标签
热门文章
- 1离线linux服务器安装mysql8_linux 离线安装mysql8
- 246、PHP实现矩阵中的路径
- 3cpu版本安装pytorch_清华源安装pytorch cpu版本
- 4linux命令行下使用的浏览器
- 5Go语言常见序列化协议全面对比
- 6Linux系统命令大全(超级详细版)_linux常用命令
- 7fastjson&Feature_com.alibaba.fastjson.parser.feature
- 8spark-submit 命令使用详解_spark-submit --master
- 9《Android Studio开发实战 从零基础到App上线(第3版)》资源下载和内容勘误_android studio开发实战 从零基础到app上线(第3版)(1)_android studio从零基础到app上线第三版pdf
- 102024年工信部AI人工智能证书“计算机视觉工程师”证书报考中!_ai人工智能训练技术证书报考条件
当前位置: article > 正文
测试在 4090 上运行 vicuna-33b 进行推理
作者:小惠珠哦 | 2024-08-03 07:54:25
赞
踩
vicuna-33b
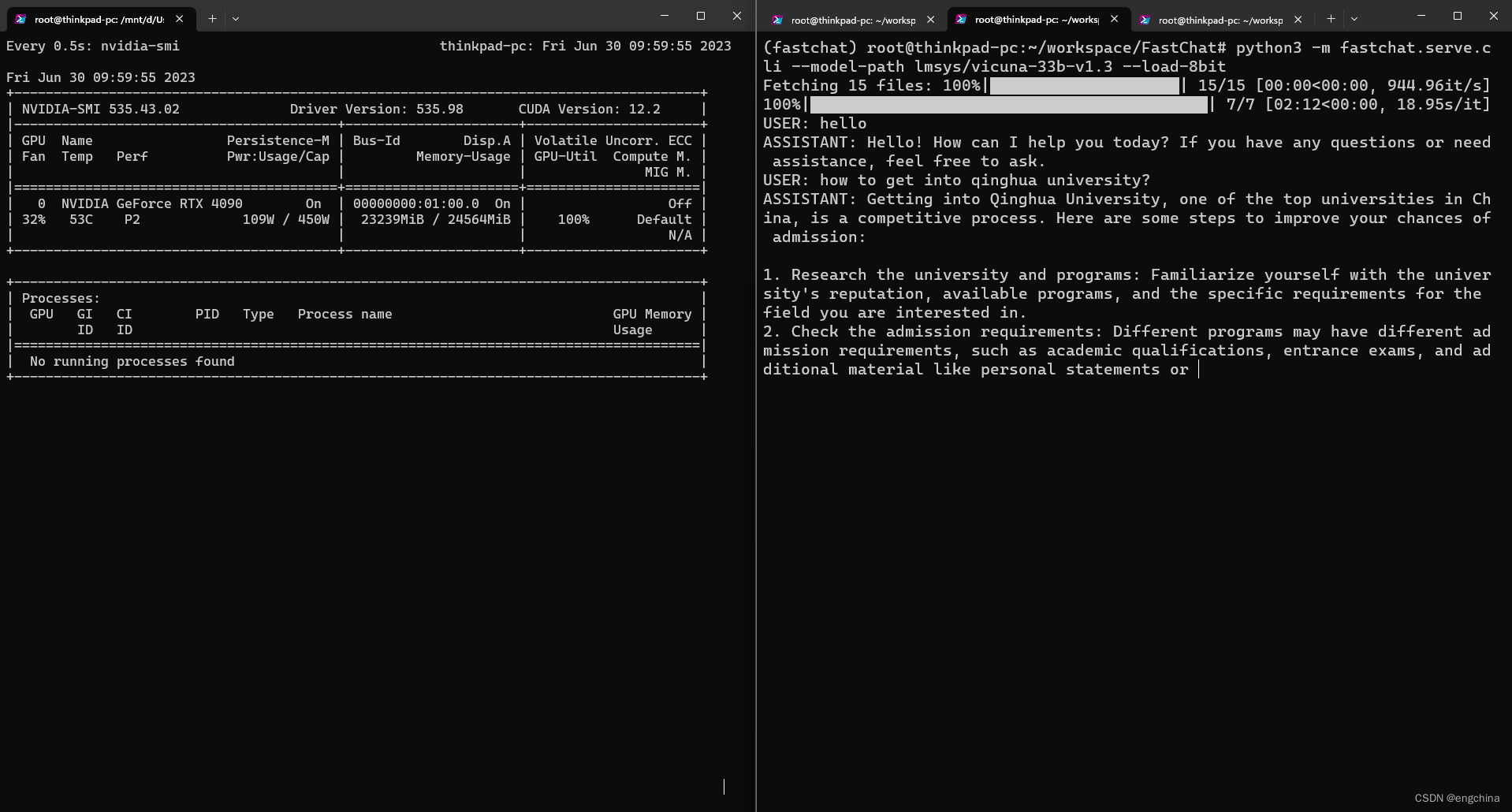
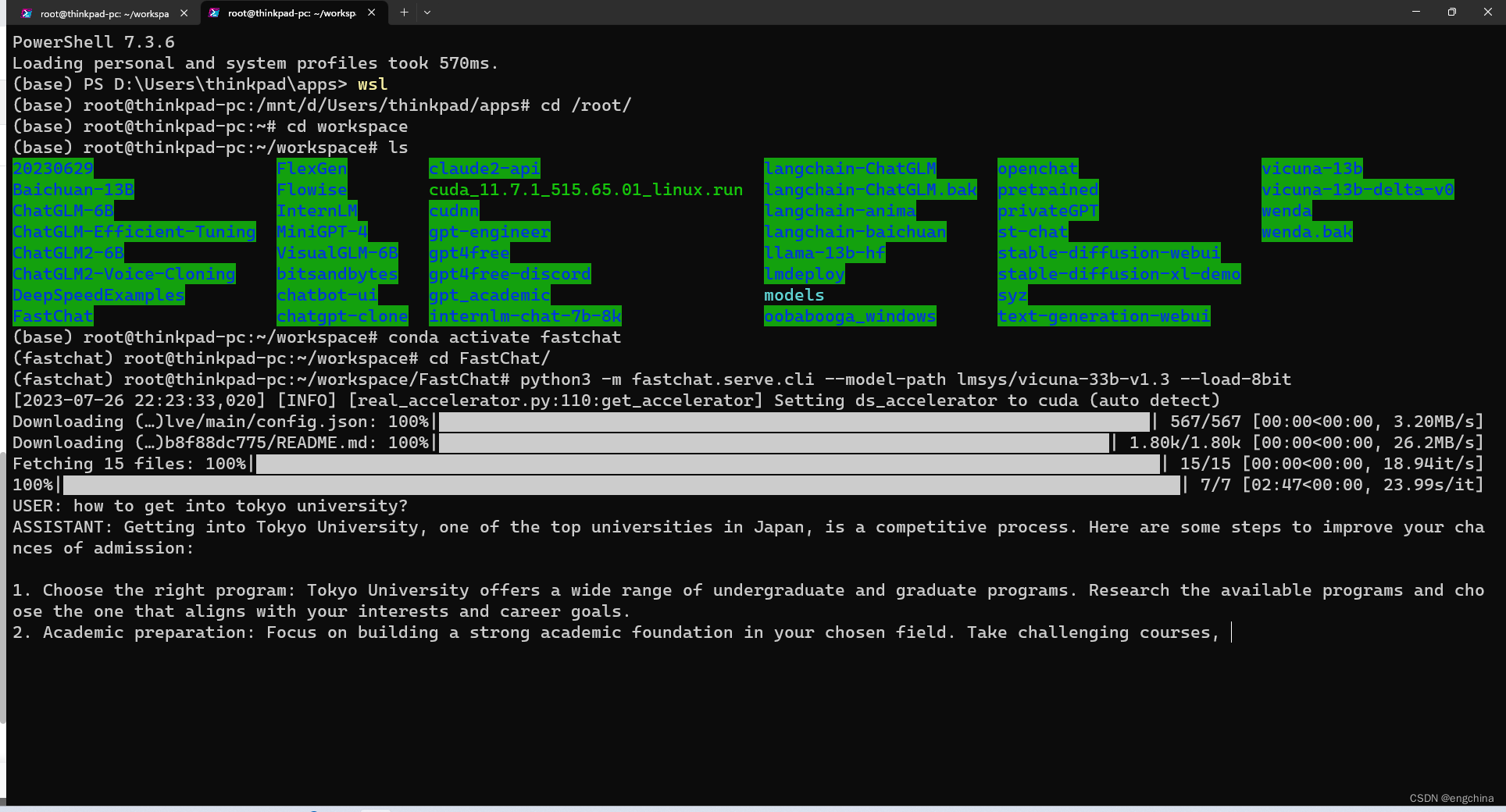
今天尝试在 4090 上运行 vicuna-33b 进行推理,使用的是 8bit 量化。
运行命令如下,
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-33b-v1.3 --load-8bit
- 1
结论,使用 8bit 量化在 4090 上可以运行 vicuna-33b 进行推理,显存用到大概 23239MiB,GPU 使用率基本全程 100%,推理过程非常非常慢。
20230726追加:
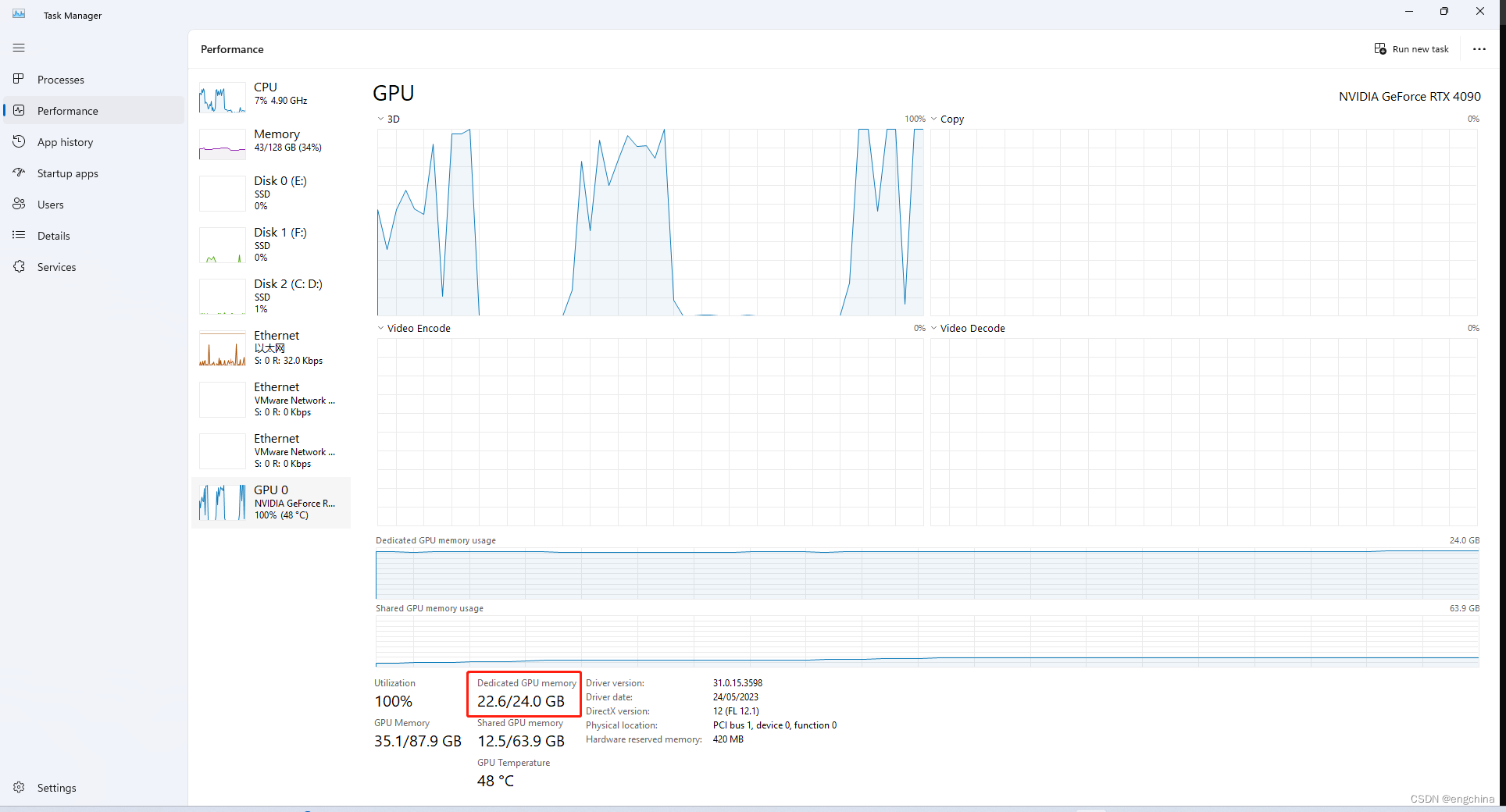
有读者反馈 32G的V100 跑不起来,所以再次测试一边,以及上传测试截图。
完结!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/922115
推荐阅读
相关标签

