
热门标签
热门文章
- 1【图像拼接(Image Stitching)】关于【图像拼接论文精读】专栏的相关说明,包含专栏使用方法、阅读顺序、创新思路、文章汇总、源码汇总、数据集汇总等。总之,【图像拼接论文相关】看这一篇就够了_图像拼接数据集
- 2git配置本地用户名和邮箱_git配置用户名和邮箱
- 302 VMware下载&安装银河麒麟(Kylin)系统_银河麒麟下载
- 4【初阶数据结构与算法 2】时间/空间复杂度练习——转轮数组_数组转置时间复杂度
- 5成为数据分析师要具备什么能力——招式篇_数据分析师技能要求
- 6XenApp_XenDesktop_7.6实战篇之十四:XenDesktop虚拟桌面的交付_desktop xenapp desktop
- 7Centos 7搭建netdata服务监控可视化平台_centos7安装多节点安装netdata
- 8Solidwork转urdf模型_solidworks转urdf
- 9探索LLaMA模型:架构创新与Transformer模型的进化之路_llama架构
- 10企业定制开发AI智能名片S2B2C商城系统小程序:以用户为核心的七个关键词策略
当前位置: article > 正文
HuggingFace 自然语言处理
作者:小惠珠哦 | 2024-08-01 05:49:36
赞
踩
huggingface
文章目录
一、HuggingFace 简介
HuggingFace是一个开源社区,提供了统一的AI 研发框架、工具集、可在线加载的数据集仓库和预训练模型仓库。HuggingFace把研发大致分为以下几个部分:准备数据集,定义模型,训练,测试;每个部分都提供了相应的工具集
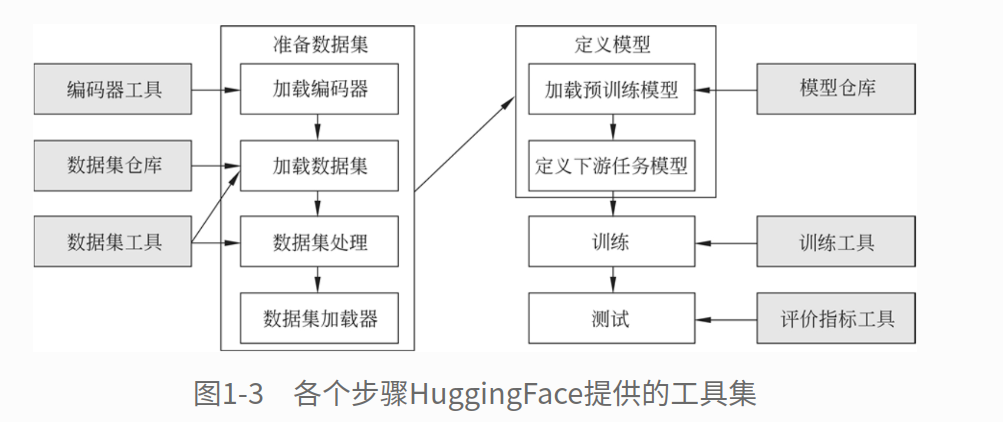
二、使用编码工具
HuggingFace提供了⼀套统⼀的编码 API,由每个模型各⾃提交实现;由于统⼀了API,所以调⽤者能快速地使⽤不同模型的编码⼯具
2.1、编码⼯具⼯作流
编码通常包含:定义字典、句⼦预处理、分词、编码 4 个步骤;编码工作流程示意图如下:
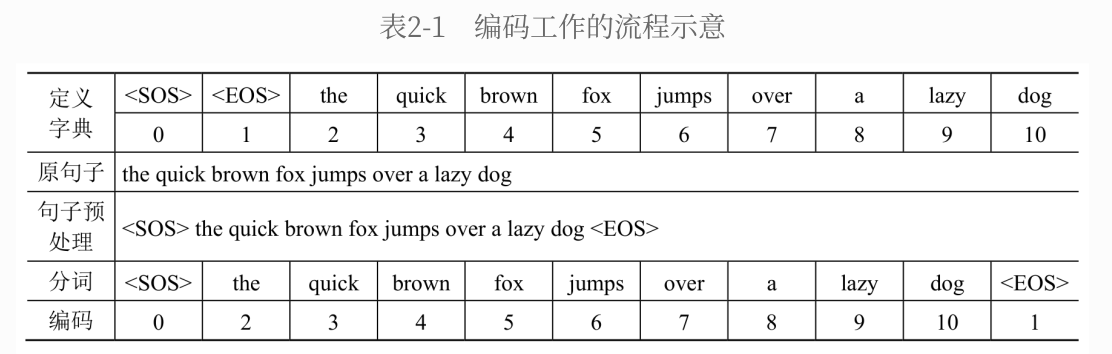
2.1.1、定义字典
- ⽂字是⼀个抽象的概念,不是计算机擅长处理的数据单元,计算机擅长处理的是数字运算,所以需要把抽象的⽂字转换为数字,让计算机能够做数学运算。
- 为了把抽象的⽂字数字化,需要⼀个字典把⽂字或者词对应到某个数字。⼀个⽰意的字典如下:
# 字典:这只是⼀个⽰意的字典,所以只有 11 个词,在实际项⽬中的字典可能会有成千上万个词
vocab = {
'<SOS>': 0, # Start Of Seq
'<EOS>': 1, # End Of Seq
'the': 2,
'quick': 3,
'brown': 4,
'fox': 5,
'jumps': 6,
'over': 7,
'a': 8,
'lazy': 9,
'dog': 10,
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.1.2、句子预处理
- 在句⼦被
分词之前,⼀般会对句⼦进⾏⼀些特殊的操作,例如把太长的句⼦截短,或在句⼦中添加⾸尾标识符等。
# 简单编码
sent = 'the quick brown fox jumps over a lazy dog'
sent = '<SOS> ' + sent + ' <EOS>'
print(sent) # <SOS> the quick brown fox jumps over a lazy dog <EOS>
- 1
- 2
- 3
- 4
2.1.3、分词
- 句⼦准备好了,接下来需要
把句⼦分成⼀个⼀个的词。对于中⽂来讲,这是个复杂的问题,但是对于英⽂来讲这个问题⽐较容易解决,因为英⽂有⾃然的分词⽅式,即以空格来分词,代码如下:
# 英⽂分词
words = sent.split()
print(words) # ['<SOS>', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'a', 'lazy', 'dog', '<EOS>']
- 1
- 2
- 3
- 对于中⽂来讲,分词的问题⽐较复杂,因为中⽂所有的字是连在⼀起写的,不存在⼀个⾃然的分隔符号。有很多成熟的⼯具能够做中⽂分词,例如
jieba 分词、 LTP 分词等,但是在这里我们不会使⽤这些⼯具,因为HuggingFace的编码⼯具已经包括了分词这⼀步⼯作,由各个模型⾃⾏实现,对于调⽤者来讲这些⼯作是透明的,不需要关⼼具体的实现细节
2.1.4、编码
- 句⼦已按要求添加了⾸尾标识符,并且分割成了⼀个⼀个的单词,现在需要把这些抽象的单词映射为数字。因为已经定义好了字典,所以使⽤字典就可以把每个单词分别地映射为数字,代码如下:
# 编码为数字
encode = [vocab[i] for i in words]
print(encode) # [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1]
- 1
- 2
- 3
2.2、编码工具的使用
2.2.1、基本编码函数
# 1、加载⼀个编码⼯具,这里使⽤ bert-base-chinese 的实现:在BERT的实现中,中⽂分词处理⽐较简单,就是把每个字都作为⼀个词来处理 from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path='bert-base-chinese', cache_dir=None, force_download=False,) # pretrained_model_name_or_path: 指定要加载的编码⼯具,⼤多数模型会把⾃己提交的编码⼯具命名为和模型⼀样的名字 # cache_dir: ⽤于指定编码⼯具的缓存路径,这里指定为None(默认值),也可以指定想要的缓存路径 # force_download: 为 True 时表明⽆论是否已经有本地缓存,都强制执⾏下载⼯作,建议设置为 False # 2、准备实验数据 sents = [ '你站在桥上看⻛景', '看⻛景的⼈在楼上看你', '明⽉装饰了你的窗⼦', '你装饰了别⼈的梦', ] # 3、基本的编码函数 out = tokenizer.encode( text=sents[0], # ⼀次编码⼀个或者⼀对句⼦,在这个例⼦中,编码了⼀对句⼦ text_pair=sents[1], # 如果只想编码⼀个句⼦,则可让 text_pair 传 None truncation=True, # 当句⼦长度⼤于 max_length 时截断 padding='max_length', # 当句⼦长度不⾜ max_length 时,在句⼦的后⾯补充 PAD(0),直到 max_length 长度 add_special_tokens=True, # 需要在句⼦中添加特殊符号,如逗号分隔符 SEP max_length=25, # 定义了 max_length 的长度 return_tensors=None, # 表明返回的数据类型为list格式,也可以赋值为 tf、pt、np,分别表⽰ TF、PyTorch、NumPy 数据格式 ) # 编码的输出为⼀个数字的list print(out) # 使⽤编码⼯具的decode()函数把这个list还原为分词前的句⼦,可看出编码工具对句⼦做了哪些预处理⼯作 print(tokenizer.decode(out)) # 运行结果如下: [101, 872, 4991, 1762, 3441, 677, 4692, 7599, 3250, 102, 4692, 7599, 3250, 4368, 782, 1762, 3517, 677, 4692, 872, 102, 0, 0, 0, 0] [CLS] 你 站 在 桥 上 看 ⻛ 景 [SEP] 看 ⻛ 景 的 ⼈ 在 楼 上 看 你 [SEP] [PAD] [PAD] [PAD] [PAD] [CLS]=101 [SEP]=102 [PAD]=0 # 4、进阶的编码函数 out = tokenizer.encode_plus( text=sents[0], # ⼀次编码⼀个或者⼀对句⼦,在这个例⼦中,编码了⼀对句⼦ text_pair=sents[1], # 如果只想编码⼀个句⼦,则可让 text_pair 传 None truncation=True, # 当句⼦长度⼤于 max_length 时截断 padding='max_length', # 当句⼦长度不⾜ max_length 时,在句⼦的后⾯补充 PAD(0),直到 max_length 长度 add_special_tokens=True, # 需要在句⼦中添加特殊符号,如逗号分隔符 SEP max_length=25, # 定义了 max_length 的长度 return_tensors=None, # 表明返回的数据类型为list格式,也可以赋值为 tf、pt、np,分别表⽰ TF、PyTorch、NumPy 数据格式 # 进阶参数 return_token_type_ids=True, # 因为编码的是两个句⼦,这个list⽤于表明编码结果中哪些位置是第1个句⼦,哪些位置是第2个句⼦。具体表现为,第2个句⼦的位置是1,其他位置是0 return_attention_mask=True, # ⽤于表明编码结果中哪些位置是 PAD;PAD 的位置是 0,其他位置是 1 return_special_tokens_mask=True, # ⽤于表明编码结果中哪些位置是特殊符号,具体表现为,特殊符号的位置是 1,其他位置是0 return_length=True, # 返回句子长度 ) # 返回一个字典 for k, v in out.items(): print(k, ':', v) tokenizer.decode(out['input_ids'])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62


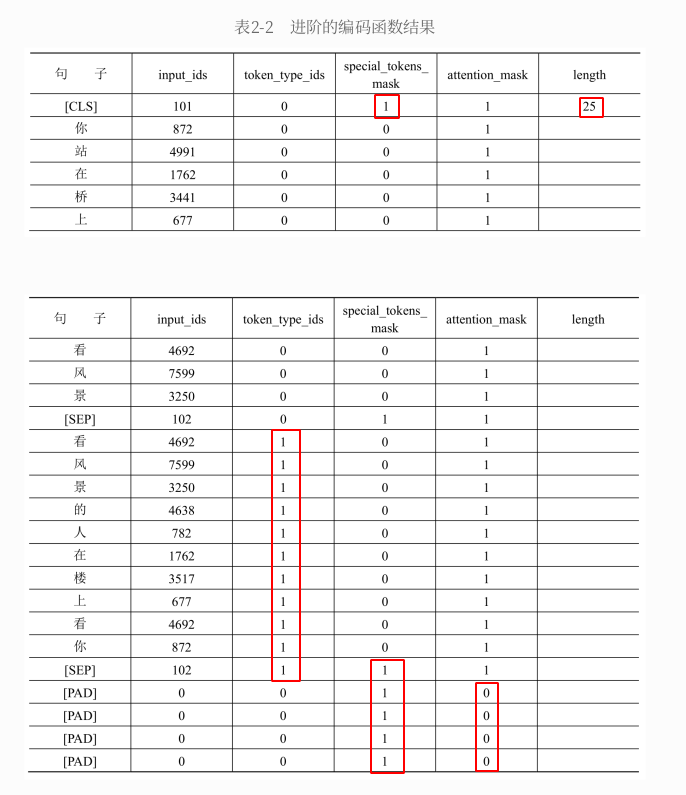
2.2.2、批量编码函数
#第2章/批量编码成对的句⼦ out = tokenizer.batch_encode_plus( # 编码成对的句⼦,若需要编码的是⼀个⼀个的句⼦,则修改为 batch_text_or_text_pairs=[sents[0], sents[1]] 即可 batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])], truncation=True, # 当句⼦长度⼤于 max_length 时截断 padding='max_length', # 当句⼦长度不⾜ max_length 时,在句⼦的后⾯补充 PAD(0),直到 max_length 长度 add_special_tokens=True, # 需要在句⼦中添加特殊符号,如逗号分隔符 SEP max_length=25, # 定义了 max_length 的长度 return_tensors=None, # 表明返回的数据类型为list格式,也可以赋值为 tf、pt、np,分别表⽰ TF、PyTorch、NumPy 数据格式 # 进阶参数 return_token_type_ids=True, # 因为编码的是两个句⼦,这个list⽤于表明编码结果中哪些位置是第1个句⼦,哪些位置是第2个句⼦。具体表现为,第2个句⼦的位置是1,其他位置是0 return_attention_mask=True, # ⽤于表明编码结果中哪些位置是 PAD;PAD 的位置是 0,其他位置是 1 return_special_tokens_mask=True, # ⽤于表明编码结果中哪些位置是特殊符号,具体表现为,特殊符号的位置是 1,其他位置是0 return_length=True, # 返回句子长度 ) # input_ids 编码后的词 # token_type_ids 第1个句⼦和特殊符号的位置是0,第2个句⼦的位置是1 # special_tokens_mask 特殊符号的位置是1,其他位置是0 # attention_mask PAD的位置是0,其他位置是1 # length 返回句⼦长度 for k, v in out.items(): print(k, ':', v) tokenizer.decode(out['input_ids'][0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

2.2.3、向字典添加新词
# 获取字典 vocab = tokenizer.get_vocab() print(type(vocab), len(vocab), '明⽉' in vocab) # (dict, 21128, False) # 添加新词 tokenizer.add_tokens(new_tokens=['明⽉', '装饰', '窗⼦']) # 添加新符号 tokenizer.add_special_tokens({'eos_token': '[EOS]'}) # 编码新添加的词 out=tokenizer.encode( text='明⽉装饰了你的窗⼦[EOS]', text_pair=None, truncation=True, padding='max_length', add_special_tokens=True, max_length=10, return_tensors=None, ) print(out) tokenizer.decode(out) # 输出如下:可以看到,“明⽉” 已经被识别为⼀个词,而不是两个词,新的特殊符号 [EOS] 也被正确识别 [101, 21128, 21129, 749, 872, 4638, 21130, 21131, 102, 0] '[CLS] 明⽉ 装饰 了 你 的 窗⼦ [EOS] [SEP] [PAD]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
三、使用数据集工具
3.1、数据集的加载和保存
# 1、在线加载数据集:由于 HuggingFace 把数据集存储在⾕歌云盘上,在国内加载时可能会遇到⽹络问题,可离线加载使用 from datasets import load_dataset from datasets import load_from_disk dataset = load_dataset(path='seamew/ChnSentiCorp') print(dataset) # 输出如下所示: DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 9600 }) validation: Dataset({ features: ['text', 'label'], num_rows: 0 }) test: Dataset({ features: ['text', 'label'],}) num_rows: 1200 }) }) # 2、将数据集保存到本地磁盘 dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp') # 3、从磁盘加载数据集 dataset = load_from_disk('./data/ChnSentiCorp')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3.2、数据集基本操作
# 1、取出数据部分 dataset = dataset['train'] # 使⽤train数据⼦集做后续的实验 # 2、查看数据样例 for i in [12, 17, 20, 26, 56]: print(dataset[i]) # 输出结果如下:字段 text 表⽰消费者的评论,字段 label 表明这是⼀段好评还是差评 {'text': '轻便,⽅便携带,性能也不错,能满⾜平时的⼯作需要,对出差⼈员来讲⾮常不错','label': 1} {'text': '很好的地理位置,⼀塌糊涂的服务,萧条的酒店。', 'label': 0} {'text': '⾮常不错,服务很好,位于市中⼼区,交通⽅便,不过价格也⾼!', 'label': 1} {'text': '跟住招待所没什么太⼤区别。绝对不会再住第2次的酒店!', 'label': 0} {'text': '价格太⾼,性价⽐不够好。我觉得今后还是去其他酒店⽐较好。', 'label': 0} # 3、打乱数据顺序 shuffled_dataset=dataset.shuffle(seed=42) # 4、将训练集切分训练集和测试集 dataset.train_test_split(test_size=0.1) DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 8640 }) test: Dataset({ features: ['text', 'label'], num_rows: 960 }) }) # 5、使⽤批处理加速 def f(data): text=data['text'] text=['My sentence: ' + i for i in text] data['text']=text return data maped_datatset=dataset.map(function=f, batched=True, batch_size=1000, # 以 1000 条数据为⼀个批次进⾏⼀次处理;把函数执⾏的次数削减约 1000 倍,提⾼了运⾏效率 num_proc=4) # 在 4 条线程上执⾏该任务 print(dataset['text'][20]) print(maped_datatset['text'][20]) # 6、将数据保存为 CSV 或 JSON 格式 dataset.to_csv(path_or_buf='./data/ChnSentiCorp.csv') dataset.to_json(path_or_buf='./data/ChnSentiCorp.json')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
四、使用评价指标工具
# 1、列出可⽤的评价指标 from datasets import list_metrics metrics_list = list_metrics() print(len(metrics_list), metrics_list[:5]) # (51, ['accuracy', 'bertscore', 'bleu', 'bleurt', 'cer']) # 2、加载⼀个评价指标:加载⼀个评价指标和加载⼀个数据集⼀样简单 # 将对应数据集和⼦集的名字输⼊load_metric()函数即可得到对应的评价指标,但并不是每个数据集都有对应的 # 评价指标,在实际使⽤时以满⾜需要为准则选择合适的评价指标即可。 from datasets import load_metric metric = load_metric(path='glue', config_name='mrpc') # 3、获取评价指标的使⽤说明:评价指标的 inputs_description 属性为⼀段⽂本,描述了评价指标的使⽤⽅法 print(metric.inputs_description) # 4、计算⼀个评价指标 predictions=[0, 1, 0] references=[0, 1, 1] print(metric.compute(predictions=predictions, references=references)) # 输出:{'accuracy': 0.666666666666, 'f1': 0.666666666666}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
五、使用管道工具
使⽤管道⼯具时,调⽤者需要做的只是告诉管道⼯具要进⾏的
任务类型,管道⼯具会⾃动分配合适的模型(也可以指定模型),直接给出预测结果,如果这个预测结果对于调⽤者已经可以满⾜需求,则不再需要再训练。
# 1、⽂本分类 from transformers import pipeline classifier = pipeline("sentiment-analysis") result = classifier("I hate you")[0] print(result) # {'label': 'NEGATIVE', 'score': 0.9991} result = classifier("I love you")[0] print(result) # {'label': 'POSITIVE', 'score': 0.9998} # 2、阅读理解 from transformers import pipeline question_answerer=pipeline("question-answering") context=r""" Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune a model on a SQuAD task, you may leverage the examples/PyTorch/question- answering/run_squad.py script. """ result=question_answerer(question="What is extractive question answering?",context=context,) print(result) # 输出如下: {'score': 0.61 'start': 34, 'end': 95, 'answer': 'the task of extracting an answer from a text given a question'} # 3、完形填空: sentence是⼀个句⼦,其中某些词被<mask>符号替代了,表明这是需要让模型填空的空位 from transformers import pipeline unmasker=pipeline("fill-mask") from pprint import pprint sentence='HuggingFace is creating a <mask> that the community uses to solve NLP tasks.' print(unmasker(sentence)) # 4、⽂本续写:⼊参为⼀个句⼦的开头,让text_generator接着往下续写,参数max_length=��表明要续写的长度 from transformers import pipeline text_generator=pipeline("text-generation") text_generator("As far as I am concerned, I will", max_length=50, do_sample=False) # 输出如下: [{'generated_text': 'As far as I am concerned, I will be the first to admit that I am not a fan of the idea of a "free market." I think that the idea of a free market is a bit of a stretch. I think that the idea'}] # 5、命名实体识别(Named Entity Recognition):找出⼀段⽂本中的⼈名、地名、组织机构名等 from transformers import pipeline ner_pipe=pipeline("ner") sequence = """Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge which is visible from the window.""" for entity in ner_pipe(sequence): print(entity) # 6、文本摘要:使⽤⽂本总结⼯具对这段长⽂本进⾏摘要 from transformers import pipeline summerizer=pipeline("summerization") # 7、翻译 from transformers import pipeline translator=pipeline("translation_en_to_de") sentence="Hugging Face is a technology company based in New York and Paris" translator(sentence, max_length=40) # 8、QA:使用本地模型 from awq import AutoAWQForCausalLM from transformers import AutoTokenizer from transformers import pipeline model_name_or_path = "TheBloke/CodeLlama-7B-Instruct-AWQ" # Load model model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True, trust_remote_code=True, safetensors=True) tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True) prompt = "Tell me about AI" prompt_template=f'''[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```: {prompt} [/INST] ''' pipe = pipeline( "text-generation", # 指定任务类型 model=model, tokenizer=tokenizer, max_new_tokens=512, # 最大长度 do_sample=True, temperature=0.7, top_p=0.95, top_k=40, repetition_penalty=1.1 ) print(pipe(prompt_template)[0]['generated_text'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
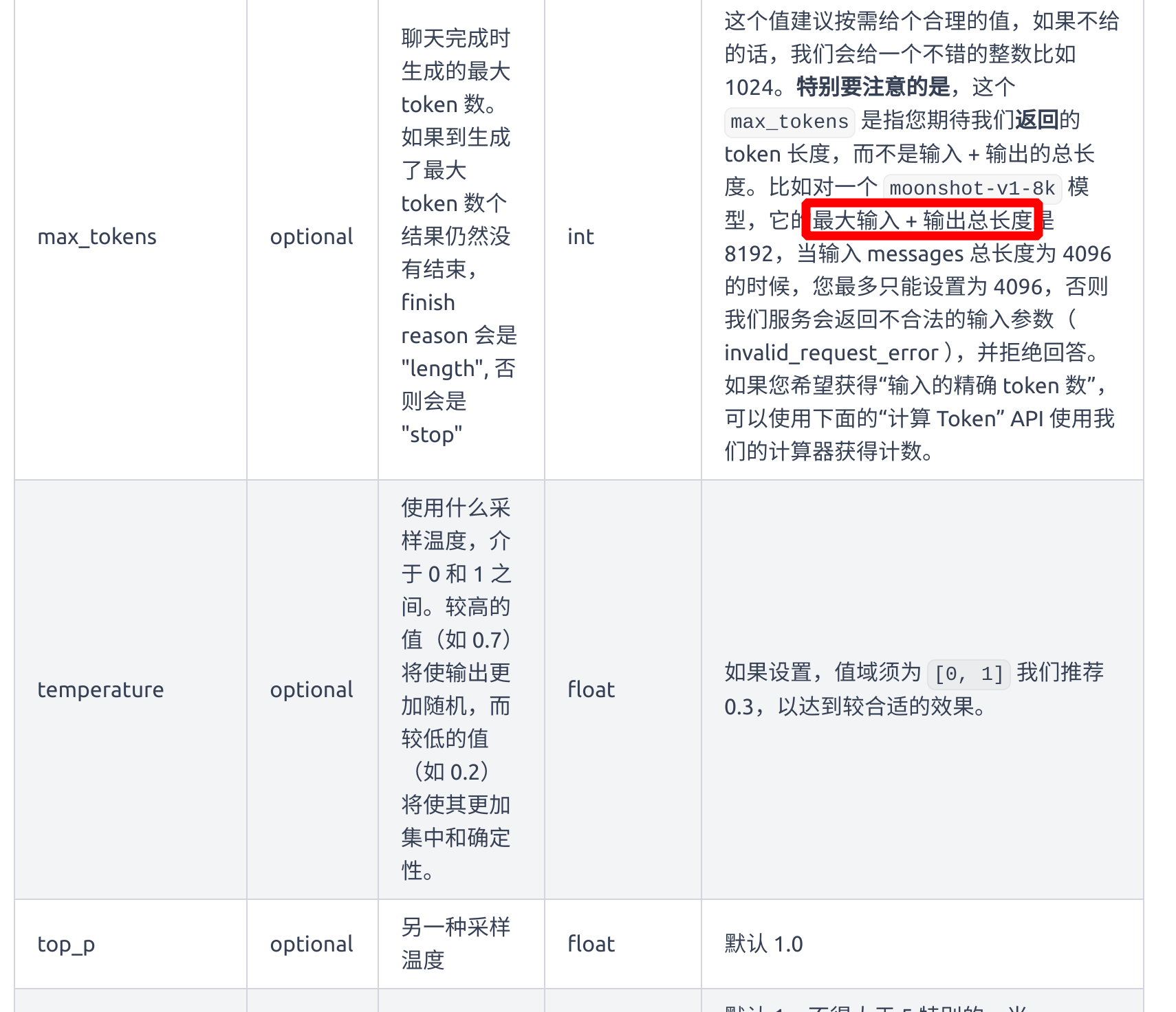
- config 文件参数解释

六、使用训练工具
6.1、准备数据
6.1.1、加载编码工具
# 加载 tokenizer:编码⼯具和模型往往是成对使⽤的
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('hfl/rbt3')
# 编码句⼦
print(tokenizer.batch_encode_plus(['明⽉装饰了你的窗⼦', '你装饰了别⼈的梦'],truncation=True,))
# 输出如下图所示:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

6.1.2、加载数据集
# 从磁盘加载数据集 from datasets import load_from_disk dataset = load_from_disk('./data/ChnSentiCorp') # 缩小数据规模,便于测试 dataset['train'] = dataset['train'].shuffle().select(range(2000)) dataset['test'] = dataset['test'].shuffle().select(range(100)) print(dataset) DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 2000 }) validation: Dataset({ features: ['text', 'label'], num_rows: 0 }) test: Dataset({ features: ['text', 'label'], num_rows: 100 }) }) # 批处理编码 def f(data): return tokenizer.batch_encode_plus(data['text'], truncation=True) dataset=dataset.map(f, batched=True, batch_size=1000, num_proc=0, remove_columns=['text']) print(dataset) # 运行结果如下 DatasetDict({ train: Dataset({ features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'], num_rows: 2000 }) validation: Dataset({ features: ['text', 'label'], num_rows: 0 }) test: Dataset({ features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'], num_rows: 100 }) }) # 移除太长的句⼦:把数据集中长度超过 512 个词的句⼦过滤掉 # 也可以把超出长度的部分截断,留下符合模型长度要求的数据 def f(data): return [len(i)<=512 for i in data['input_ids']] dataset=dataset.filter(f, batched=True, batch_size=1000, num_proc=4) # 自定义数据集 import torch from datasets import load_from_disk class Dataset(torch.utils.data.Dataset): def __init__(self, split): self.dataset = load_from_disk('./data/ChnSentiCorp')[split] def __len__(self): return len(self.dataset) def __getitem__(self, i): text = self.dataset[i]['text'] label = self.dataset[i]['label'] return text, label dataset = Dataset('train')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
6.2、定义模型和训练工具
6.2.1、加载预训练模型
# 加载模型:
from transformers import AutoModelForSequenceClassification
model=AutoModelForSequenceClassification.from_pretrained('hfl/rbt3', num_labels=2)
# 模型试算:模拟⼀批数据并进行试算
data = {
'input_ids': torch.ones(4, 10, dtype=torch.long),
'token_type_ids': torch.ones(4, 10, dtype=torch.long),
'attention_mask': torch.ones(4, 10, dtype=torch.long),
'labels': torch.ones(4, dtype=torch.long)}
out = model(**data)
print(out['loss'], out['logits'].shape) # (tensor(0.3597, grad_fn=<NllLossBackward0>), torch.Size([4, 2]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.2.2、定义评价函数
# 加载评价指标 from datasets import load_metric metric = load_metric('accuracy') # 定义评价函数 import numpy as np from transformers.trainer_utils import EvalPrediction def compute_metrics(eval_pred): logits, labels = eval_pred logits = logits.argmax(axis=�) return metric.compute(predictions=logits, references=labels) # 模拟输出 eval_pred = EvalPrediction( predictions=np.array([[0, 1], [2, 3], [4, 5], [6, 7]]), label_ids=np.array([1, 1, 0, 1]), ) print(compute_metrics(eval_pred)) # {'accuracy': 0.75}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6.2.3、定义训练超参数
# 定义训练参数:HuggingFace使⽤TrainingArguments对象来封装超参数 from transformers import TrainingArguments # 定义训练参数 args = TrainingArguments( output_dir='./output_dir', # 定义临时数据保存路径 evaluation_strategy='steps', # 定义测试执⾏的策略,可取值为no、epoch、steps eval_steps=30, # 定义每隔多少个step执⾏⼀次测试 save_strategy='steps', # 定义模型保存策略,可取值为no、epoch、steps save_steps=20, # 定义每隔多少个step保存⼀次 num_train_epochs=1, # 定义共训练几个轮次 learning_rate=1e-4, # 定义学习率 weight_decay=1e-2, # 加⼊参数权重衰减,防⽌过拟合 per_device_eval_batch_size=16, # 定义测试和训练时的批次⼤小 per_device_train_batch_size=16, no_CUDA=True, # 定义是否要使⽤GPU训练 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.2.4、定义训练器
from transformers import Trainer
from transformers.data.data_collator import DataCollatorWithPadding
# 定义训练器:需要传递要训练的模型、超参数对象、训练和验证数据集、评价函数,以及数据整理函数
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer),
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.2.5、数据整理函数介绍
- 数据整理函数使⽤了由
HuggingFace提供的DataCollatorWithPadding对象,它能把⼀个
批次中长短不⼀的句⼦补充成统⼀的长度,长度取决于这个批次中最长的句⼦有多长 - 所有数据的长度⼀致后即可转换成矩阵,模型期待的数据类型也是矩阵,所以经过数据整理函数的处理之后,数据即被整理成模型可以直接计算的矩阵格式
# 测试数据整理函数 data_collator = DataCollatorWithPadding(tokenizer) data = dataset['train'][:5] # 获取⼀批数据 # 输出这些句⼦的长度 for i in data['input_ids']: print(len(i)) data = data_collator(data) # 调⽤数据整理函数 # 查看整理后的数据 for k, v in data.items(): print(k, v.shape) 62 34 185 101 40 input_ids torch.Size([5, 185]) token_type_ids torch.Size([5, 185]) attention_mask torch.Size([5, 185]) labels torch.Size([5]) # 通过如下代码可以查看数据整理函数是如何对句⼦进⾏补长的 tokenizer.decode(data['input_ids'][0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

6.3、训练和测试
6.3.1、模型训练和测试
# 训练
trainer.train()
# 从某个存档⽂件继续训练
trainer.train(resume_from_checkpoint='./output_dir/checkpoint-90')
# 评价模型
trainer.evaluate()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.3.2、模型的保存和加载
# ⼿动保存模型参数
trainer.save_model(output_dir='./output_dir/save_model')
# ⼿动加载模型参数
import torch
model.load_state_dict(torch.load('./output_dir/save_model/PyTorch_model.bin'))
- 1
- 2
- 3
- 4
- 5
- 6
6.3.3、模型预测
model.eval()
# 从测试数据集中获取1个批次的数据⽤于预测
for i, data in enumerate(trainer.get_eval_dataloader()):
break
out = model(**data)
out = out['logits'].argmax(dim=1)
for i in range(8):
print(tokenizer.decode(data['input_ids'][i], skip_special_tokens =True))
print('label=', data['labels'][i].item())
print('predict=', out[i].item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
七、NLP 实战
7.1、中文情感分类
- 在自然语言处理中,
AdamW优化器比Adam效果要好 - 分类的类别太多(
上万)也容易出现梯度消失的问题,所以在下游任务的输出时不能使⽤Softmax
函数激活
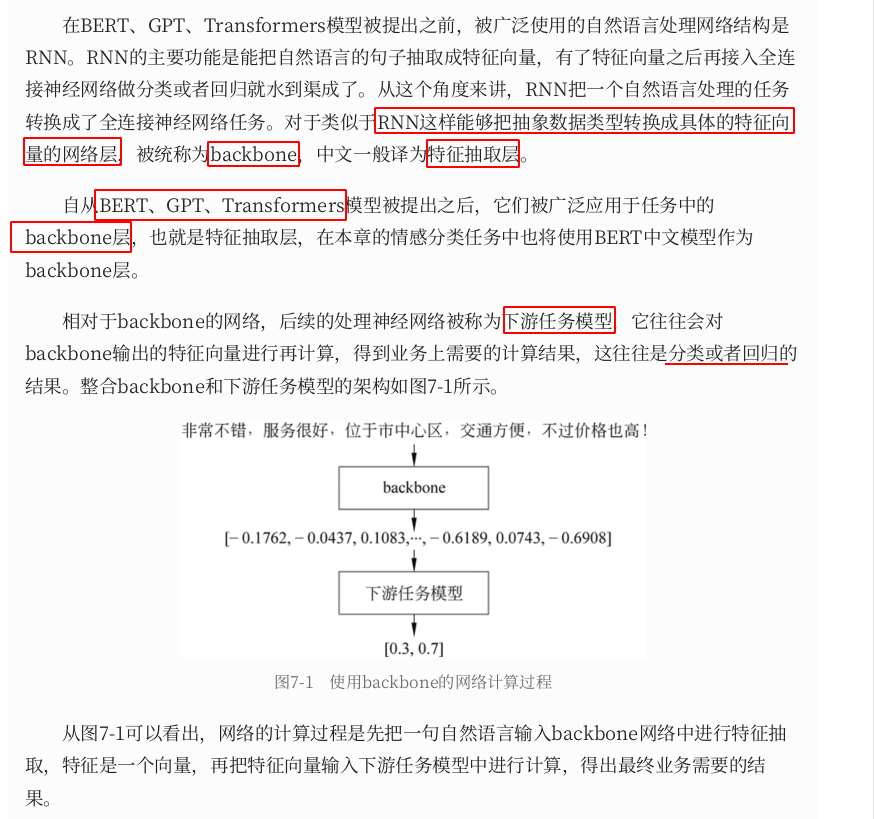
7.2、中⽂命名实体识别
7.2.1、数据标签定义
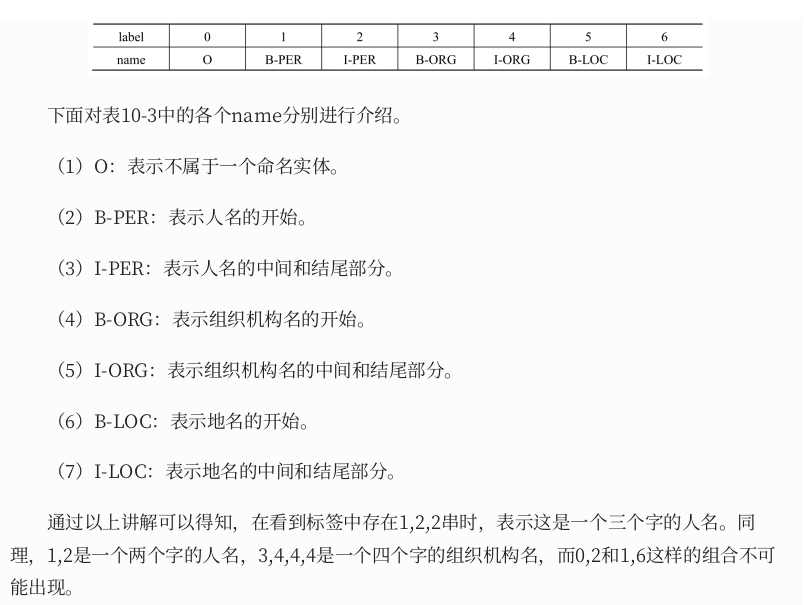
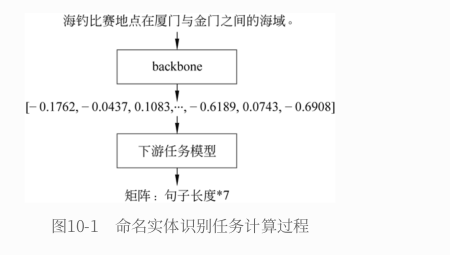
7.2.2、训练框架示例
7.2.3、两段式训练的思想
使用两段式训练;它是⼀种训练技巧,指先
单独对下游任务模型进⾏⼀定的训练,待下游任务模型掌握了⼀定的知识以后,再连同预训练模型和下游任务模型⼀起进⾏训练的模式。
- 可以把这个过程想象为⼀条流水线上的两个⼯作,上游的是熟练⼯,下游的是⽣疏⼯⼈。⼀开始生疏的⼯⼈没有任何知识,当⽣产出错时,我们就会要求⽣疏的⼯⼈改进⼯作⽅法,而不会怀疑熟练⼯的⼯作⽅法。
- 在这个阶段如果要求熟练⼯⼈改进,则反而会导致他怀疑以往积累的知识是否是正确的,他会为了配合糟糕的⽣疏⼯⼈而错误地修改⾃己的⽣产⽅法,这显然并不是我们想要的。
- 所以应该先训练⽣疏⼯⼈,把⽣疏⼯⼈训练成⼀个半熟练的⼯⼈,此时⽣产的正确率已经难以上升,再让两个⼯⼈共同训练,以优化⽣产的正确率,这就是
两段式训练的思想。

八、手动实现 Transformer
- Transformer 深度学习架构是通过继承许多⽅法而产⽣的,其中包括
上下⽂词嵌⼊、多头注意⼒机制、位置编码、并⾏体系结构、模型压缩、迁移学习、跨语⾔模型等。 - 在各种基于神经的⾃然语⾔处理⽅法中,Transformer 架构逐渐演变为基于注意⼒的 “
编码器-解码器”体系结构,并持续发展到今天。现在,我们在⽂献中看到了这种体系结构的新的成功变体。⽬前研究已经发现了 只使⽤ Transformer 架构中编码器部分(自编码 BERT-like) 的出⾊模型,如 BERT(BidirectionalEncoder Representations from Transformers,Transformers 双向编码表⽰);或者 只使⽤ Transformer 架构中解码器部分(自回归 GPT-like) 的出⾊模型,如 GPT(Generated Pre-trained Transformer,⽣成式的预训练 Transformer);以及BART/T5-like(也被称作序列到序列的 Transformer模型)


- 在Transformer被提出之前,普遍使⽤的⽂本特征抽取层是RNN,RNN的缺点是能表达的⽂本复杂度很有限,尤其
针对长⽂本的处理能⼒更差,虽然在 LSTM 和 GRU 模型被提出后 RNN 的这个缺点在很⼤程度上被弥补了,但依然没有得到彻底解决。- Transformer使⽤注意⼒模型抽取⽂本特征,很好地解决了RNN的两个缺点,Transformer的注意⼒模型就是要找
出词与词之间的相互对应关系,所以对长⽂本有较好的处理能⼒,Transformer的计算过程是可并⾏的,效率⽐RNN要⾼很多Transformer内部有⼀个编码器和⼀个解码器。编码器负责读取原⽂,从原⽂中抽取特征后交给解码器;解码器负责⽣成译⽂- 编码器和解码器的内部都是多层结构,图中画出的是3层,实际情况中可能多于这个数字。编码器在计算时,多层编码器是前后串⾏的结构,最后⼀层抽取的⽂本特征作为最终的⽂本特征;解码器同样是前后串⾏的结构,每次的计算输⼊除了
前⼀层的计算输出,还包括了编码器抽取的⽂本特征
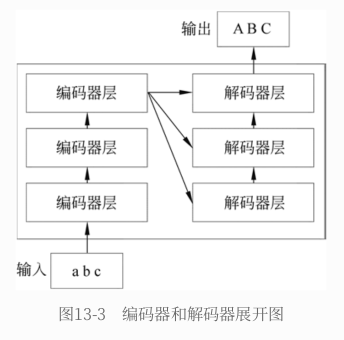
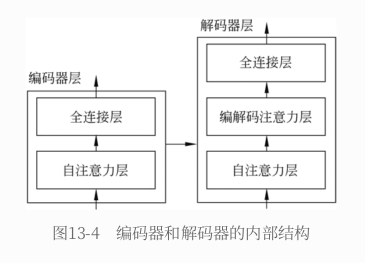
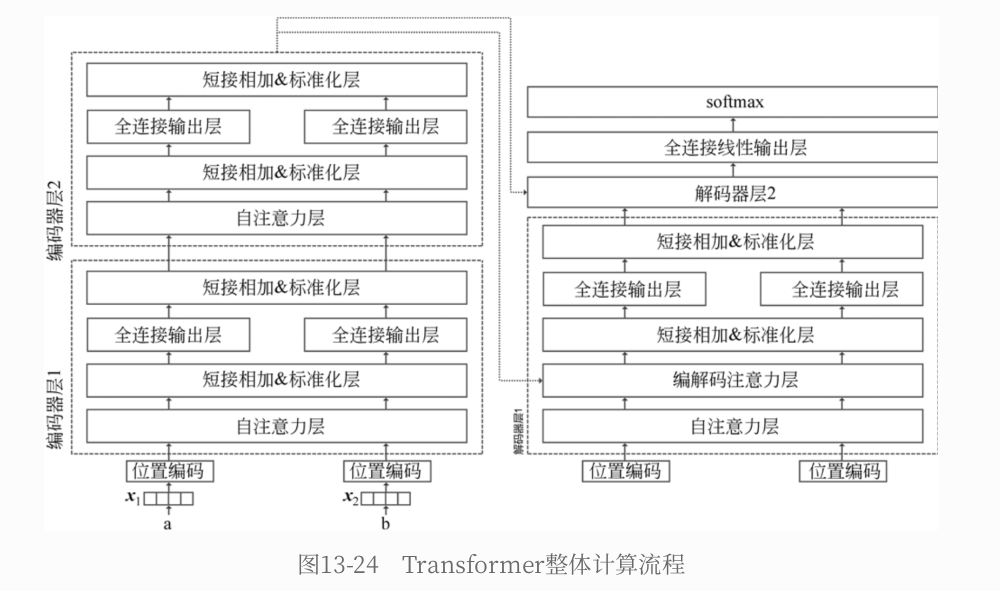
九、手动实现 BERT
- BERT 是基于 Transformer 模型的改进模型,与 Transformer 不同,BERT 的设计并不是为了完成特定的具体任务,BERT 的设计初衷就是要作为⼀个
通⽤的 backbone使⽤,即提取⽂本的特征向量,有了特征向量后就可以接⼊各种各样的下游任务,包括翻译任务、分类任务、回归任务等 - BERT 模型的架构如下图所示:


十、文本生成任务解码策略

- 传统的
Greedy Search具有很大的限制(会出现大量的重复),表现并不好,通常不会在实际场景中使用。Beam Search的生成结果更加确定,并且更接近整体概率最高的序列。但是有可能生成循环的文本。当然也有研究指出这一问题与模型的训练方式关系更大。它主要应用于 机器翻译和文本摘要 等需要确定性结果的任务中。Top-K Sampling和Top-P Sampling可以生成更具随机性和更具创意的结果,并且可调节的范围很大。Top-P Sampling的适应性更强,但是也意味这它的性能会弱于使用固定k进行筛选的Top-K Sampling。他们通常应用在 对话系统或者故事生成 等更需要创意的任务中。

- 公开论文中梳理出的解码方案
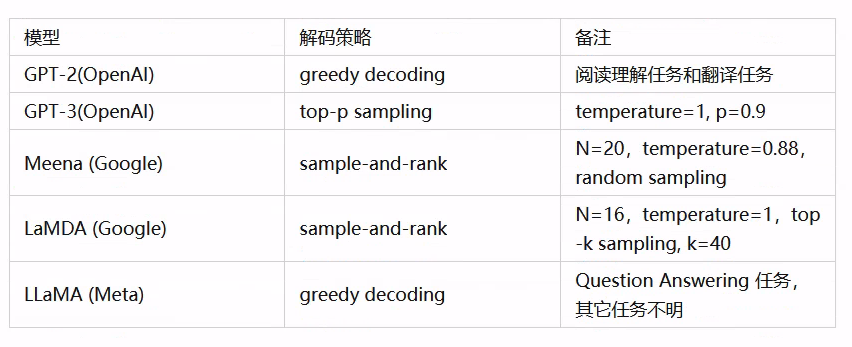
10.1、Greedy Search(贪心搜索)
Greedy Search是指每一步解码都选取可能性最高的单词(i.e.argmax),把选取的单词补充到input中再继续下一步解码直到产生[EOS]或者达到了事先定义的最大生成长度后停止解码。它的缺点也很明显:- 续写的内容还算通顺,但逻辑有些问题,并且很快就开始有了大量的重复
- 会遗漏隐藏在低概率单词后面的高概率单词
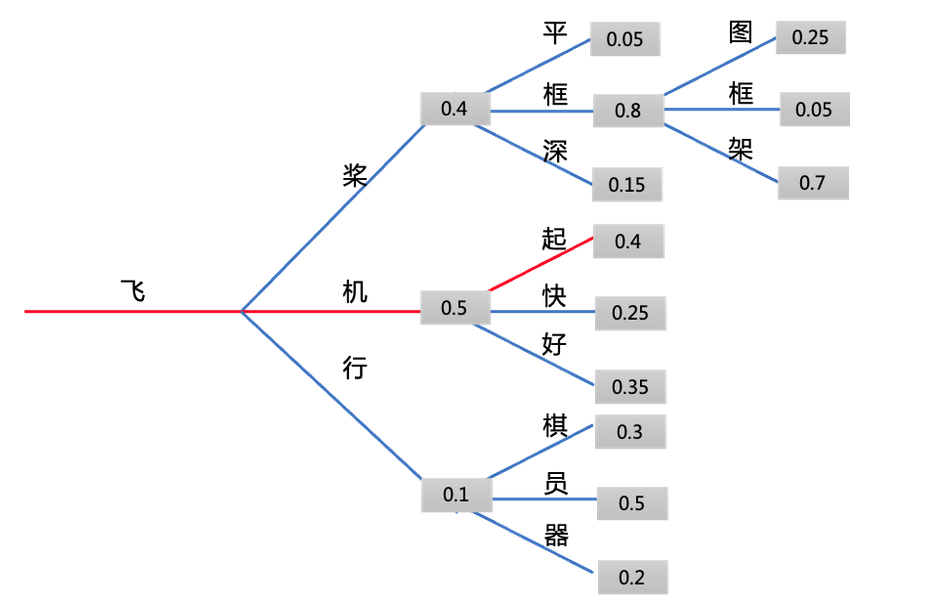
10.2、Beam Search(束搜索)
Beam Search是一种启发式图搜索算法,具有更大的搜索空间,可以减少遗漏隐藏在低概率单词后面的高概率单词的可能性,他会在每步保持最可能的num_beams个hypotheses,最后选出整体概率最高或者平均得分最大(除以各自的 token 数)的hypotheses。下面以num_beams=2为例:- 从下图中可以看到,在第一步的时候,我们除了选择概率最高的『机』字以外,还保留了概率第二高的『桨』字。在第二步的时候
两个 beam分别选择了『起』和『框』。这时我们发现『飞机起』这一序列的概率为0.2,而『飞桨框』序列的概率为0.32。我们找到了整体概率更高的序列。在我们这个示例中继续解下去,得到的最终结果为『飞桨框架』 - 相比
Greedy Search,Beam Search几乎总能找到整体概率更高的结果。当然由于它的搜索空间也不是无限的,它难以找到所谓的最优解
- 从下图中可以看到,在第一步的时候,我们除了选择概率最高的『机』字以外,还保留了概率第二高的『桨』字。在第二步的时候
Beam Search缺点:- 结果里还是会出现一些重复内容,一个简单的补救措施是引入
n-grams(即连续 n 个词的词序列) 惩罚。最常见的n-grams惩罚是确保每个n-gram都只出现一次,方法是如果看到当前候选词与其上文所组成的n-gram已经出现过了,就将该候选词的概率设置为0。我们可以通过设置no_repeat_ngram_size=2来试试,这样任意2-gram不会出现两次。但是惩罚太高,生成的文章会不达意,惩罚太少,容易出现大量循环的句子 - 缺乏随机性,对于相似的输入,可能生成相同的结果
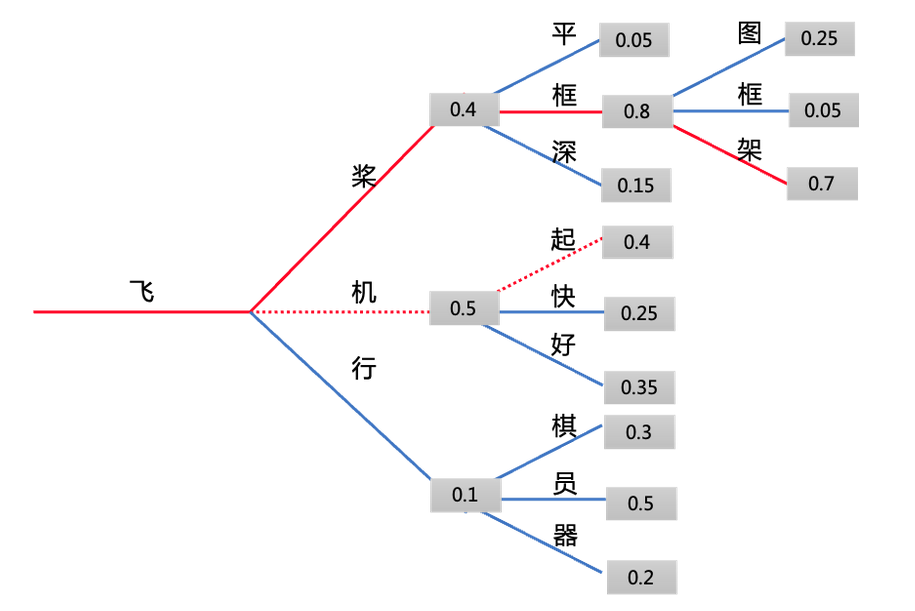
- 结果里还是会出现一些重复内容,一个简单的补救措施是引入
10.3、Sampling
-
Sampling 简介:
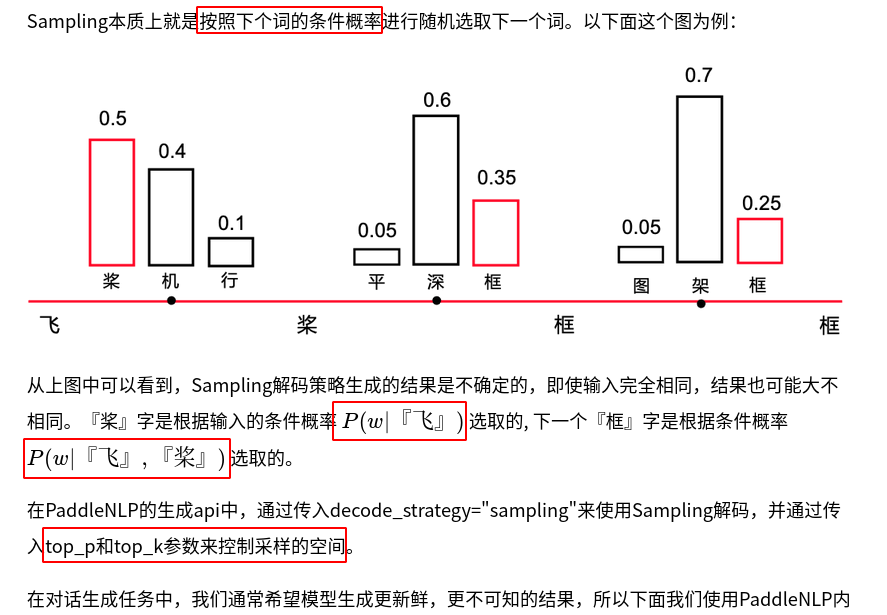
-
temperature的本质是降低了采样随机性,该值越小随机性越低,当temperature=0时,解码的效果就等同与Greedy Search了- 当
temperature变大时,模型在生成文本时更倾向于比较少见的词汇。越大,重新缩放后的分布就越接近均匀采样(让大概率和小概率之间差别没那么明显)。 - 当
temperature变小时,模型在生成文本时更倾向于常见的词。越大,重新缩放后的分布就越接近我们最开始提到的贪婪生成方法(即总是去选择概率最高的那个词,让概率大的更大、让小的变的更小)


- 当
-
文本序列的概率分布:

10.3.1、Top-K Sampling
- 除了
temperature外,还有一个更简单更常用的方法可以避免生成离谱的结果,这就是 Top-K Sampling。Top-K Sampling 的原理如下图所示,可以看到,Top-K Sampling就是每一步取条件概率前 k 大(这里为 5)的结果,将他们的概率重新归一化后再进行采样,这样做是希望在 “得分高” 和 “多样性” 方面做一个折中。显然,当k=1时,其实就等价于贪心搜索。 - 通常来说,
加大 k会产生更多样化、有风险的结果,减小 k则会产生更通用、安全的结果 - Top-K Sampling 缺点:因为
k 值在整个解码中是固定的,所以在所有词的概率分布比较均匀时,Top-K 会过滤掉很多合理的词,而在概率分布非常不平均时(比如前一两个词占据了绝大部分概率),Top-K 又会将一些不合理的词纳入选择
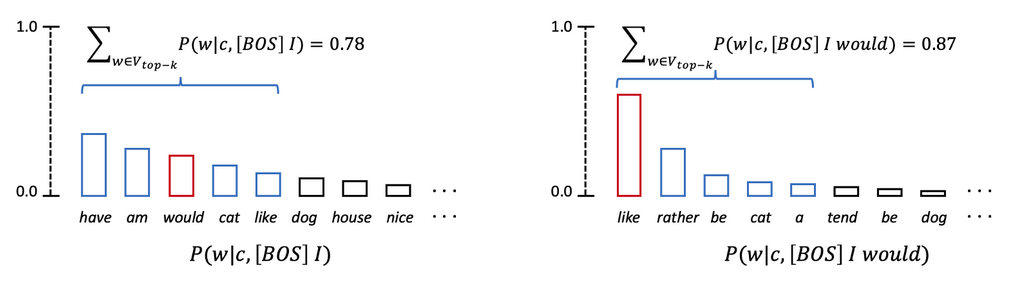
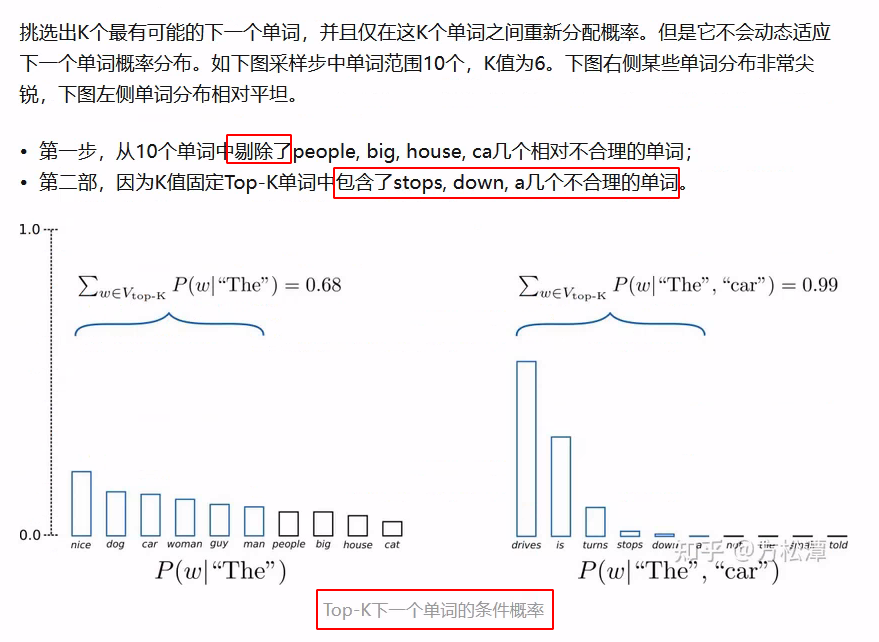
10.3.2、Top-P Sampling
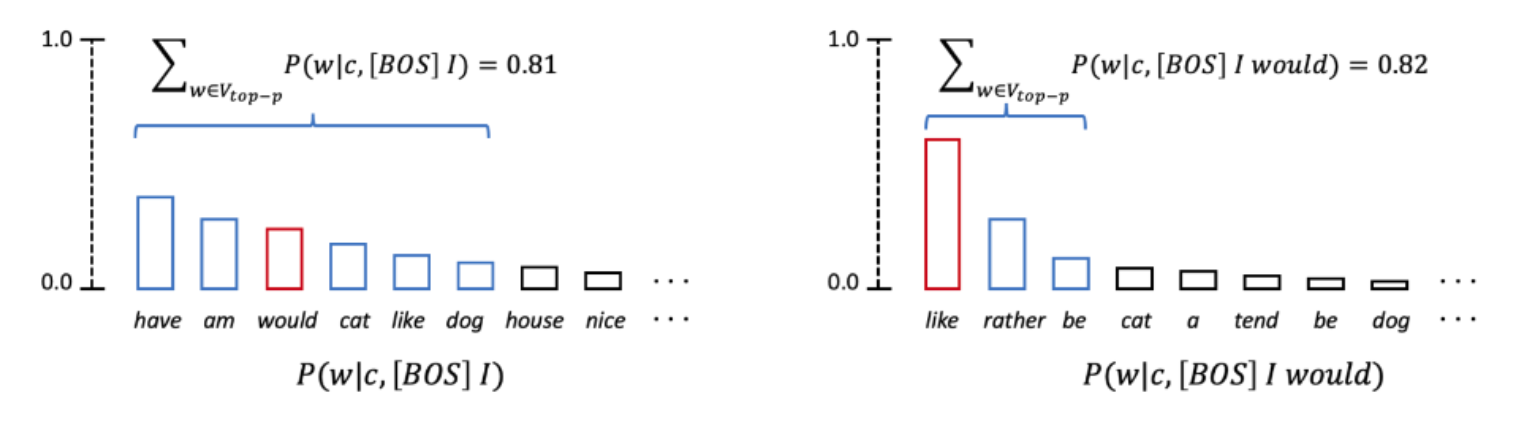
- 相比于 Top-K Sampling,
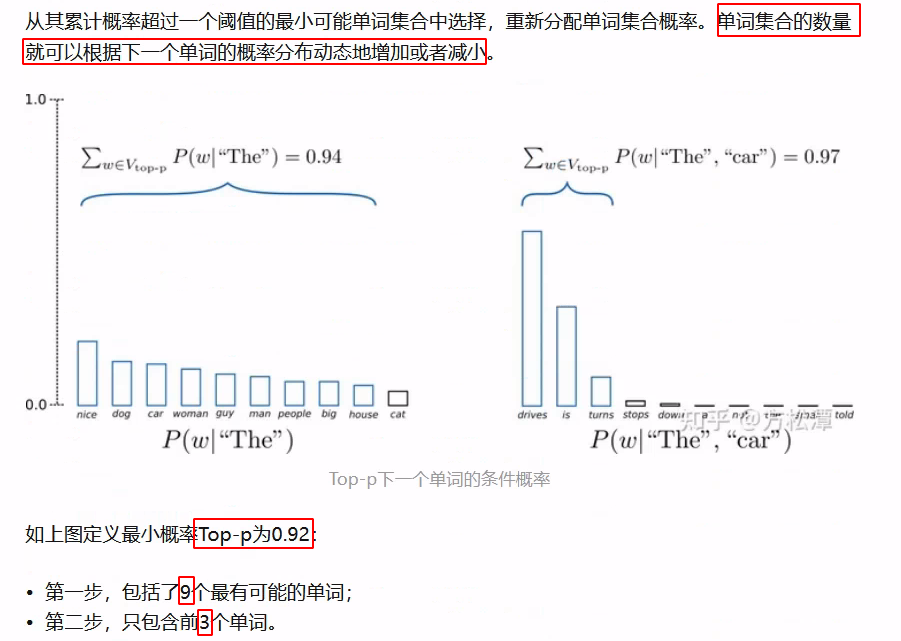
Top-P Sampling可以根据每步的概率分布动态调整采样范围。原理如下图所示,可以看到,p代表采样的阈值,每一步只保留概率最高(sorted)的且概率和刚好超过p的若干个token,下图第一步保留了 6 个;第二部保留了 3 个 - 在实际使用中,Top-K 和 Top-P Sampling 可以同时使用,用于过滤掉一些概率排名很低的不合理的词。
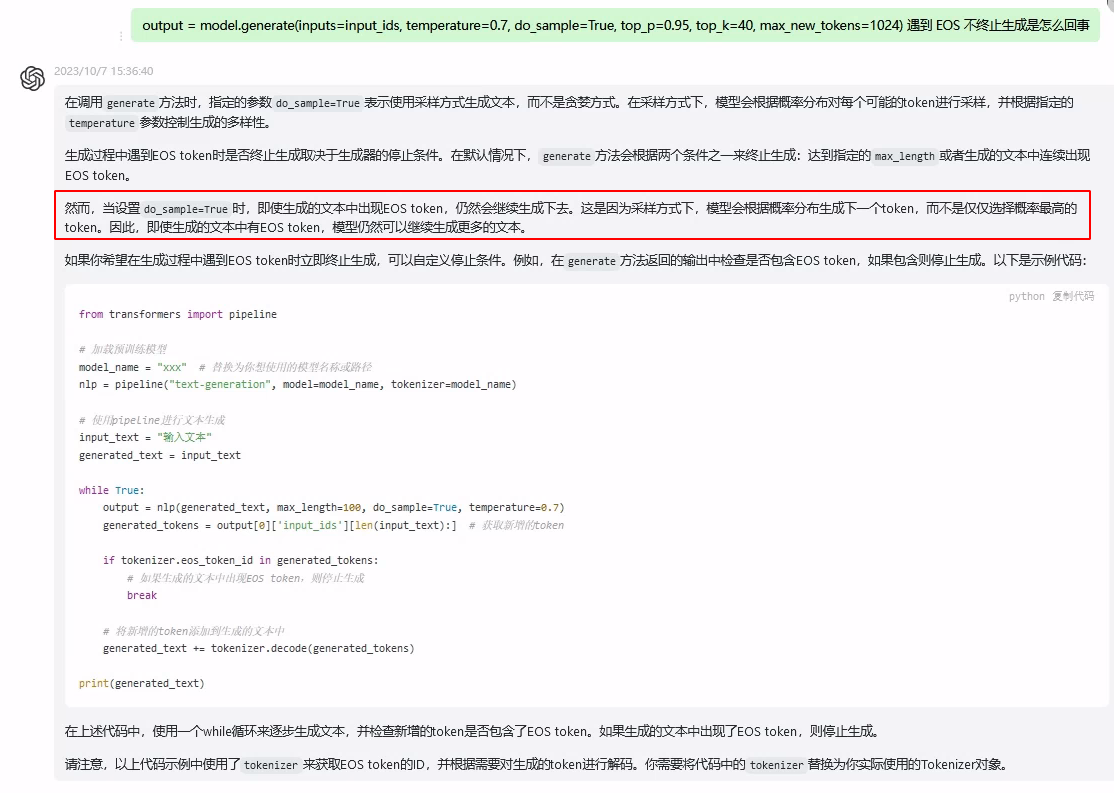
10.4、重复输出,且不终止是怎么回事?
十一、参考资料
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/912596
推荐阅读
相关标签

