
热门标签
热门文章
- 1贪心算法原理_贪心算法不是最优解
- 2token一般出现的位置_token怎么在网页里找
- 3Springboot为啥要有第二级缓存_spring二级缓存有什么用
- 4用递归实现1到n的从小到大排列(数字不重复)_1、给定数组a,其中有n个元素且按照字典序从小到大排列: a={1, 3, 5, 7} 使用递归
- 5编程二十年,38岁Google程序员万字长文给出16条建议,涉创业、技术淘汰、拿大厂offer...值得学习思考_程序员如何创业
- 6数据结构-C语言链表模拟_p=(node)malloc(sizeof(node))
- 7首批成员单位!九州未来加入“算力网络+”先锋计划
- 8MySQL进阶-MySQL管理
- 9关闭和卸载亚信安全助手
- 10AI全栈大模型工程师(十)查询数据库_大模型 数据查询
当前位置: article > 正文
Python解决抓取内容乱码问题(decode和encode解码)_python 下载下拉的二进制文件乱码
作者:小惠珠哦 | 2024-07-31 17:24:03
赞
踩
python 下载下拉的二进制文件乱码
一、乱码问题描述
经常在爬虫或者一些操作的时候,经常会出现中文乱码等问题,如下
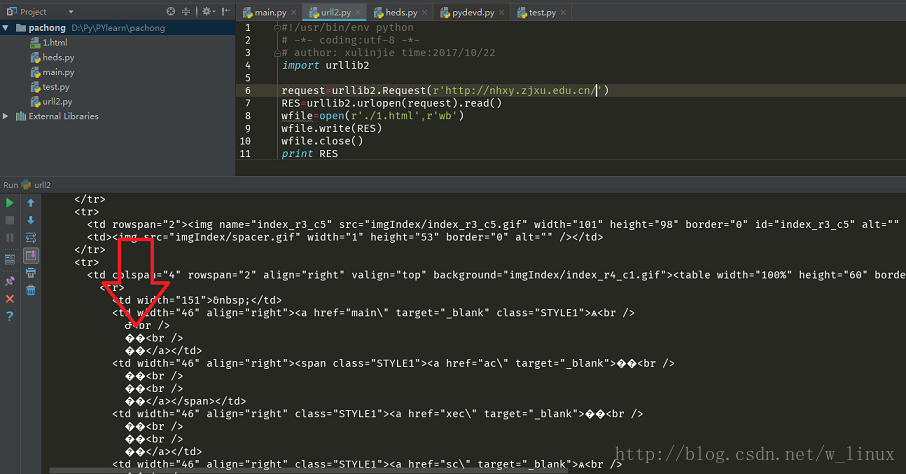
原因是源网页编码和爬取下来后的编码格式不一致
二、利用encode与decode解决乱码问题
字符串在Python内部的表示是unicode编码,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘utf-8’),表示将unicode编码的字符串str2转换成utf-8编码。
decode中写的就是想抓取的网页的编码,encode即自己想设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
但是还要注意:
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断
isinstance(s, unicode)#用来判断是否为unicode
用非unicode编码形式的str来encode会报错
所以最终可靠代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() if isinstance(RES, unicode): RES=RES.encode('utf-8') else: RES=RES.decode('gb2312').encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
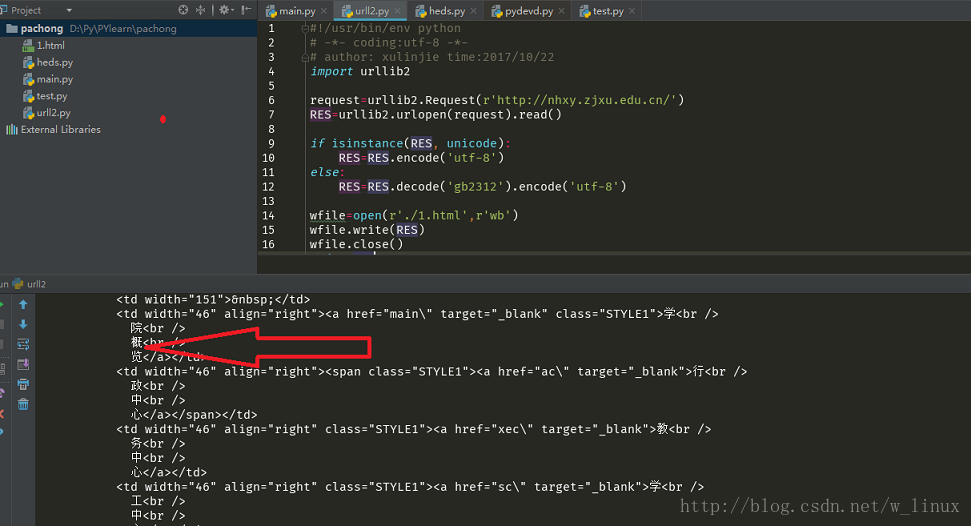
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源代码
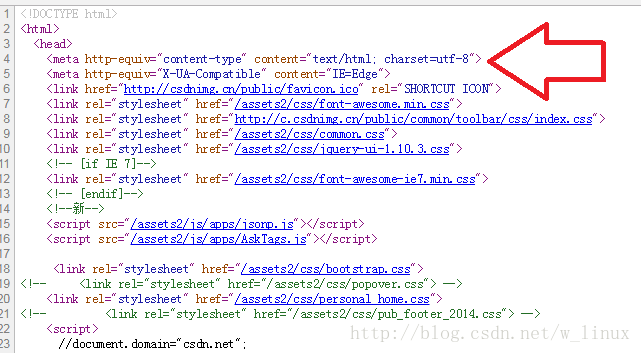
如果源代码中没有charset编码格式显示可以用下面的方法
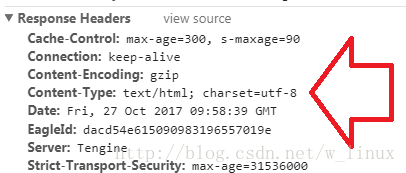
2、检查元素,查看Response Headers
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/909918
推荐阅读
- b站视频下载 ...
赞
踩
相关标签

