
- 1vue3+vite+axios:解决跨域问题_vue3.0 vite跨域代理axios无法替换主路径
- 2“深入探讨Java中的对象拷贝:浅拷贝与深拷贝的差异与应用“_深拷贝和浅拷贝的应用场景 java
- 3同步gitee和github_github page无法同步gitee page
- 4顺序主子式
- 5使用eve-ng模拟器进入山石防火墙的web界面_eve默认账号密码
- 6【数据结构】二叉树(C语言)
- 7python封装前端接口_Python实现封装打包自己写的代码,被python import
- 8(4)jenkins配置gitee令牌详细操作_jenkins使用令牌连接gitee
- 9C++ Reference: Standard C++ Library reference: Containers: queue: queue: emplace_queue c++ referece
- 10Python 微信自动化工具开发系列04_所有微信群的群文件自动同步拷贝到群名对应的新文件夹中(2024年2月可用 支持3.9最新微信)_wxauto
05_es分布式搜索引擎1_es搜索引擎 查询索引库
赞
踩
一、初始elasticsearch
1.elasticsearch简单介绍
①什么是elasticsearch?
开源的分布式搜索引擎,实现海量数据搜索,日志统计,分析,系统监控等功能
②什么是elastic stack?
是以elasticsearch为核心的技术栈,包括beats,Logstash,kibana, elasticsearch
③什么是Lucene?
是Apache开源搜索引擎类库,提供搜索引擎的API
2.正向索引和倒排索引
①什么是文档document和词条term?
文档:每一条数据就是文档
词条:对文档的内容分词
②什么是正向索引?
基于文档id创建索引,查询词条时必须找到文档,然后判断该文档是否包含词条。

③什么是倒排索引?
对文档内容进行分词,对词条创建索引,并记录词条所在文档的信息。
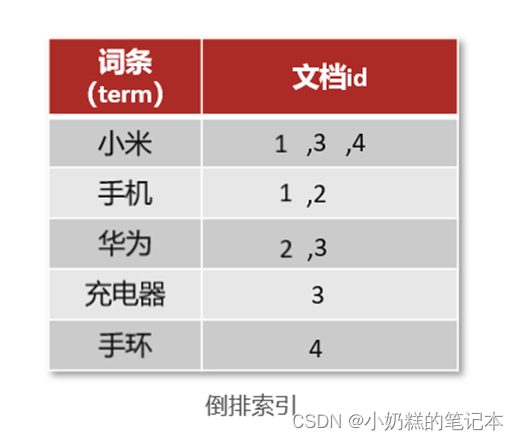
搜索时要进行分词,然后去词条列表查询文档id,通过文档id查询文档,把结果存放在结果集。

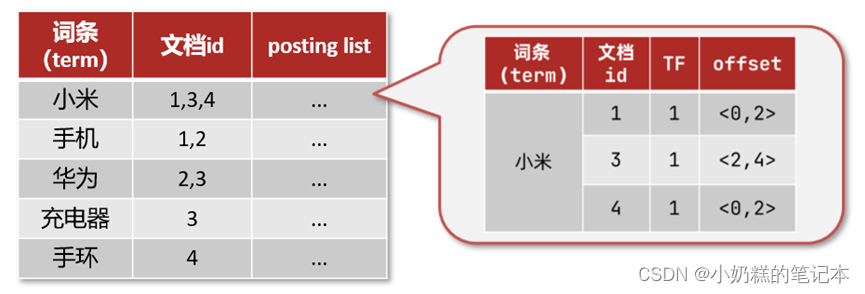
④倒排索引的组成
词条词典:记录所有词条, 词条和倒排列表PostingList之间关系。给词条创建索引,提高查询和插入效率
倒排列表PostingList:记录词条所在的文档id,词条出现频率,词条在文档的位置
3.ES的基本概念
①索引index:
同类型文档的集合。类似Mysql的表table

②文档document:
一条数据就是一个文档,文档数据在es是Json格式。类似Mysql的行row

③字段field:
Json文档的字段。类似Mysql的列
④映射Mapping:
字段的类型约束信息,类似表的结构约束

4.ES-MySQL的架构
ES:海量数据搜索
Mysql:事务操作,数据安全性和一致性

二、索引库操作
1.索引库 (建表)的概念
①mapping是对文档字段的约束。
②mapping约束的属性
type:字段类型(
字符串:text(分词)、keyword(不分词)
数字:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
index:该字段是否用约束,默认true
analyzer:使用的分词器
properties:该字段下的子字段
2.创建索引库
ES通过Restful请求操作索引库和文档。请求内容通过DSL语句表示

创建索引库:创建一个索引库heima,有字段info,email,name有子字段firstName, lastName
查看索引库:GET /索引库名
删除索引库:DELETE /索引库名
添加索引库字段:PUT /索引库名/_mapping
- PUT /heima/_mapping
- {
- "properties":{
- "age":{
- "type":"integer"
- }
- }
- }
3.文档操作(添加数据)
①增

- POST /heima/_doc/1
- {
- "age": 20,
- "info": "这是学生",
- "email": "1111@qq.com",
- "name": {
- "lastName": "wang",
- "firsrName":"zhi"
- }
- }
②删
DELETE /索引库名/_doc/文档id
③改
方式一:根据主键值id全量修改,删除旧文档,新增以下字段文档。此时只有age

- PUT /heima/_doc/1
- {
- "age": 10
- }
方式二:修改某个字段值,只把年龄修改

- POST /heima/_update/1
- {
- "doc":{
- "age": 10
- }
-
- }
④查
GET /索引库名/_doc/文档id
GET /heima/_doc/1
4.文档操作有哪些?
- 创建文档:POST /索引库名/_doc/文档id { json文档 }
- 查询文档:GET /索引库名/_doc/文档id
- 删除文档:DELETE /索引库名/_doc/文档id
- 修改文档:
全量修改:PUT /索引库名/_doc/文档id { json文档 }
增量修改:POST /索引库名/_update/文档id { "doc": {字段}}
三、RestClient操作索引库
1.什么是RestClient
RestClient本质是组装DSL语句,通过http请求发送ES
2.利用JavaRestClient实现创建、删除索引库。判断索引库是否存在
步骤1:导入资料包hotel-demo
步骤2:分析数据结构
①mapping要考虑问题:字段名,数据类型type,是否搜索index,是否分词analyzer(分词器)
 mapping映射
mapping映射
修改:把全部搜索的字段组合放在all字段

步骤3:初始化JavaRestClient
①导入es依赖
- <dependency>
- <groupId>org.elasticsearch.client</groupId>
- <artifactId>elasticsearch-rest-high-level-client</artifactId>
- <version>7.12.1</version>
- </dependency>
②初始化RestHighLevelClient:
- public class HotelIndexTest {
- private RestHighLevelClient client;
- @Test
- void testInit(){
-
- }
- @BeforeEach
- void setUp() {
- this.client = new RestHighLevelClient(RestClient.builder(
- HttpHost.create("http://192.168.137.129:9200")
- ));
- }
- @AfterEach
- void tearDown() throws IOException {
- this.client.close();
- }
-
- }

所有的单元测试,先运行@BeforeEach再@Test,最后@AfterEach
步骤4:
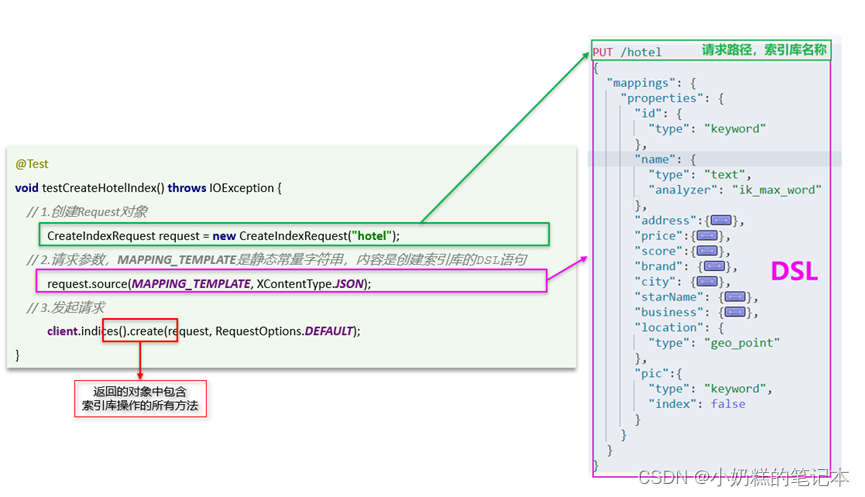
MAPPING_TEMPLATE
- public class HotelConstants {
- public static final String MAPPING_TEMPLATE =
- "{\n" +
- " \"mappings\": {\n" +
- " \"properties\": {\n" +
- " \"id\":{\n" +
- " \"type\": \"keyword\"\n" +
- " },\n" +
- " \"name\":{\n" +
- " \"type\": \"text\",\n" +
- " \"analyzer\": \"ik_max_word\",\n" +
- " \"copy_to\": \"all\"\n" +
- " },\n" +
- " \"address\":{\n" +
- " \"type\": \"keyword\",\n" +
- " \"index\": false\n" +
- " },\n" +
- " \"price\":{\n" +
- " \"type\": \"integer\"\n" +
- " },\n" +
- " \"score\":{\n" +
- " \"type\":\"integer\"\n" +
- " },\n" +
- " \"brand\":{\n" +
- " \"type\":\"keyword\",\n" +
- " \"copy_to\": \"all\"\n" +
- " },\n" +
- " \"city\":{\n" +
- " \"type\":\"keyword\"\n" +
- " }, \n" +
- " \"starName\":{\n" +
- " \"type\":\"keyword\"\n" +
- " },\n" +
- " \"business\":{\n" +
- " \"type\":\"keyword\"\n" +
- " },\n" +
- " \"location\":{\n" +
- " \"type\":\"geo_point\"\n" +
- " },\n" +
- " \"pic\":{\n" +
- " \"type\":\"keyword\",\n" +
- " \"index\":false\n" +
- " },\n" +
- " \"all\":{\n" +
- " \"type\": \"text\",\n" +
- " \"analyzer\": \"ik_max_word\"\n" +
- " }\n" +
- " }\n" +
- " }\n" +
- "}\n";
-
-
- }
①创建索引库
- @Test
- void createHotelIndex() throws IOException {
- // 1.创建request对象(索引库)
- CreateIndexRequest request = new CreateIndexRequest("hotel");
- // 2.请求参数(mapping)
- request.source(MAPPING_TEMPLATE, XContentType.JSON);
- // 3.发送请求(创建)
- client.indices().create(request, RequestOptions.DEFAULT);
- }
②查询索引库是否存在
- @Test
- void getHotelIndex() throws IOException {
- // 1.创建查询对象
- GetIndexRequest request = new GetIndexRequest("hotel");
- // 2.执行查询
- Boolean response = client.indices().exists(request, RequestOptions.DEFAULT);
- System.out.println(response);
- }
③删除索引库
- @Test
- void deleteHotelIndex() throws IOException {
- // 1.创建删除对象
- DeleteIndexRequest request = new DeleteIndexRequest("hotel");
- // 2.执行删除
- client.indices().delete(request,RequestOptions.DEFAULT);
- }
索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
四、RestClient操作文档
1.添加文档client.index()
①查询数据库里面ID号为38609酒店信息
②把查询的信息转换为json插入,id从信息里面获取
- @Test
- void testIndexDocument() throws IOException {
- // 1.根据id查询
- Hotel hotel = hotelService.getById(38609L);
- // 转换为文档数据
- HotelDoc hotelDoc = new HotelDoc(hotel);
-
- // 2.创建request对象
- IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
- // 创建JSON文档
- request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
- // 发送请求
- client.index(request, RequestOptions.DEFAULT);
- }
2.查询文档client.get()
- @Test
- void testGetIndex() throws IOException {
- // 查询请求
- GetRequest request = new GetRequest("hotel","38609");
- // 发送请求
- GetResponse response = client.get(request, RequestOptions.DEFAULT);
- // 获取结果_source的JSON
- String json = response.getSourceAsString();
- // JSON转换为对象
- HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
- System.out.println(hotelDoc);
-
- }
3.更新文档client.update()
- @Test
- void testUpdate() throws IOException {
- // 更新请求
- UpdateRequest request = new UpdateRequest("hotel","38609");
- // 更新字段 K,V 逗号隔开
- request.doc(
- "price","666",
- "starName","四钻"
- );
- // 执行更新
- client.update(request,RequestOptions.DEFAULT);
-
- }
4.根据ID删除文档
- @Test
- void testDelete() throws IOException {
- // 删除请求
- DeleteRequest request = new DeleteRequest("hotel","38609");
- // 执行删除
- client.delete(request,RequestOptions.DEFAULT);
- }
5.批量导入数据BulkRequest
- @Test
- void testBulk() throws IOException {
- // 查询数据
- List<Hotel> hotels = hotelService.list();
- // 创建Request
- BulkRequest request = new BulkRequest();
- // 批量数据
- for (Hotel hotel : hotels) {
- HotelDoc hotelDoc = new HotelDoc(hotel);
- request.add(new IndexRequest("hotel")
- .id(hotelDoc.getId().toString())
- .source(JSON.toJSONString(hotelDoc),XContentType.JSON));
- }
- // 执行添加
- client.bulk(request,RequestOptions.DEFAULT);
- }
6.总结文档操作步骤
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete
- 准备参数(Index和Update时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete
- 解析结果(Get时需要)


