
热门标签
热门文章
- 1Git速成教学,从0到1看这篇就足够了_git从0到1全部流程_git如何拉取远程分支上的代码从0到1详细教程
- 2pandas中drop_duplicates 用法_.drop duplicates (subset ='')
- 3平均月薪15k+?自动化测试工程师?3个月教你从“点工”蜕变为“码农”_自动化测试工程师工资
- 4mysql all privilege权限_mysql all privileges有哪些权限
- 5Git&GitHub入门级教程_git&github 的入门级
- 6主存储器空间的分配和回收 模拟的C++实现
- 7python opencv 显著图转热力图并叠加到原始图_分割图像将输出的分割图像转化成热力图
- 8SCAU华南农业大学数据结构8591 计算next值_数据结构计算next函数值 完整程序
- 9hbase 读写调优_hbase性能优化,看这篇就够了
- 10一文搞懂经销商管理系统:管什么、功能、4类软件推荐_经销商 字段设计
当前位置: article > 正文
基于Hadoop3.2的搜狗网搜索日志行为分析(18)--通过Spark SQL进行离线分析_搜狗网搜索日志管理 hadoop hbase spark
作者:小惠珠哦 | 2024-06-22 03:17:37
赞
踩
搜狗网搜索日志管理 hadoop hbase spark
Spark SQL源自于Shark项目,但是Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark各个组件的相互集成,所以提出了Spark SQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码。
1、数据源
本项目使用HBase中的表sogoulogs数据作为离线分析的数据源。
2、创建Scala项目
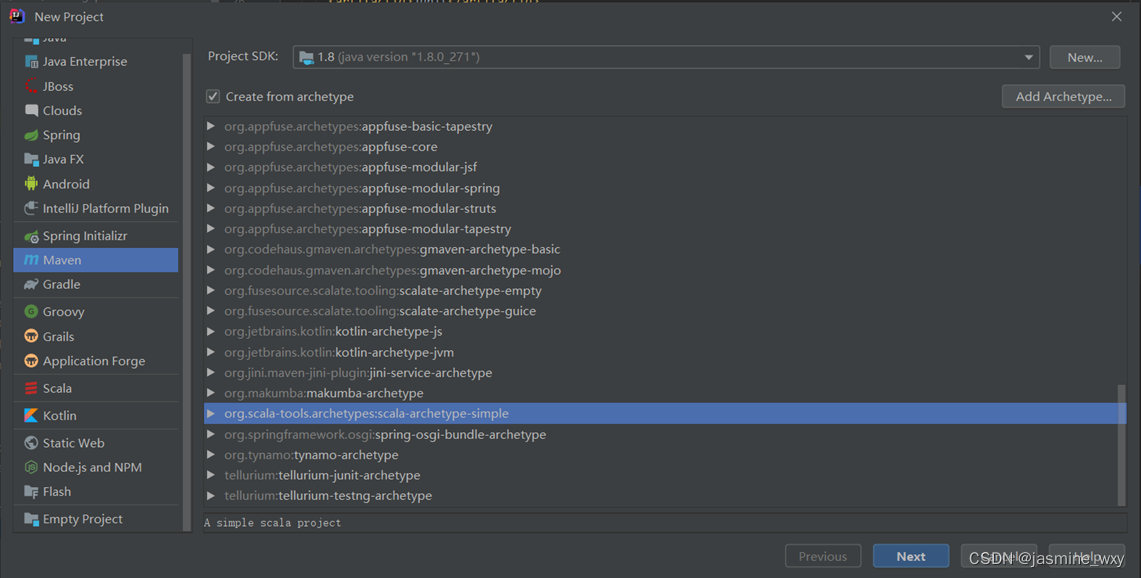
(1)File-> New -> project -> maven -> 勾选Create From archetype,向下选择scala-archetype-simple,点击next
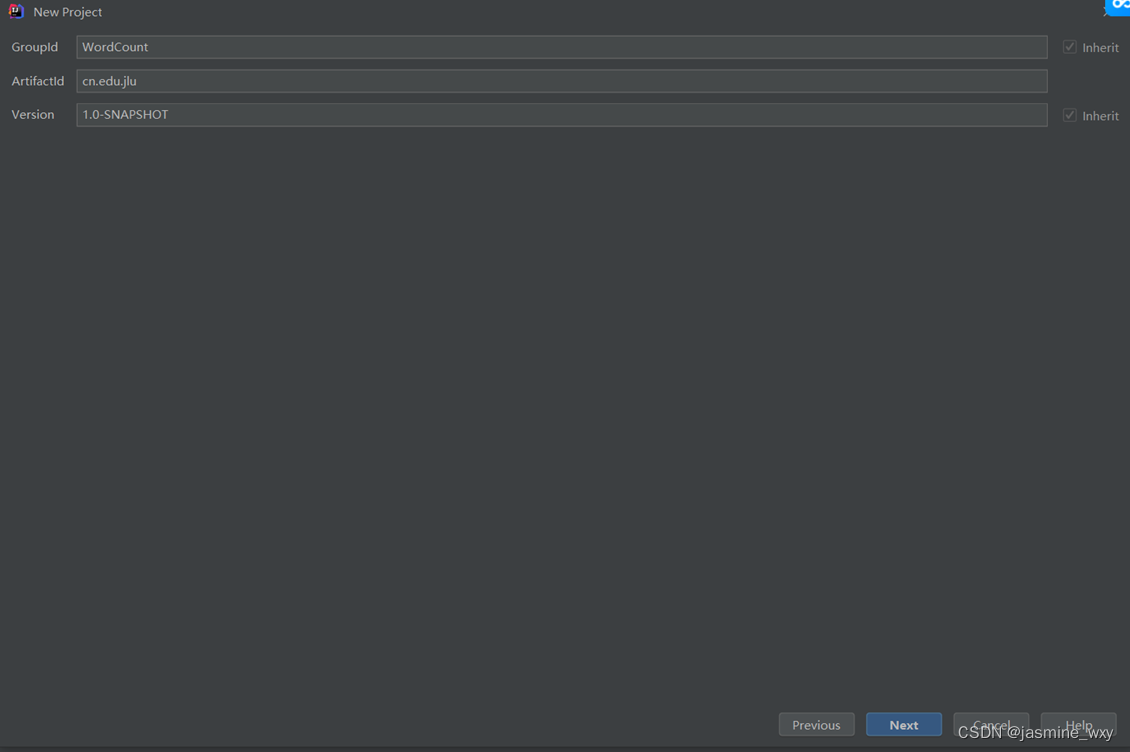
(2)设置GroupID和ArtifactID ,点击next
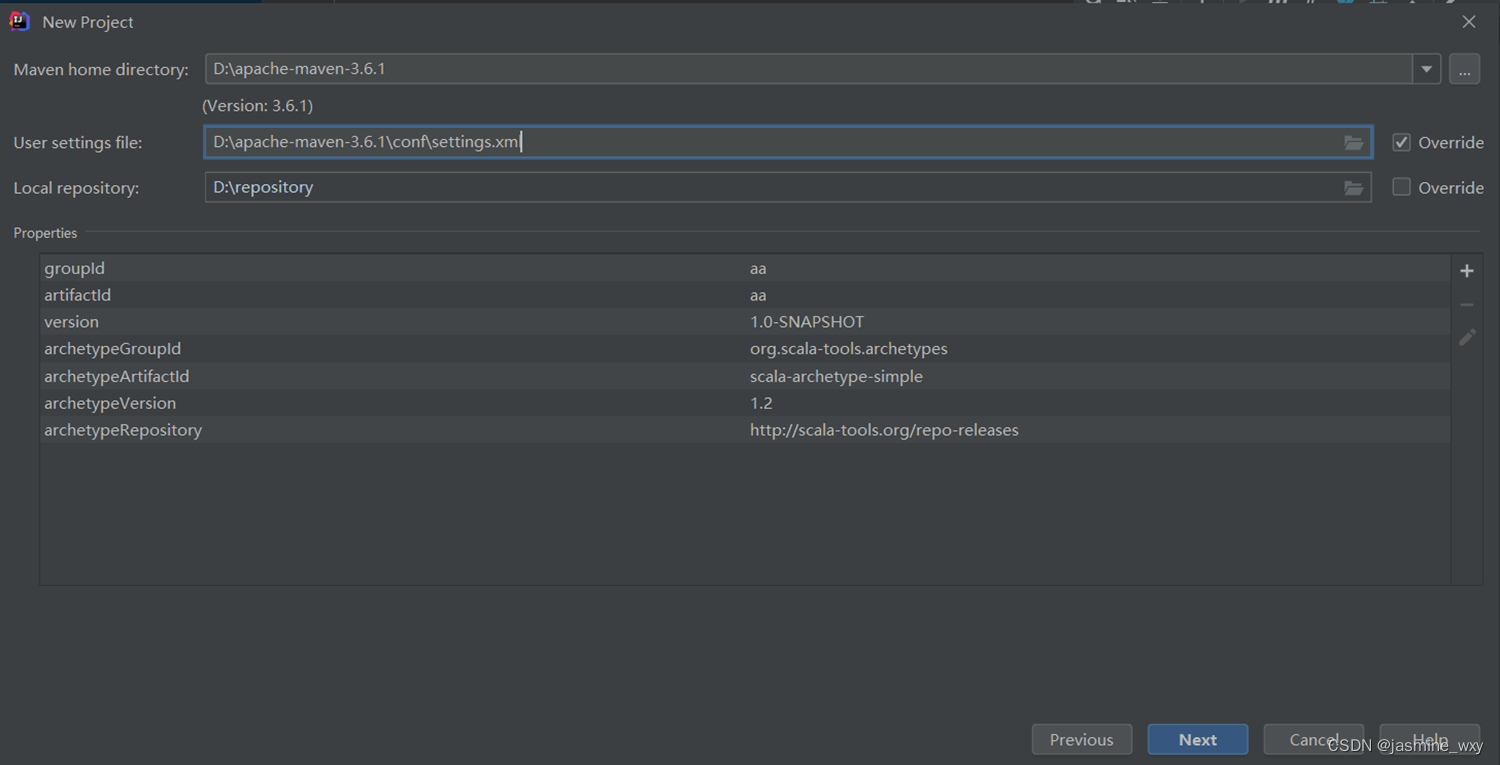
(3)设置Maven相关选项,然后点击next
(4)紧接着一直Next,最后得到的工程架构如下所示
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/745167
推荐阅读
相关标签

