
热门标签
热门文章
- 1Python实现Word、Excel、PPT批量转为PDF_小程序word excel转pdf功能的实现
- 2推荐5个AI辅助生成论文、降低查重率的网站【2024最新】
- 3昇思MindSpore 25天学习打卡营|day1
- 4本地虚拟机Centos7使用Ollama运行llama3中文模型和OpenWebUI访问_ollama中文ui
- 5如何使用ffmpeg高效的压缩视频_ffmpeg 压缩
- 6Java开发实习面试复盘(亚信科技)_亚信考试java开发实习生
- 7华为仓颉可以取代 Java 吗?_仓颉和java的关联和区别
- 8DS-007 顺序表-寻找两个序列的中位数_找出序列a,b的中位数java
- 910款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 10Python的23种设计模式_python 23种设计模式
当前位置: article > 正文
Hadoop WordCount统计小说每个字的出现的次数并排序_wordcount词频统计顺序
作者:小小林熬夜学编程 | 2024-06-17 14:06:41
赞
踩
wordcount词频统计顺序
闲来无事,想看看小说中的什么字出现的频率比较高,就改了一下WordCount的程序。
原理:
主要的核心就是WordCount,那就先说下WordCount。
WordCount:
Map:
对每一行的输入,扫描到一个单词就将key设置为这个字符,将value设置为1。
Combiner:
将同一个key中的链表中的value进行求和求出暂时这个字符的次数,key不变,value为新的次数。
Reduce:
和Combiner的工作是一样的,Combiner就是为了减少中途的数据传输量。
上面就是最基础的WordCount了,我们要改进的是两个操作,一个是能读中文字符,第二个就是按照降序排列。
一:读中文字符:
原来的WorCount是根据空格Tab符进行分割,分割后是一个个的单词,而我们要将其改为中文字符就要用正则表达式的匹配了,在“UTF-8“编码下的中文字符的正则表达式为“[\\u4e00-\\u9fa5]”。(一定要小心的编码,如果编码不对结果就会出现错误,可以将文本主动保存为utf-8格式的就可以了。)然后将所有的找出来作为key就可以了。
- Pattern p=Pattern.compile("[\\u4e00-\\u9fa5]");
- Matcher matcher = p.matcher(line);
- while (matcher.find()) {
- word.set(matcher.group());
- context.write(word, one);
- //System.out.println(word);
- }
二:降序排列:
这个我一开始以为可以很简单的,将结果并没有我想象的那么简单,相当于在程序里执行了两次作业,一次统计词频,一次专门排序。排序作业首先在map中将前面结果中的key,value中的值对调,所以现在key是词频,而value是汉字,然后重写IntWritable的 Comparator 类:
- private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
- public int compare(WritableComparable a, WritableComparable b) {
- return -super.compare(a, b);
- }
-
- public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
- return -super.compare(b1, s1, l1, b2, s2, l2);
- }
- }
然后设置一下:
sortJob.setSortComparatorClass(IntWritableDecreasingComparator.class);
完整代码:
-
- import java.io.IOException;
- import java.util.Random;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.io.WritableComparable;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
- import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import java.util.regex.*;
- public class Dedup {
- public static class TokenizerMapper extends
- Mapper<Object, Text, Text, IntWritable> {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- private String pattern = "[^\\u4e00-\\u9fa5]"; // 正则表达式,代表不是0-9, a-z, A-Z的所有其它字符,其中还有下划线
- Pattern p=Pattern.compile("[\\u4e00-\\u9fa5]");
- public void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String line = value.toString().toLowerCase(); // 全部转为小写字母
- // line = line.replaceAll(pattern, " "); // 将非0-9, a-z, A-Z的字符替换为空格
- //String itr[] = line.split(" ");
- //for (int i=0;i<itr.length;i++) {
- Matcher matcher = p.matcher(line);
- while (matcher.find()) {
- word.set(matcher.group());
- context.write(word, one);
- //System.out.println(word);
- }
-
- //}
- }
- }
- public static class IntSumReducer extends
- Reducer<Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
-
- private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
- public int compare(WritableComparable a, WritableComparable b) {
- return -super.compare(a, b);
- }
-
- public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
- return -super.compare(b1, s1, l1, b2, s2, l2);
- }
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args)
- .getRemainingArgs();
- FileSystem fs = FileSystem.get(conf);
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- if(fs.exists(new Path(otherArgs[1])))
- {
- fs.delete(new Path(otherArgs[1]));
- }
- Path tempDir = new Path("wordcount-temp-" + Integer.toString(
- new Random().nextInt(Integer.MAX_VALUE))); //定义一个临时目录
-
- Job job = new Job(conf, "word count");
- job.setJarByClass(Dedup.class);
- try{
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
-
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
-
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, tempDir);//先将词频统计任务的输出结果写到临时目
- //录中, 下一个排序任务以临时目录为输入目录。
- job.setOutputFormatClass(SequenceFileOutputFormat.class);
- if(job.waitForCompletion(true))
- {
- Job sortJob = new Job(conf, "sort");
- sortJob.setJarByClass(Dedup.class);
-
- FileInputFormat.addInputPath(sortJob, tempDir);
- sortJob.setInputFormatClass(SequenceFileInputFormat.class);
-
- /*InverseMapper由hadoop库提供,作用是实现map()之后的数据对的key和value交换*/
- sortJob.setMapperClass(InverseMapper.class);
- /*将 Reducer 的个数限定为1, 最终输出的结果文件就是一个。*/
- sortJob.setNumReduceTasks(1);
- FileOutputFormat.setOutputPath(sortJob, new Path(otherArgs[1]));
-
- sortJob.setOutputKeyClass(IntWritable.class);
- sortJob.setOutputValueClass(Text.class);
- /*Hadoop 默认对 IntWritable 按升序排序,而我们需要的是按降序排列。
- * 因此我们实现了一个 IntWritableDecreasingComparator 类,
- * 并指定使用这个自定义的 Comparator 类对输出结果中的 key (词频)进行排序*/
- sortJob.setSortComparatorClass(IntWritableDecreasingComparator.class);
- //fs.delete(tempDir);
- if(sortJob.waitForCompletion(true))//删除中间文件
- fs.delete(tempDir);
- System.exit(sortJob.waitForCompletion(true) ? 0 : 1);
- }
- }finally{
- fs.delete(tempDir);
- }
- }
- }

最后的结果:
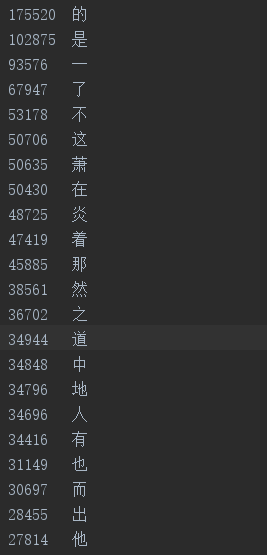
看看前面的“萧”和“炎”字,没错这就是斗破苍穹。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/731492
推荐阅读
相关标签

