
- 12023年了学Java还能找到工作么?_2023 java就业行情分析
- 2虚拟机中docker容器无法连接网络问题的解决方法_ubuntu dokcer pull没网
- 3scanf函数不安全: C4996 ‘scanf‘: This function or variable may be unsafe. Consider using scanf_s instead_error c4996: 'scanf': this function or variable ma
- 4GPT模型介绍并且使用pytorch实现一个小型GPT中文闲聊系统_利用pytorch实现gpt
- 5NLP与LLM:深入对比_nlp llm
- 6Paragon NTFS2023Mac读取、写入外置移动硬盘软件_paragon ntfs for mac怎么用
- 7通俗易懂的GPT原理简介
- 8Stable-Diffusion的WebUI部署实战_nohup bash webui.sh -f --nowebui
- 9flink1.18源码本地调试环境
- 10【opencv】示例-detect_mser.cpp 使用 MSER 算法来检测图像中的极值区域
【动手深度学习-笔记】注意力机制(三)多头注意力_多头注意力如何融合
赞
踩
紧接上回:【动手深度学习-笔记】注意力机制(二)注意力评分函数
在实践中,我们希望模型可以基于相同的注意力机制学习到不同的行为,抽取不同的信息(比如长距离依赖关系和短距离依赖关系),再将这些信息组合起来。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的
h
h
h组不同的线性投影(linear projections)来变换查询、键和值,并行地送入到注意力汇聚,再将
h
h
h组汇聚结果拼接到一起。
这种设计被称作多头注意力(multihead attention),融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
这里的“头”的概念类似于“通道”的概念,一个头表示一个注意力汇聚。
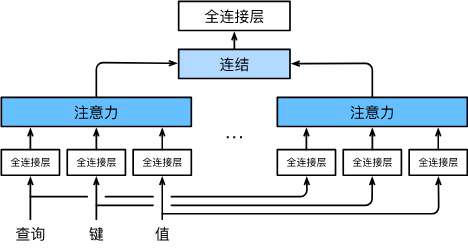
模型
给定查询
q
∈
R
d
q
\mathbf{q} \in \mathbb{R}^{d_q}
q∈Rdq,键
k
∈
R
d
k
\mathbf{k} \in \mathbb{R}^{d_k}
k∈Rdk,值
v
∈
R
d
v
\mathbf{v} \in \mathbb{R}^{d_v}
v∈Rdv,每个注意力头
h
i
(
i
=
1
,
…
,
h
)
\mathbf{h}_i(i = 1, \ldots, h)
hi(i=1,…,h)的计算方法:
h
i
=
f
(
W
i
(
q
)
q
,
W
i
(
k
)
k
,
W
i
(
v
)
v
)
∈
R
p
v
,
(1)
\mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v},\tag{1}
hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,(1)
原本
q
\mathbf{q}
q、
k
\mathbf{k}
k、
v
\mathbf{v}
v的维度分别为
d
q
d_q
dq、
d
k
d_k
dk、
d
v
d_v
dv,经过
W
i
\mathbf{W}_i
Wi线性投影为
p
q
p_q
pq、
p
k
p_k
pk、
p
v
p_v
pv维度;
输入到注意力汇聚函数
f
f
f得到汇聚结果
h
i
∈
R
p
v
\mathbf{h}_i\in \mathbb{R}^{p_v}
hi∈Rpv,
f
f
f可以是加性注意力或者是缩放点积注意力等;
然后将得到的
h
i
\mathbf{h}_i
hi组合,经过
W
o
∈
R
p
o
×
h
p
v
\mathbf W_o\in\mathbb R^{p_o\times hp_v}
Wo∈Rpo×hpv进行另一个线性转换,得到最终输出:
W
o
[
h
1
⋮
h
h
]
∈
R
p
o
.
其中的可学习参数为 W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)∈Rpq×dq、 W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)∈Rpk×dk、 W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)∈Rpv×dv、 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times hp_v} Wo∈Rpo×hpv;
每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
参考
10.5. 多头注意力 — 动手学深度学习 2.0.0-beta1 documentation

