- 1AI 绘画Stable Diffusion 研究(十二)SD数字人制作工具SadTlaker插件安装教程_sadtalker插件安装
- 2【技术美术图形部分】AO理论及优化 AO贴图如何参与渲染
- 3鸿蒙系统与Android有何不同?_华为和安卓的区别
- 475道经典AI面试题,我就想把你们安排的明明白白的!(含答案)_ai面试题库及答案
- 5Android 自定义View 之 Dialog弹窗_android 自定义dialog
- 6Python小白逆袭大神Day03课程总结_inflating: home/aistudio/data/data31557/20200422.j
- 7Android将Widget添加到自己的应用程序_android 自己的app怎么使用其他app的widget
- 8JAVA如何把一个float四舍五入到小数点后2位,4位,或者其它指定位数._将float四舍五入保留2位,怎么做
- 9Linux开发板循环显示红绿蓝_linux显示三种颜色代码
- 10YOLOv5结合BiFPN:BiFPN网络结构调整,BiFPN训练模型训练技巧_yolov5+bifpn修改
【学习笔记】【Pytorch】五、DataLoader的使用
赞
踩
学习地址
主要内容
一、DataLoader模块介绍
介绍:分配数据集。
二、DataLoader类的使用
作用:数据加载器。组合数据集和采样器,在给定数据集上时可迭代的。
一、DataLoader模块介绍
from torch.utils.data import DataLoader
- 1
介绍:通常在使用pytorch训练神经网络时,DataLoader模块是整个网络训练过程中的基础前提且尤为重要,其主要作用是根据传入接口的参数将训练集分为若干个大小为batch size的batch以及其他一些细节上的操作。
DataLoader.py文件结构:
二、DataLoader类的使用
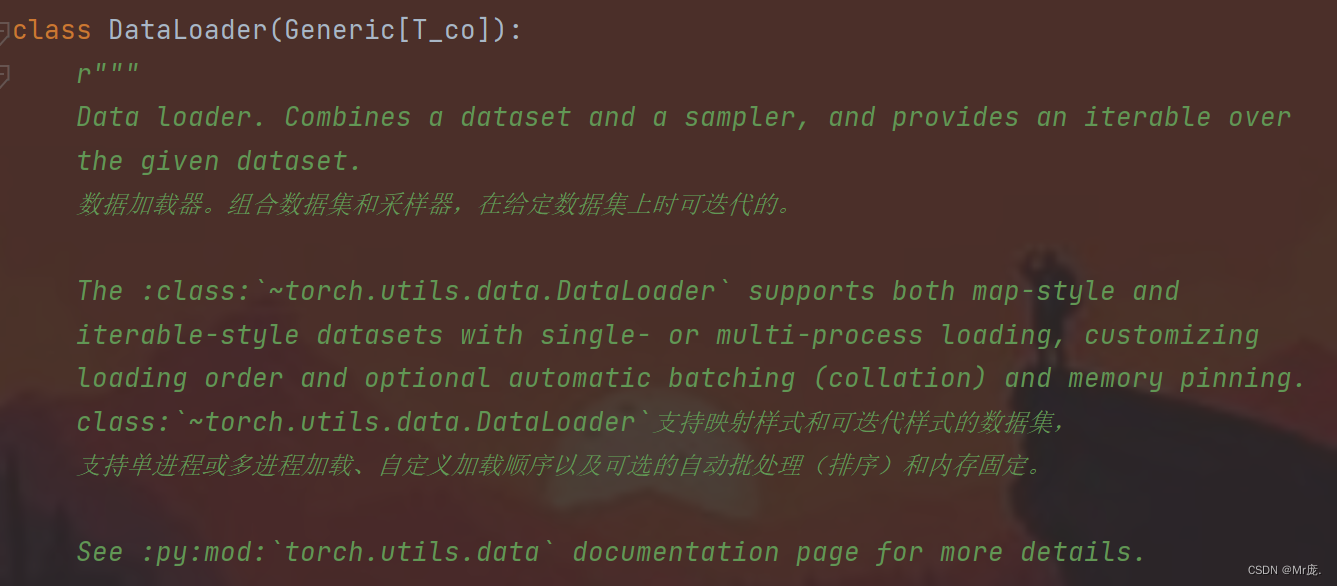
作用:数据加载器。组合数据集和采样器,在给定数据集上时可迭代的。
1.使用说明
【实例化】DataLoader(dataset: Dataset[T_co],
batch_size: Optional[int] = 1,
shuffle: Optional[bool] = None,
sampler: Union[Sampler, Iterable, None] = None,
batch_sampler: Union[Sampler[Sequence],
Iterable[Sequence], None] = None,
num_workers: int = 0,
collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0,
worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False,
pin_memory_device: str = “”)
-
作用:创建一个数据集的实例。
-
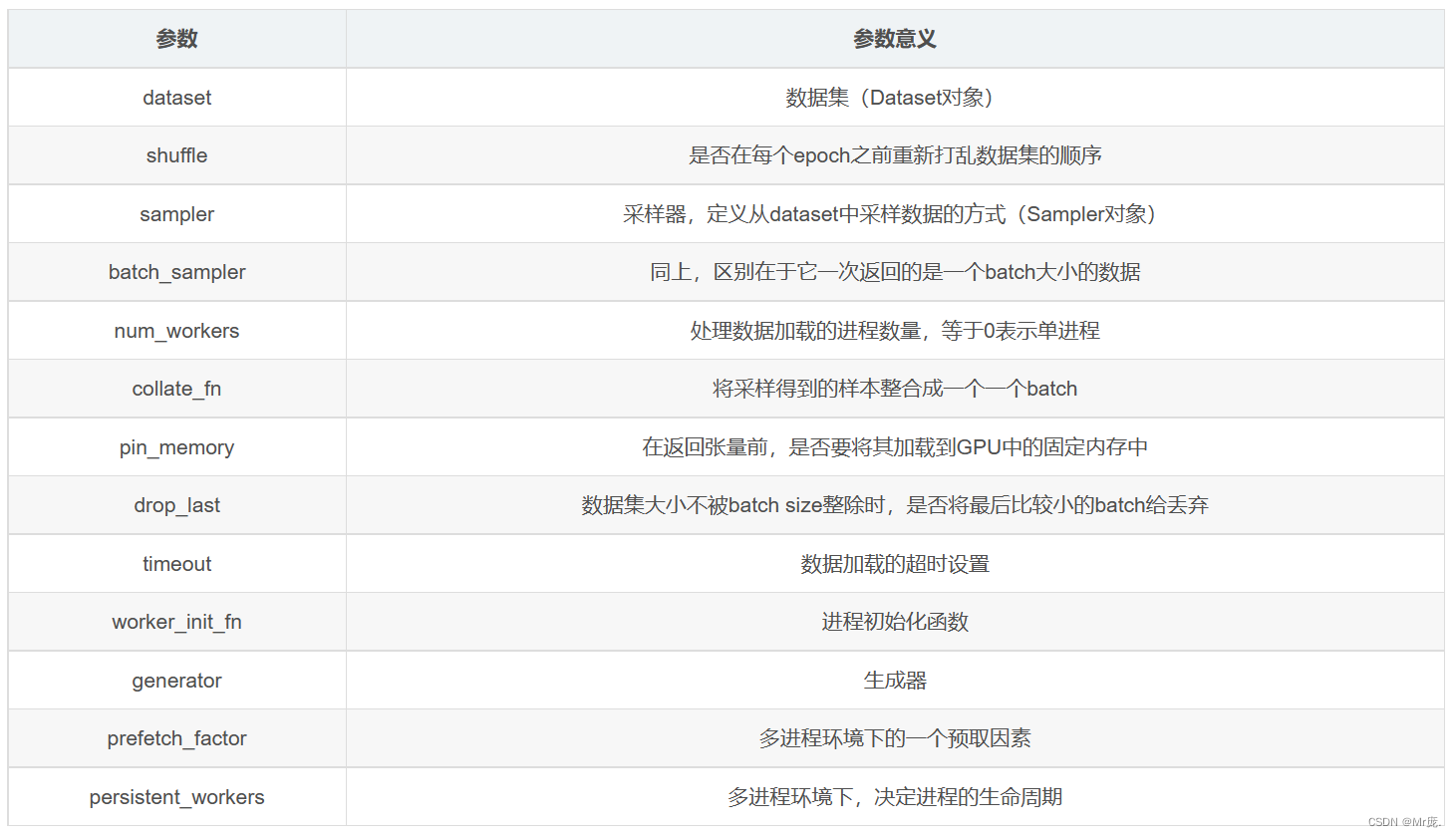
参数说明:
batch_size(int,可选):每个batch(批次)要加载多少个样本(默认值:1)。
-
例子:
# 创建 CIFAR10 实例,测试集(注:初始为PIL图片)
test_set = datasets.CIFAR10(root="./dataset", train=False, transform=transforms.ToTensor())
# 创建 DataLoader 实例
test_loader = DataLoader(dataset=test_set, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
- 1
- 2
- 3
- 4
- 5
【可迭代对象】for data in DataLoader_object
- 作用:依次遍历每一个batch(批次),每一个batch有batch_size张图片。
for data in test_loader: # 可迭代对象
imgs, targets = data # 两个参数
# torch.Size([4, 3, 32, 32]),参数1-打包几(batch_size)张图片;参数2-图片通道;参数3、4-图片像素大小
print(imgs.shape)
# tensor([3, 3, 8, 9]),4张图片的分别的类别索引
print(targets)
- 1
- 2
- 3
- 4
- 5
- 6
2.代码实现
from torch.utils.tensorboard import SummaryWriter from torchvision import transforms, datasets from torch.utils.data import DataLoader # 创建 CIFAR10 实例,测试集(注:初始为PIL图片) test_set = datasets.CIFAR10(root="./dataset", train=False, transform=transforms.ToTensor()) # 创建 DataLoader 实例 test_loader = DataLoader(dataset=test_set, batch_size=4, shuffle=True, num_workers=0, drop_last=False) # 测试数据集中的第一张图片及target img, target = test_set[0] # __getitem__:下标获取类中对应元素值 print(img.shape) print(target) writer = SummaryWriter("dataloader_logs") # 创建实例 print("test_loader-len:", len(test_loader)) for epoch in range(2): # 演示不同epoch,数据集的顺序是否打乱(shuffle=True) step = 0 for data in test_loader: # 可迭代对象 imgs, targets = data # torch.Size([4, 3, 32, 32]),参数1-打包几(batch_size)张图片;参数2-图片通道;参数3、4-图片像素大小 print("\nimgs.shape:\n", imgs.shape) # tensor([3, 3, 8, 9]),4张图片的分别的类别索引 print("\ntargets:\n", targets) writer.add_images("Epoch {} test_data".format((epoch)), imgs, step) # 注:writer.add_image()适用于单张图片 step += 1 writer.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
控制台输出:
torch.Size([3, 32, 32]) 3 test_loader-len: 2500 imgs.shape: torch.Size([4, 3, 32, 32]) targets: tensor([1, 1, 4, 6]) imgs.shape: torch.Size([4, 3, 32, 32]) targets: tensor([9, 7, 8, 0]) .... .... ....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
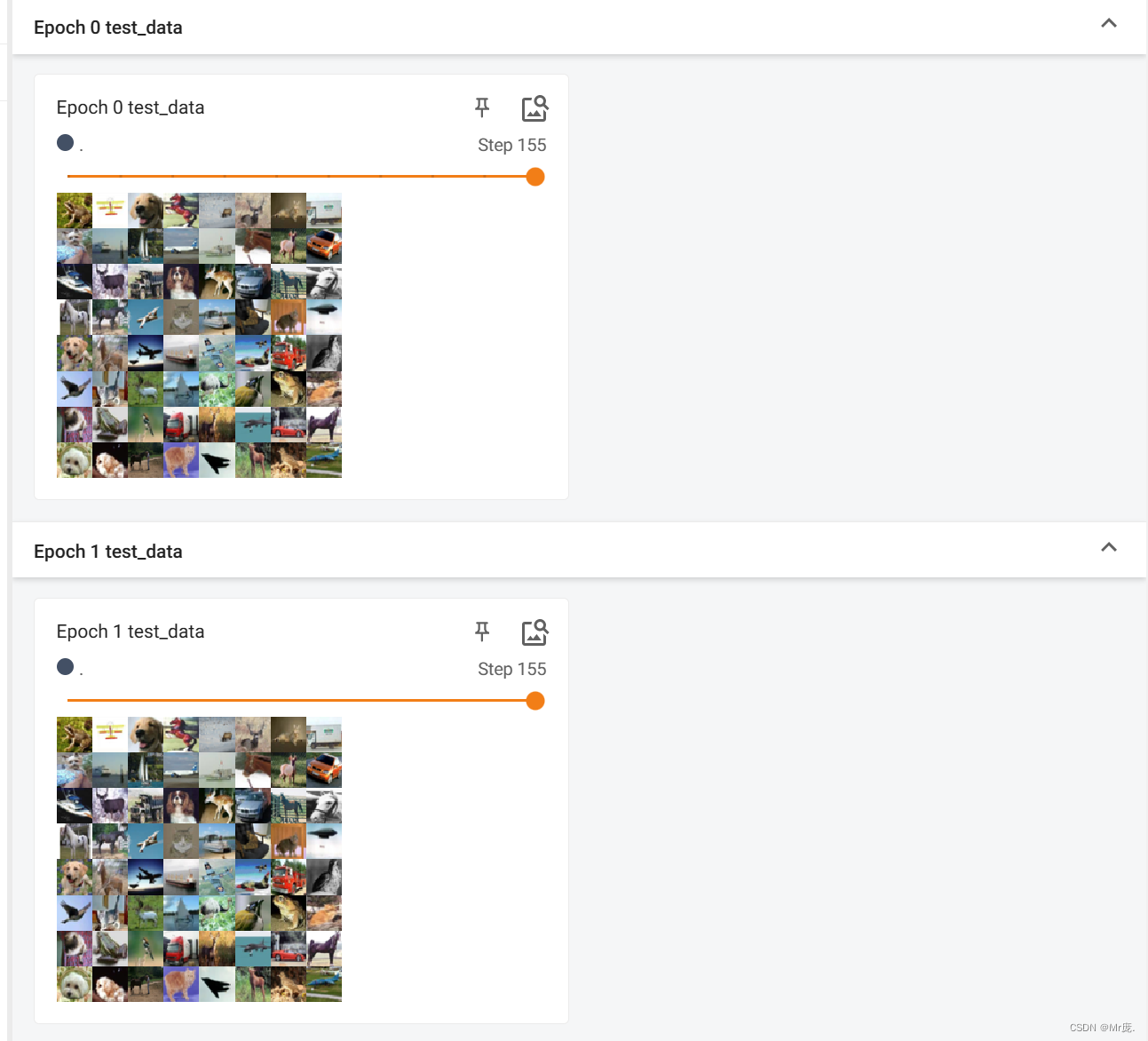
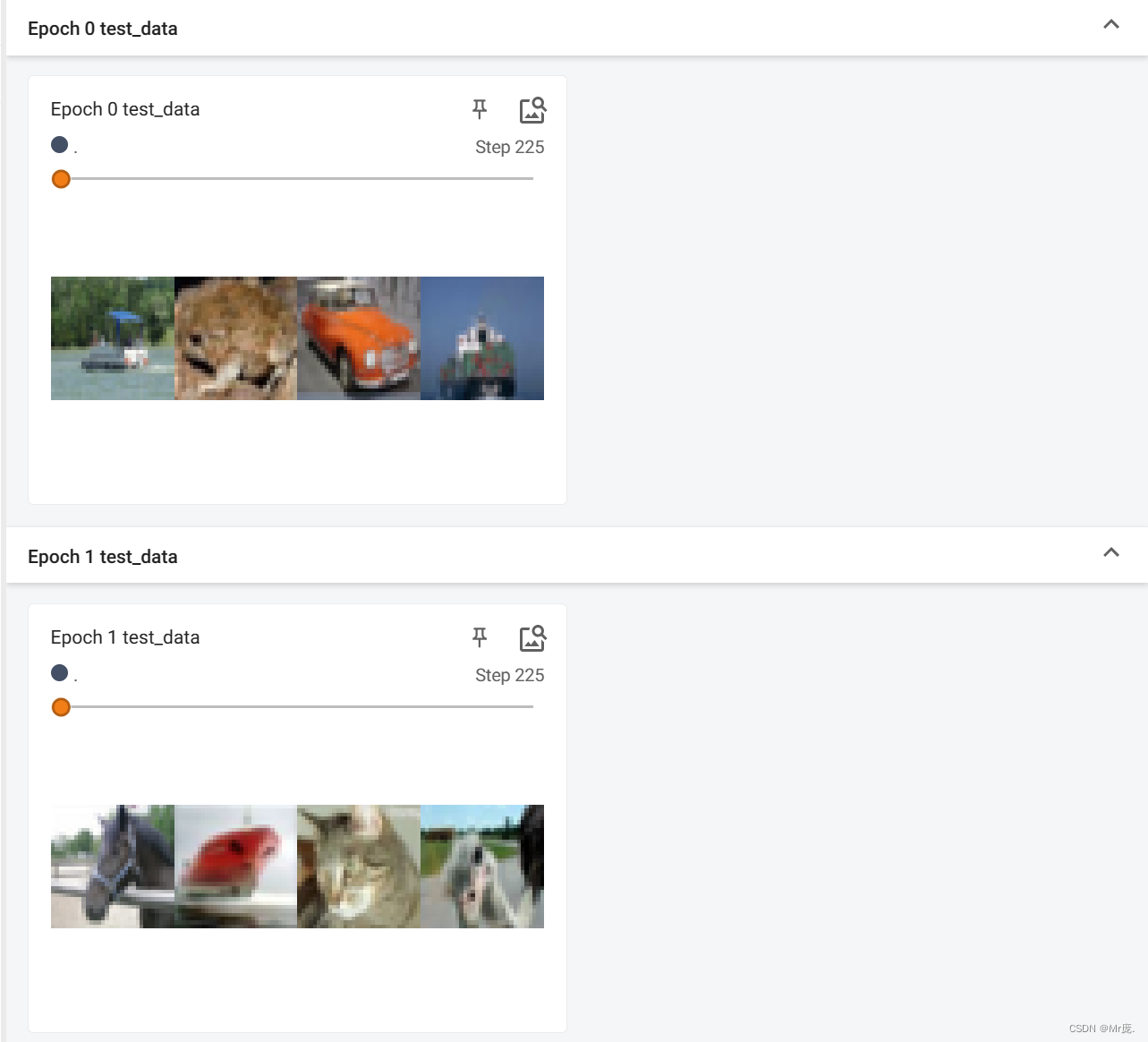
TensorBoard输出:
- 不同epoch,数据集的顺序打乱。(shuffle=True)
- 数据集大小不被batch size整除时,不将最后比较小的batch给丢弃。(drop_last=False)
- batch_size=4
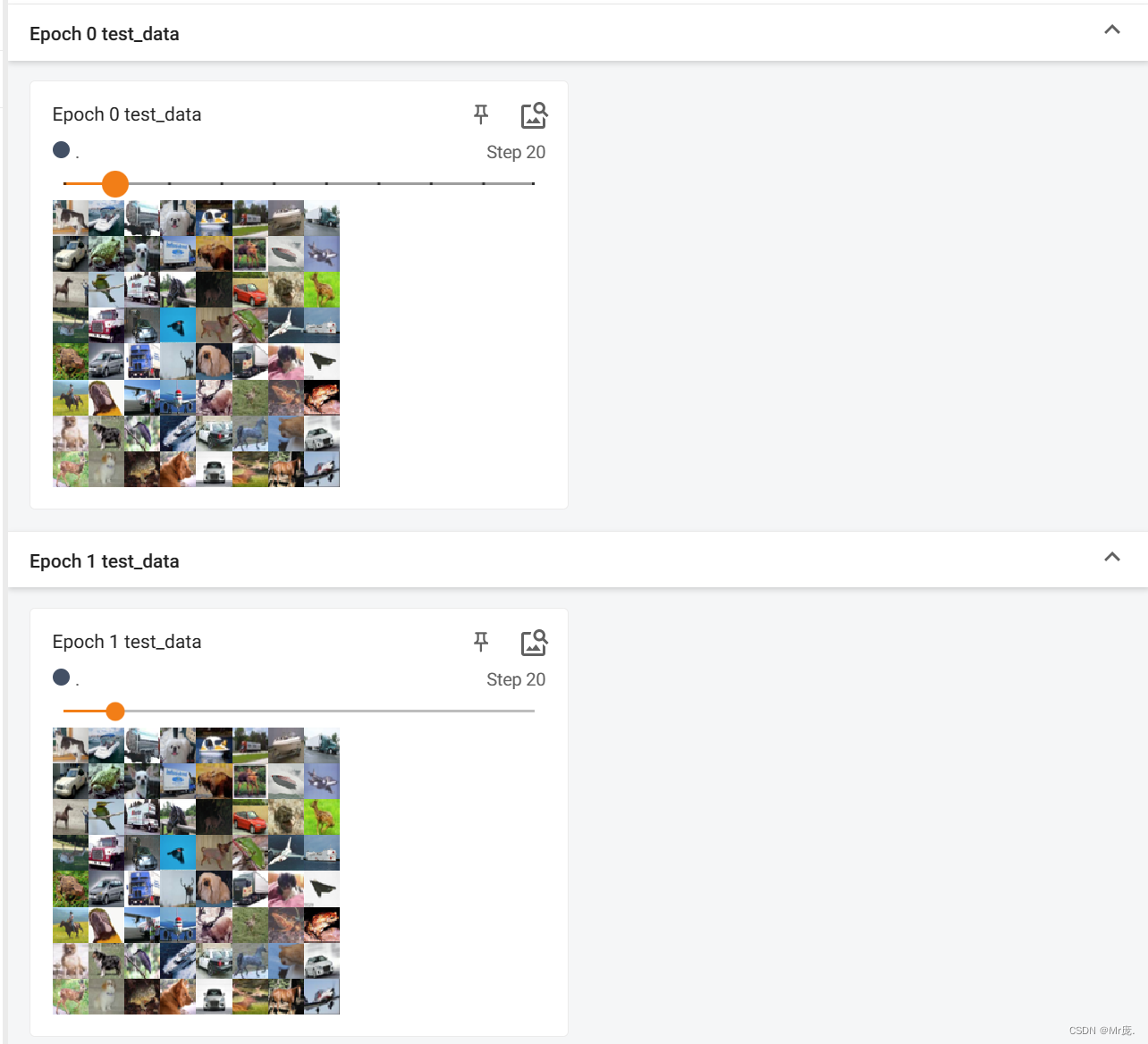
TensorBoard输出: - 不同epoch,数据集的顺序不打乱。(shuffle=False)
- 数据集大小不被batch size整除时,不将最后比较小的batch给丢弃。(drop_last=False)
- batch_size=64
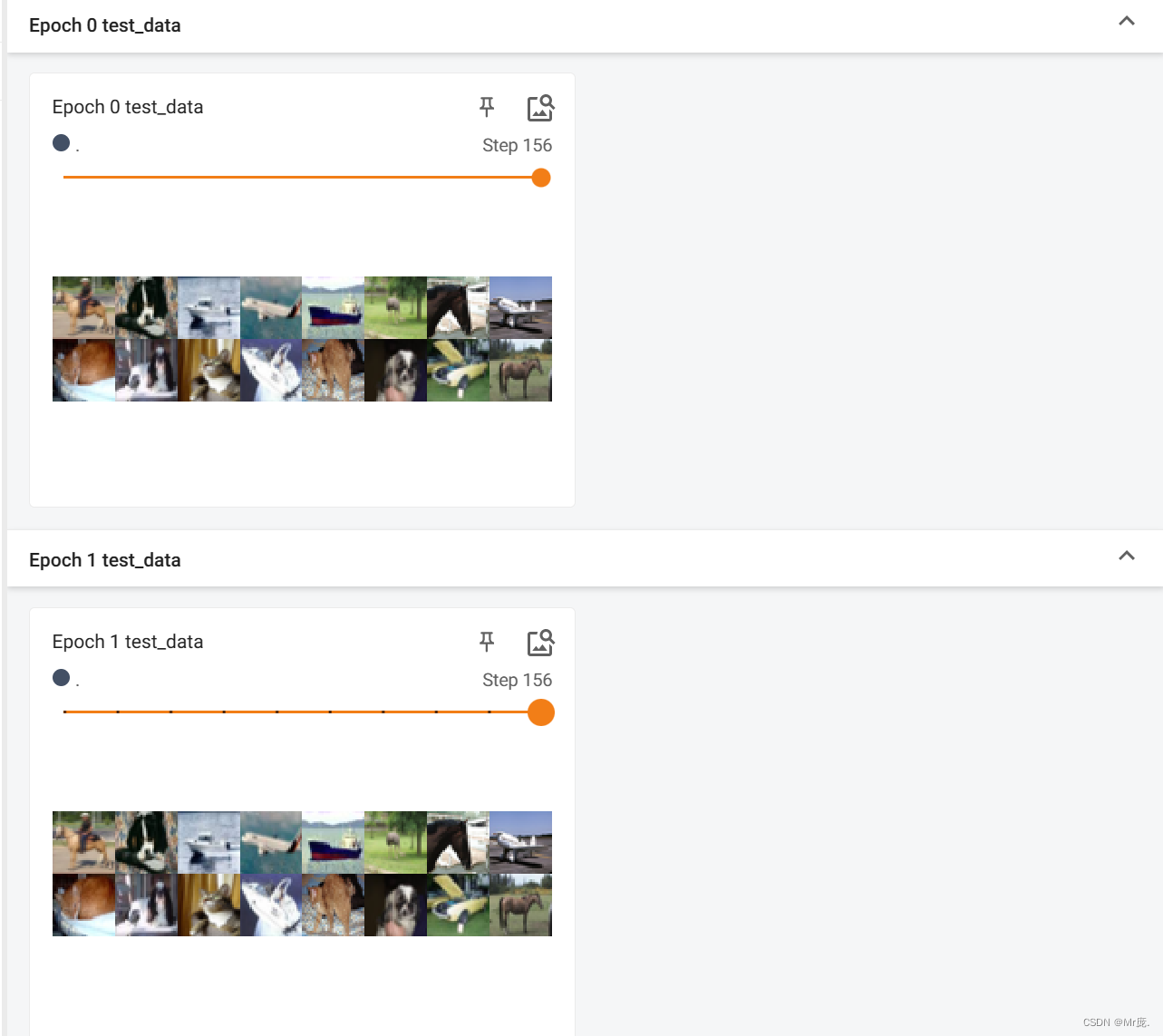
TensorBoard输出:
- 数据集大小不被batch size整除时,将最后比较小的batch给丢弃。(drop_last=True)