
热门标签
热门文章
- 1android SrollView的内容发生变化时自动滚动的处理_android scrollview因内容改自己滚动
- 2Mel spectrum梅尔频谱与MFCCs_梅尔频谱和mfcc区别
- 3一文解读:Stable Diffusion 3究竟厉害在哪里?_stable diffusion 3 rectified flows
- 4云安全与云计算的关系
- 5java中upload怎么用_SpringMVC上传文件FileUpload使用方法详解
- 6鸿蒙打包Flutter为HAP流程_flutter怎么打包hap
- 7小米安卓春招面试一面
- 8Soft Robotics:两栖环境下螃蟹仿生机器人的行走控制
- 9微信开发者工具开通云开发流程_开通微信云开发
- 10鸿蒙HarmonyOS系统应用开发|接口描述语言构成_harmony定义java数组
当前位置: article > 正文
基于Pytorch的面向对象的深度学习项目编码规范_深度学习编码规范
作者:小小林熬夜学编程 | 2024-03-31 17:28:41
赞
踩
深度学习编码规范
参考:
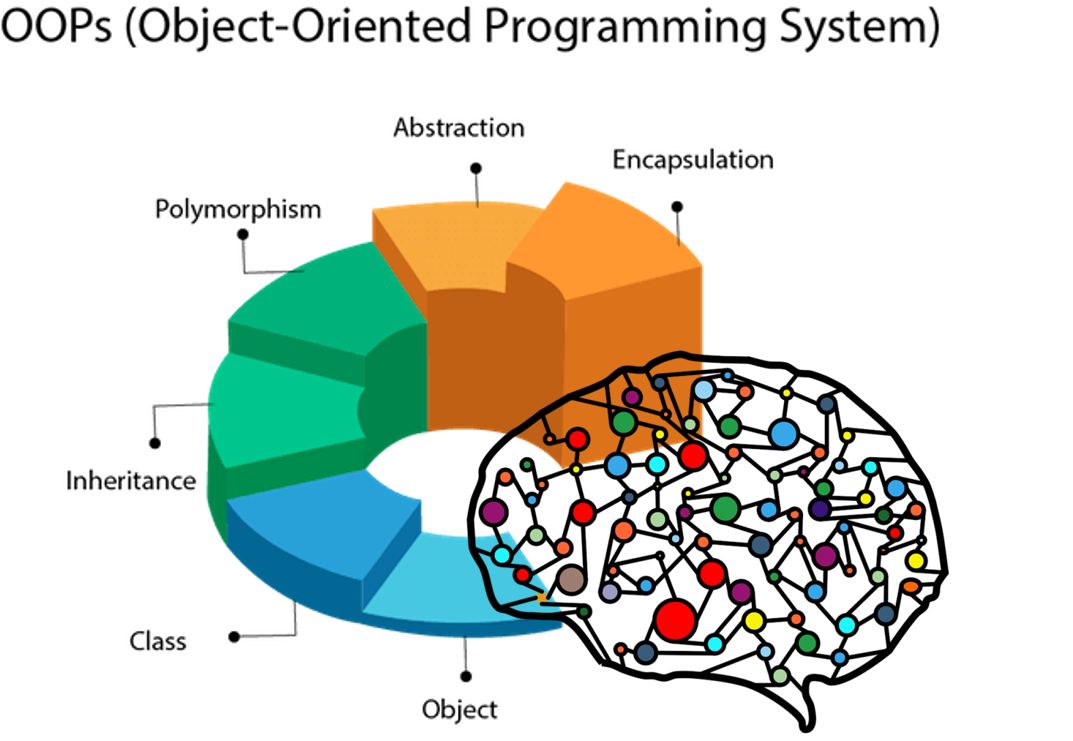
(1/4)首先明确一个思考方式:
一切皆是对象一切我的理解是包括两类
- 对象
- 非对象
(2/4)为什么要有对象?
对象不用说了,就是一些名词,比如:模型,算法,数据(训练集,测试集),设备,等。
非对象肯定是包括过程的,过程怎么变为对象呢?或者说,“过程怎么被赋予对象的一些属性呢?”
如何赋予过程一些东西,这些东西使过程看起来像是对象,那么就要分析以下正常的对象有哪些属性,或者说是特点。
在创建一个对象时,首先要有他所属的类,类相当于一个命名空间,对象在此基础上扩展,类可以有自己的属性,这些属性是每个对象(由此类生出)共有的。类里面定义一些方法,类和对象都可以访问。这两种东西(类属性,类方法)都是属于类的,如果面向对象的设计就到这里,那么这个“类”和普通方法没什么区别,因为这个“类‘的对象(即使能够被创建)不具有扩展性。我认为的扩展性就是对象的方法和属性可以在对象诞生后增删改。既然可以通过对象增删改,那么就必须通过对象,但是在创建类的时候,对象还没有出生啊!!,怎么办呢?就要定义一个代指未来对象的东西,python中是self关键字,java中是this关键字。所以在定义类时,只要是希望仅仅属于对象的东西(属性)那么就要加上这种代指对象的关键字。
(3/4)那么过程该怎么对象化呢?
一个过程应该有明确步骤,而每一步需要操作的东西就是该过程对应类的某些属性。
(4/4)深度学习过程编程实现的面向对象
对象
- 模型
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.fc = nn.Linear(784, 10)
-
- def forward(self, x):
- return self.fc(x.view(x.size(0), -1))
- 优化算法
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)- 数据加载
- class MNISTDataLoader(data.DataLoader):
-
- def __init__(self, root, batch_size, train=True):
- transform = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.1307,), (0.3081,)),
- ])
-
- dataset = datasets.MNIST(root, train=train, transform=transform, download=True)
- sampler = None
- if train and distributed_is_initialized():
- sampler = data.DistributedSampler(dataset)
-
- super(MNISTDataLoader, self).__init__(
- dataset,
- batch_size=batch_size,
- shuffle=(sampler is None),
- sampler=sampler,
- )

- 设备
device = torch.device('cuda' if torch.cuda.is_available() and not args.no_cuda else 'cpu')- 错误率
- class Average(object):
-
- def __init__(self):
- self.sum = 0
- self.count = 0
-
- def __str__(self):
- return '{:.6f}'.format(self.average)
-
- @property
- def average(self):
- return self.sum / self.count
-
- def update(self, value, number):
- self.sum += value * number
- self.count += number
- 准确率
- class Accuracy(object):
-
- def __init__(self):
- self.correct = 0
- self.count = 0
-
- def __str__(self):
- return '{:.2f}%'.format(self.accuracy * 100)
-
- @property
- def accuracy(self):
- return self.correct / self.count
-
- def update(self, output, target):
- with torch.no_grad():
- pred = output.argmax(dim=1)
-
- self.correct += correct
- self.count += output.size(0)
过程
- 训练和测试
- class Trainer(object):
-
- def __init__(self, model, optimizer, train_loader, test_loader, device):
- self.model = model
- self.optimizer = optimizer
- self.train_loader = train_loader
- self.test_loader = test_loader
- self.device = device
-
- def fit(self, epochs):
- for epoch in range(1, epochs + 1):
- train_loss, train_acc = self.train()
- test_loss, test_acc = self.evaluate()
-
- print(
- 'Epoch: {}/{},'.format(epoch, epochs),
- 'train loss: {}, train acc: {},'.format(train_loss, train_acc),
- 'test loss: {}, test acc: {}.'.format(test_loss, test_acc),
- )
-
- def train(self):
- self.model.train()
-
- train_loss = Average()
- train_acc = Accuracy()
-
- for data, target in self.train_loader:
- data = data.to(self.device)
- target = target.to(self.device)
-
- output = self.model(data)
- loss = F.cross_entropy(output, target)
-
- self.optimizer.zero_grad()
- loss.backward()
- self.optimizer.step()
-
- train_loss.update(loss.item(), data.size(0))
- train_acc.update(output, target)
-
- return train_loss, train_acc
-
- def evaluate(self):
- self.model.eval()
-
- test_loss = Average()
- test_acc = Accuracy()
-
- with torch.no_grad():
- for data, target in self.test_loader:
- data = data.to(self.device)
- target = target.to(self.device)
-
- output = self.model(data)
- loss = F.cross_entropy(output, target)
-
- test_loss.update(loss.item(), data.size(0))
- test_acc.update(output, target)
-
- return test_loss, test_acc
- 运行
- def run(args):
- device = torch.device('cuda' if torch.cuda.is_available() and not args.no_cuda else 'cpu')
-
- model = Net()
- if distributed_is_initialized():
- model.to(device)
- model = nn.parallel.DistributedDataParallel(model)
- else:
- model = nn.DataParallel(model)
- model.to(device)
-
- optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
-
- train_loader = MNISTDataLoader(args.root, args.batch_size, train=True)
- test_loader = MNISTDataLoader(args.root, args.batch_size, train=False)
-
- trainer = Trainer(model, optimizer, train_loader, test_loader, device)
- trainer.fit(args.epochs)
主函数
- def main():
- parser = argparse.ArgumentParser()
- parser.add_argument('--backend', type=str, default='gloo', help='Name of the backend to use.')
- parser.add_argument(
- '-i',
- '--init-method',
- type=str,
- default='tcp://127.0.0.1:23456',
- help='URL specifying how to initialize the package.')
- parser.add_argument('-s', '--world-size', type=int, default=1, help='Number of processes participating in the job.')
- parser.add_argument('-r', '--rank', type=int, default=0, help='Rank of the current process.')
- parser.add_argument('--epochs', type=int, default=20)
- parser.add_argument('--no-cuda', action='store_true')
- parser.add_argument('-lr', '--learning-rate', type=float, default=1e-3)
- parser.add_argument('--root', type=str, default='data')
- parser.add_argument('--batch-size', type=int, default=128)
- args = parser.parse_args()
- print(args)
-
- if args.world_size > 1:
- distributed.init_process_group(
- backend=args.backend,
- init_method=args.init_method,
- world_size=args.world_size,
- rank=args.rank,
- )
-
- run(args)
-
-
- if __name__ == '__main__':
- main()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/345402
推荐阅读
相关标签

