
- 1canvas画半透明圆delphi_当面向对象遇到Canvas
- 2vue项目axios的封装和使用_vue使用axios封装
- 3【配置管理】Mac OS X 安装及配置 Gradle_mac在 gradle 目录下的 init.d 目录中创建名为 init.gradle 文件:
- 4推荐几款代码AI助手_通义灵码和fitten code
- 5JS文件默认编码方式及修改_js 保存编码怎么修改
- 6.NET DataTable扩展之快速处理DataTable映射到List数组_datatable数据放list数组
- 7ChatGPT专业应用:纯英文视频-中英文快速字幕添加_英文视频生成字幕
- 8如何在Linux部署FastDFS文件服务并实现无公网IP远程访问内网文件——“cpolar内网穿透”
- 9php合并播放mp4文件_如何将百度的流畅版视频m3u8合并为正确的mp4文件?
- 10MYSQL知识点总结大全
浅淡ConvMixer (Pytorch and Keras)
赞
踩
前言
卷积神经网络已经占据计算机视觉任务多年。近几年来,基于Transformer结构的模型(例如ViT(Vision Transformer))在很多场景中的性能已经超过了之前的卷积网络。
因为ViTs系列的模型需要将图片分成一个个的patch,再将patch 展平,输入到网络去寻找特征。下面是动画演示:
Conv Mixer 这篇文章提出的初衷是想去弄清楚,ViT系列模型表现优越,到底是图片分块的功劳 还是网络中Attention的功劳。于是作者就根据深度可分离卷积,在ViT 和 MLP Mixer 的启发中 设计了Conv Mixer。并且在表现上超越了一些ViT (某些ViT结构),MLP Mixer 和 ResNet。文章本身并没去追求模型的速度,和表现能力。
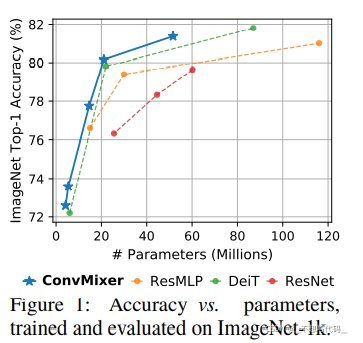
官方链接:
论文地址:https://openreview.net/pdf?id=TVHS5Y4dNvM
Github 地址:https://github.com/tmp-iclr/convmixer
官方给的代码有点难懂,所以这里我给它重构了一下。看起来通俗易懂
GitHub 地址(只含tf torch 模型代码):https://github.com/jiantenggei/ConvMixer
新版仓库(仅torch 可训练,eval top1 and top5):https://github.com/jiantenggei/torch-classification
一、什么是ConvMixer?
ConvMixer,取名上是根据MLP Mixer 来取名 。在思想上 与 ViT 和 MLP Mixer 一致,都是把,通过卷积映射成一个一个的特征块 输入到网络中。网络也不会通过下采样( 池化) 来改变输出的维度。整个网络结构通过传统的卷积来实现。
如下图所示:

表面上Vit 和MLP-Mixer 不包含卷积,但大多数实现方式在 embedding时,都会采用卷积。
c代表原图片的通道,h代表hidden_dim 也就是隐藏层维度,n表示原图像的长宽,p代表patch_size。
1.网络结构图:

这就是ConvMixer的网络结构图,结构很简单。在ConvMixer Layer 中, 使用了深度可分离卷积,GELU 激活函数,逐点卷积。
论文中将图中红色部 称为 “channel wise mixing” 蓝色部分称为 "spatial mixing"
论文得到的结论是当深度可分离卷积部分的卷积核越大,模型的性能越好。
文章最后也认为,ViT 表现如此优越 是因为patch embedding (图片分块)的原因。
作者认为 patch embedding 操作就能完成神经网络的所有下采样过程,降低了图片的分辨率,增加了感受野,更容易找到远处的空间信息。从而模型表现良好
二、实现步骤
1.Pytorch实现
首先我们来定义 ConvMixer Layer 结构,代码如下所示:
class ConvMixerLayer(nn.Module):
def __init__(self,dim,kernel_size = 9):
super().__init__()
#残差结构
self.Resnet = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding='same'),
nn.GELU(),
nn.BatchNorm2d(dim)
)
#逐点卷积
self.Conv_1x1 = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

