
- 1支付宝小程序的开通流程_支付宝 小程序 教程
- 2Docker常见命令(以备不时之需)_docker 命令
- 3Android网络收集和ping封装库(1)_android ping
- 4Perl基础教程: 正则表达式_use not allowed in expression at
- 5基于GNURadio的USRP开发教程(2):深入认识USRP设备_usrp2954r
- 6字节跳动简历冷却期_【字节跳动招聘】简历这样写,才不会被秒拒
- 7Mybatis使用foreach标签实现批量插入_mybatis foreach批量insert
- 8轻松获奖五一数学建模和蓝桥杯_五一建模三等奖好得吗
- 9交易积累-量化交易
- 10Leetcode 238. 除自身以外数组的乘积
文本生成图像|DALLE2论文记录_dalle论文
赞
踩
Hierarchical Text-Conditional Image Generation with CLIP Latents
Abstract
-
Clip模型:是Contrastive model的一种,可以很鲁棒地捕获语义和风格
-
本文提出一个2-stage model:一个prior模型,给出文字,生成一个CLIP图像特征;一个decoder根据图像特征生成图像
Introduction
-
CLIP
-
diffusion
-
our work:首先训练了一个diffusion decoder来反转CLIP图像encoder,这个反转器是non-deterministic的,对于一个给定的图像特征可以生成多个图片
-
相比起GAN,CLIP很大的一个优势是能够通过语音信息对图像进行修改
-
整体示意图
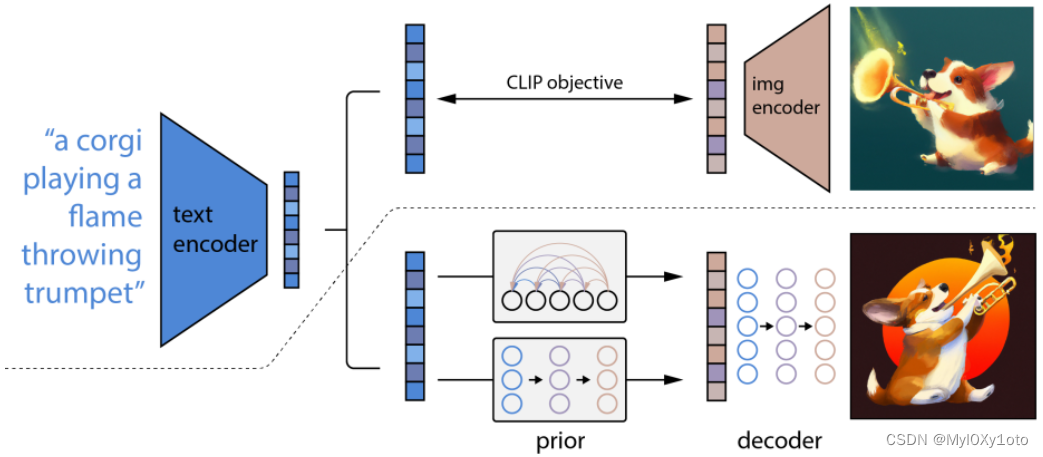
-
先用CLIP训练好文本和图像的联合表示空间,给定文本和文本的图像,出文本特征和图像特征,训练好之后它就frozen了不动了
-
再用clip处理出来的text特征进入prior模型生成img特征,再用diffussion decoder得到最终的图像
-
Method
-
对于image x,对应的text为y,CLIP生成的image embedding为 z i z_i zi,生成的text embedding为 z t z_t zt,
-
p r i o r P ( z i ∣ y ) prior\ \ P(z_i|y) prior P(zi∣y):能够利用text y生成CLIP image embeddings z i z_i zi
-
d e c o d e r P ( x ∣ z i , y ) decoder\ \ P(x|z_i,y) decoder P(x∣zi,y):能够根据 z i z_i zi(和
某些时刻可能用到text y)生成图像x -
于是整体流程be like:
P ( x ∣ y ) = ① P ( x , z i ∣ y ) = ② P ( x ∣ z i , y ) P ( z i ∣ y ) P(x|y)\mathop{=}\limits^① P(x,z_i|y)\mathop{=}\limits^②P(x|z_i,y)P(z_i|y) P(x∣y)
-

