
热门标签
热门文章
- 1google最新大语言模型gemma本地化部署_gemma 要求,看这里_gamma本地部署
- 2文心一言赋能问卷生成,打造高效问卷调研工具_csdn 文心一言出题
- 3动态内存管理——C语言【进阶】(下)
- 4解决方案:sql里的join跟left join有什么区别_sql中 join和left join的区别
- 5python面试总结(二)_python数据实习生二面
- 6MySQL数据库——DQL操作——基本查询_dql查询操作
- 7NLP扎实基础2:Word2vec模型CBOW Pytorch复现_pytorch 实现word2vec 连续词袋模型cbow
- 8从了解到掌握 Spark 计算框架(一)Spark 简介与基础概念_spark的哪个组件提供了内存计算框架
- 9Kafka消息队列_kafka实现点对点
- 10Flink作业执行之 4.JobGraph_jobgraph flink
当前位置: article > 正文
MySQL条件查询 SELECT的执行顺序(DQL语句)_mysql select from where
作者:小丑西瓜9 | 2024-06-11 01:31:16
赞
踩
mysql select from where
运算符
比较运算符
| 比较运算符 | 描述 |
|---|---|
| >、<、<=、>=、=、<>、!= | <>在 SQL 中表示不等于,SQL中没有== |
| BETWEEN … AND … | 在一个范围之内,包头又包尾,最小的需要在前面,如:between 100 and 200 |
| IN(…) | 在in之后的列表中的值,多选一,使用逗号分隔 |
| LIKE ‘匹配字符’ | 模糊匹配 ( _ 匹配单个字符,% 匹配任意个字符) |
| IS NULL | 查询某一列为 NULL 的值,注:不能写=NULL |
| IS NOT NULL | 不为空 |
| REGEXP | 正则表达式 |
逻辑运算符
| 逻辑运算符 | 描述 |
|---|---|
and && | 与 |
or 丨丨 | 或 |
not ! | 非 |
| XOR | 异或 |
按位运算符
| 运算符 | 描述 |
|---|---|
| & | 位与关系 |
| 丨 | 位或关系 |
| ~ | 位取反 |
| ^ | 位异或 |
| << | 左移 |
| >> | 右移 |
WHERE语句
执行顺序:FROM → WHERE → SELECT → ORDER BY → LIMIT
select 字段名 from 表名 where 条件:条件查询,取出表中的每条数据,满足条件的记录就返回,不满足条件的不返回select 字段名 from 表名 where 字段 in (数据 1, 数据 2...):in 里面的每个数据都会作为一次条件,只要满足条件的就会显示select 字段名 from 表名 where 字段名 between 值1 and 值2:范围查询 表示从值1到值2范围,包头又包尾select 字段名 from 表名 where 字段名 like '通配符字符串':模糊查询,通配符 %,例如:‘%老王%’
WHERE子句中,条件执行的顺序是从左到右的。所以应该把索引条件,或者筛选掉记录最多的条件写在最左侧。
-- 查询 math 分数大于 80 分的学生 select * from student3 where math > 80; -- 查询 id 是 1 或 3 或 5 的学生 select * from student3 where id in(1, 3, 5); -- 查询 id 不是 1 或 3 或 5 的学生 select * from student3 where id not in(1, 3, 5); -- 查询 english 成绩大于等于 75,且小于等于 90 的学生 select * from student3 where english between 75 and 90; -- 查询 age 大于 35 且性别为男的学生(两个条件同时满足) select * from student3 where age > 35 and sex='男'; -- 查询 age 大于 35 或性别为男的学生(两个条件其中一个满足) select * from student3 where age > 35 or sex = '男'; -- 查询姓马的学生 select * from student3 where name like '马%'; -- 查询姓名中包含'德'字的学生 select * from student3 where name like '%德%'; -- 查询姓马,且姓名有两个字的学生 select * from student3 where name like '马_'; -- 查询t_emp表中,工资和佣金不在2000-3000之间的人 select * from t_emp where not sal + ifnull(comm, 0) in (2000, 3000);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
聚合函数
聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。
- 聚合函数会忽略空值 NULL。
- 聚合函数不能出现在where子句中。
select 聚合函数(列名) from 表名:聚合函数的使用
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值,非数字类型结果为0 |
| count(*),count(列名) | 统计这一列有多少条记录,第一个用于获得包含空值的记录数,第二个用于获得包含非空值的记录数 |
| sum(列名) | 对这一列求总和,只能用于数字类型,字符类型返回0,日期类型是毫秒数相加 |
-- 查询学生总数 select count(id) as 总人数 from student; select count(*) as 总人数 from student; -- 聚合函数对于 NULL 的记录不会统计的,如果统计个数则不要使用有可能为 null 的列。 -- 查询 id 字段,如果为 null,则使用 0 代替 select count(ifnull(id,0)) from student; -- 查询年龄大于 20 的总数 select count(*) from student where age>20; -- 查询数学成绩总分 select sum(math) 总分 from student; -- 查询数学成绩平均分 select avg(math) 平均分 from student; -- 查询数学成绩最高分 select max(math) 最高分 from student; -- 查询数学成绩最低分 select min(math) 最低分 from student;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
分组
分组查询是指使用GROUP BY语句对查询信息进行分组,相同数据作为一组。
执行顺序:FROM → WHERE → GROUP BY → SELECT → ORDER BY → LIMIT
select 字段 1,字段 2... from 表名 group by 分组字段 [having 条件]:将分组字段结果中相同内容作为一组。select 字段1, 字段2, ... from 表名 group by 1 having 条件:用聚合函数和普通条件数据做判断时使用,平时没用with rollup:对汇总后的数据再次汇总计算having 条件:先在group by子句中分组后再做筛选
GROUP BY 将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
查询语句中如果含有group by子句,select子句中可以包括聚合函数或group by子句分组用的列,其余内容不可以出现在select子句中。
-- 按性别进行分组,求男生和女生数学的平均分
select sex, avg(math) from student3 group by sex;
-- 当我们使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪组的。
-- 对分组查询的结果再进行过滤
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex having COUNT(*) >2;
-- 多分组字段,先按deptno分组,然后按job分组
select deptno, job, count(*), avg(sal) from t_emp group by deptno, job;
-- 对分组结果集再次做汇总计算
select deptno, avg(sal), sum(sal), max(sal), min(sal) from t_emp group by deptno with rollup;
-- 查询每个部门中,1982年以后入职的员工并且超过2人的部门编号
select deptno from t_emp where hiredate>="1982-01-01" group by deptno having count(deptno) > 2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
对分组结果集再次做汇总计算的结果:
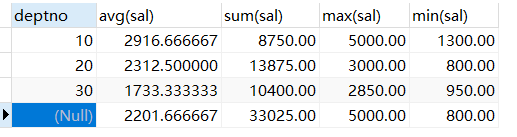
having 与 where 的区别
where 子句
- 对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤再分组。
- where 后面不可以使用聚合函数
having 子句
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。
- having 后面可以使用聚合函数
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/701145
推荐阅读
相关标签

