
- 13.1、决策树算法_决策树算法连续变量坐标 (1.4) (1.6) (3.1) (3.8 (6.6) (7.2) (7.
- 2代码随想录笔记|C++数据结构与算法学习笔记-二叉树(二)|二叉树层序遍历、226.翻转二叉树
- 3ubuntu16.04使用全记录_bantu更新软件
- 4华三 h3c STP生成树保护配置_stp loop-protection
- 5rk3399 android7.1.2 edp屏幕调试_panel-simple.c
- 6PWA 入门指南:理解与构建现代化 Web 应用
- 7如何白嫖最新版BurpSuite Pro_burpsuite professional免费激活
- 8lighting 光照简介(个人笔记)_indirect multiplier
- 9Shell之Sed命令-yellowcong_sed -i命令详解
- 10阿里云原生:如何熟悉一个系统
NLP-词向量(Word Embedding)-2014:Glove【基于“词共现矩阵”的非0元素上的训练得到词向量】【Glove官网提供预训练词向量】【无法解决一词多义】_创建同义词向量
赞
踩
一、对比模型的缺点
1、矩阵分解方法(Matrix Factorization Methods)
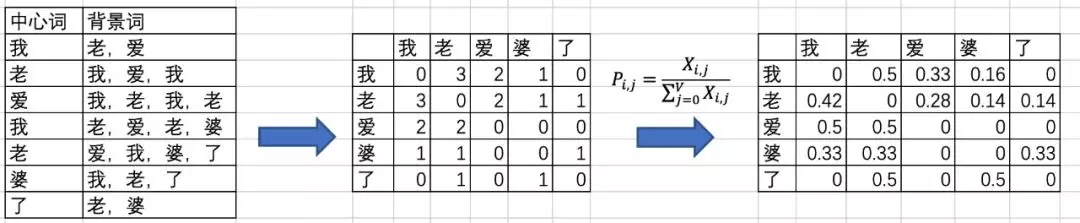
- 在统计语言模型中,有一种假设,认为词的语义是由它的上下文所决定的,所以统计当前词的上下文的分布也是一种方式,即统计与当前词共现的词的分布情况。这样建立出来的矩阵的size就是 N × N N×N N×N。 横坐标是每一个词,纵坐标也每一个词,矩阵中每一个点的(word1, word2)的value是指 word2是word1的上下文中出现的次数。
- 词共现矩阵
- I enjoy flying。
- I like NLP。
- I like deep learning。

- 由于共现矩阵保存了词的上下文信息,所以就保存了语义,效果会比之前的好很多。但这种矩阵大小也存在太大的问题,一般的办法是用矩阵分解的方式进行降维。
- 缺点:在词对推理任务上表现特别差;可解释性差;
2、Word2Vec

Word2Vec缺点:无法使用全局的统计信息
二、Glove
Glove是一种无监督的Word representation方法。
- 模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息。
- 输入:语料库
- 输出:词向量
- 方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
开始 -> 统计共现矩阵 -> 训练词向量 -> 结束
Count-based模型,如GloVe,本质上是对共现矩阵进行降维。
- 首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。
- 共现矩阵就是计算每个word在每个context出现的频率。
- 由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。
- 这一过程可以视为共现矩阵的重构问题,即reconstruction loss。
- 降维或者重构的本质是什么?我们选择留下某个维度和丢掉某个维度的标准是什么?Find the lower-dimensional representations which can explain most of the variance in the high-dimensional data,这其实也是PCA的原理。
Glove优点:充分有效的利用了语料库的统计信息,仅仅利用共现矩阵里面的非0元素进行训练,而skip-gram没有很有效的利用语料库中的一些统计信息。
1、研究成果
在词对推理数据集上取得了更好的结果
公布了一系列基于GloVe的预训练词向量(https://nlp.stanford.edu/projects/glove/):一般用 glove.840B.300d.zip

glove下载 http://downloads.cs.stanford.edu/nlp/data/glove.840B.300d.zip
国内地址:https://apache-mxnet.s3.cn-north-1.amazonaws.com.cn/gluon/embeddings/glove/glove.840B.300d.zip
2、研究意义
GloVe历史意义:推动了基于深度学习的自然语言处理的发展。提供了开源的预训练词向量,为后续模型的对比实验提供参考。

3、Glove模型原理
损失函数:






4、Glove论文的启发
-
相对于原始的概率,概率的比值更能够区分相关的词和不相关的词,并且能够区分两种相关的词。
Compared to the raw probabilities, the ratio is better able to distinguish relevant words (solid and gas) from irrelevant words (water and fashion) and it is also better able to discriminate between the two relevant words. (3 The GloVe Model P3) -
我们提出了一种新的对数双线性回归模型,这种模型结合全局矩阵分解和局部上下文的优点。
The result is a new global log-bilinear regression model that combines the advantages of the two major model families in the literature: global matrix factorization and local context window methods. (Abstract)
三、Glove与Word2vec的区别与联系
相同点:
- GloVe与word2vec,两个模型都可以根据词汇的“共现co-occurrence”信息,将词汇编码成一个向量(所谓共现,即语料中词汇一块出现的频率)。
不同点:
- 两者最直观的区别在于,word2vec是“predictive”的模型,而GloVe是“count-based”的模型。
- Predictive的模型,如Word2vec,根据context预测中间的词汇,要么根据中间的词汇预测context,分别对应了word2vec的两种训练方式cbow和skip-gram。
- Count-based模型,如GloVe,本质上是对共现矩阵进行降维。
首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。
- Word2Vec:其输出是单词同时出现的概率分布;GLove:相比单词同时出现的概率,单词同时出现的概率的比率能够更好地区分单词。
- Cbow/Skip-Gram 是一个local context window的方法,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重
- Global Vector融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
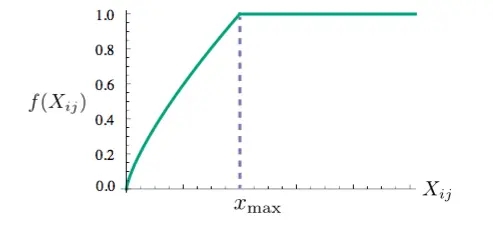
- 对于原生的w2v,其loss是交叉熵损失;对于Glove来说,其需要先构建一个共现矩阵X,其中的 Xij 表示 i 和 j共同出现的次数,其loss为如下的公式。
f(x) 是一个权重函数,当 X i j X_{ij} Xij 等于0的时候,f(x) = 0,并且当 X i j X_{ij} Xij 过大的时候,f(x) = 1。
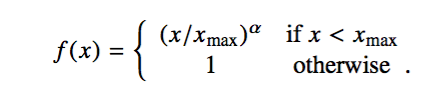
- Glove与Word2vec的performance上差别不大。

