
热门标签
热门文章
- 12024为什么前端都应该掌握Nextjs 或 Nuxtjs_would you like to customize the default
- 2RxJava版本不一致_failed to resolve: io.reactivex.rxjava2:rxjava:2.1
- 3Python selenium爬取影评生成词云图_电影影评生成
- 4第6篇-Mac电脑安装Nvm_mac nvm
- 5大数据毕设分享 大数据上海租房数据爬取与分析可视化 -python 数据分析 可视化_做毕业设计项目数据要爬多少条合适
- 6golang知识图谱NLP实战第二节——解析依存句法分析结果_句法依存知识图谱
- 7Allavsoft for Mac v3.27.0.8852注册激活版 优秀的视频下载工具
- 8云原生架构势不可挡,“可观测性”重塑IT运维核心竞争力
- 9Android入门:简单计算器的实现_android 计算器功能实现
- 10网页设计(五)DIV+CSS布局规划_div页面布局代码
当前位置: article > 正文
朴素贝叶斯的详解和文本分类python样例实现_python 朴素贝叶斯实现文本类型识别
作者:小丑西瓜9 | 2024-04-06 09:04:36
赞
踩
python 朴素贝叶斯实现文本类型识别
朴素贝叶斯的详解和文本分类python样例实现
算法详解
在了解朴素贝叶斯算法之前,不妨来看看贝叶斯公式:
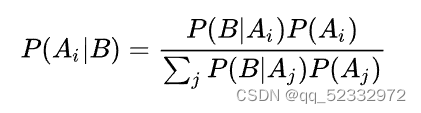
推导如下:
已知条件概率公式如下:
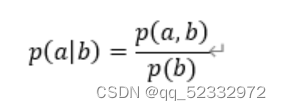
而p(a,b)=p(b,a) (此处为联合概率,即a,b同时发生的概率)
该公式转化如下:
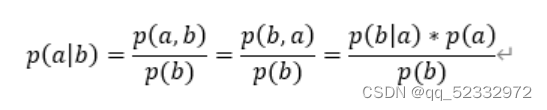
可以简单的理解为 b发生时a的概率(先验概率) 可以通过a发生时b的概率(后验概率)进行计算
那么在进行特征分类的过程中,我们大部分时候是输入各个特征的值 得到一个分类 。
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜? |
|---|---|---|---|---|---|---|---|---|---|
| 1 | |||||||||
| 2 | |||||||||
| 3 |
可以看到的是 对于每一个特征值 可能存在不同的 数量不定的具体特征,例如色泽可以包括 青绿 暗绿 各种绿 。 那么不同的特征值会对我们最后的结果(是不是好瓜)有所影响,而我们可以反过来通过好瓜发生时各个特征出现的概率,从而得到好瓜大部分时候具有什么特征(例如纹理明显,色泽暗绿),从而反过来计算当各个特征出现时,是不是好瓜的概率,即:

xi表示一个特征值,X表示这个样例的所有特征,y表示最后的结果的取值。
其中 朴素贝叶斯将各个特征看作是,互不干扰,独立的个体,因此我们单独计算概率。即:

文本分类的python代码实现
前面提到了朴素贝叶斯是基于特征进行分类的,那么对于文本,我们应该怎么将其转化为特征值是分类的正确率的关键,本次分类我采用是是布袋模型,具体如下:
布袋模型中有一种单独考虑某个单词是否在文本中出现的情况 ,若该单词出现,则对应位置的特征值应该是True,反之则为False。
#加载数据
from nltk import word_tokenize
from sklearn.naive_bayes import BernoulliNB
def getDataest(FILE_PATH):
data = open(FILE_PATH, 'r')
dataclasses = []
datatext = []
while 1:
dataline = data.readline()
if not dataline:
break
dataline = word_tokenize(dataline)
dataclasses.append(dataline[0])
datatext.append(dataline[1:-1])
return dataclasses, datatext
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
本文采用word_torkenize()进行分词,读者可以自行下载导入nlkt库文件
dataclasses, datatext = getDataest("SMSSpamCollection.txt") div = {} for i in datatext: for word in i: if word in div.keys(): div[word] += 1 else: div[word] = 1 for name in list(div.keys()): if div[name] < 100: div.pop(name) datafirgue = [[1 for col in range(len(div))] for row in range(len(datatext))] for i in range(len(datatext)): position = int(0) for word in div.keys(): if word in datatext[i]: datafirgue[i][position] = 2 position += 1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
分词之后,应当创建一个总的单词表,考虑到计算量太大的问题,本文只选择了在数据集中出现了100次以上的单词,多余的进行清除。
随后,应当通过单词表进行特征值的创建。考虑到防止出现某个特征值概率为0的出现,设置了初始量为1,存在则为2。
最后就是切割数据集,创建模型并训练
#切割数据集
train_feature=datafirgue[:int(0.8*len(datafirgue))]
train_lables=dataclasses[:int(0.8*len(datafirgue))]
test_feature=datafirgue[int(0.8*len(datafirgue)):]
test_labels=dataclasses[int(0.8*len(datafirgue)):]
#训练
clf = MultinomialNB(alpha=0.001).fit(train_feature, train_lables)
predicted_labels=clf.predict(test_feature)
print('准确率为:', metrics.accuracy_score(test_labels, predicted_labels))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
以上就是本文全部内容。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/370973
推荐阅读
相关标签

