
热门标签
热门文章
- 1拷贝vmware虚拟机造成的mac地址冲突的问题_静态以太网地址不允许使用:“00:0c:29:5b:9e:88”。它与 vmware 预留的 mac
- 2《高效能人的七个习惯》
- 3在Vue2里面加载AntvL7
- 4Build generative AI apps that can perform tasks with Amazon Bedrock
- 5开源代码2004/1220-PDF格式/文件相关
- 6Linux之环境变量_linux 环境变量
- 7基于昇腾CANN的卡通图像生成可在线体验啦!十分钟带你了解CANN应用开发全流程_基于升腾ai应用开发可能会涉及哪些流程
- 8QT中资源文件resourcefile的使用,使用API完成页面布局_qt resource file
- 9android 应用内页面,截屏监听_android app监听自己是否被截屏
- 10计算机组成原理(笔记)_计算机组成原理笔记
当前位置: article > 正文
信用卡反欺诈模型
作者:小丑西瓜9 | 2024-04-03 14:03:49
赞
踩
信用卡反欺诈模型
一、项目介绍
数据来源于kaggle平台(欧洲持卡人2天内的28万笔+信用卡交易),需通过信用卡历史交易数据进行机器学习,构建“信用卡反欺诈数据模型”,从而提前发现客户信用卡被盗刷的事件。
二、构建模型
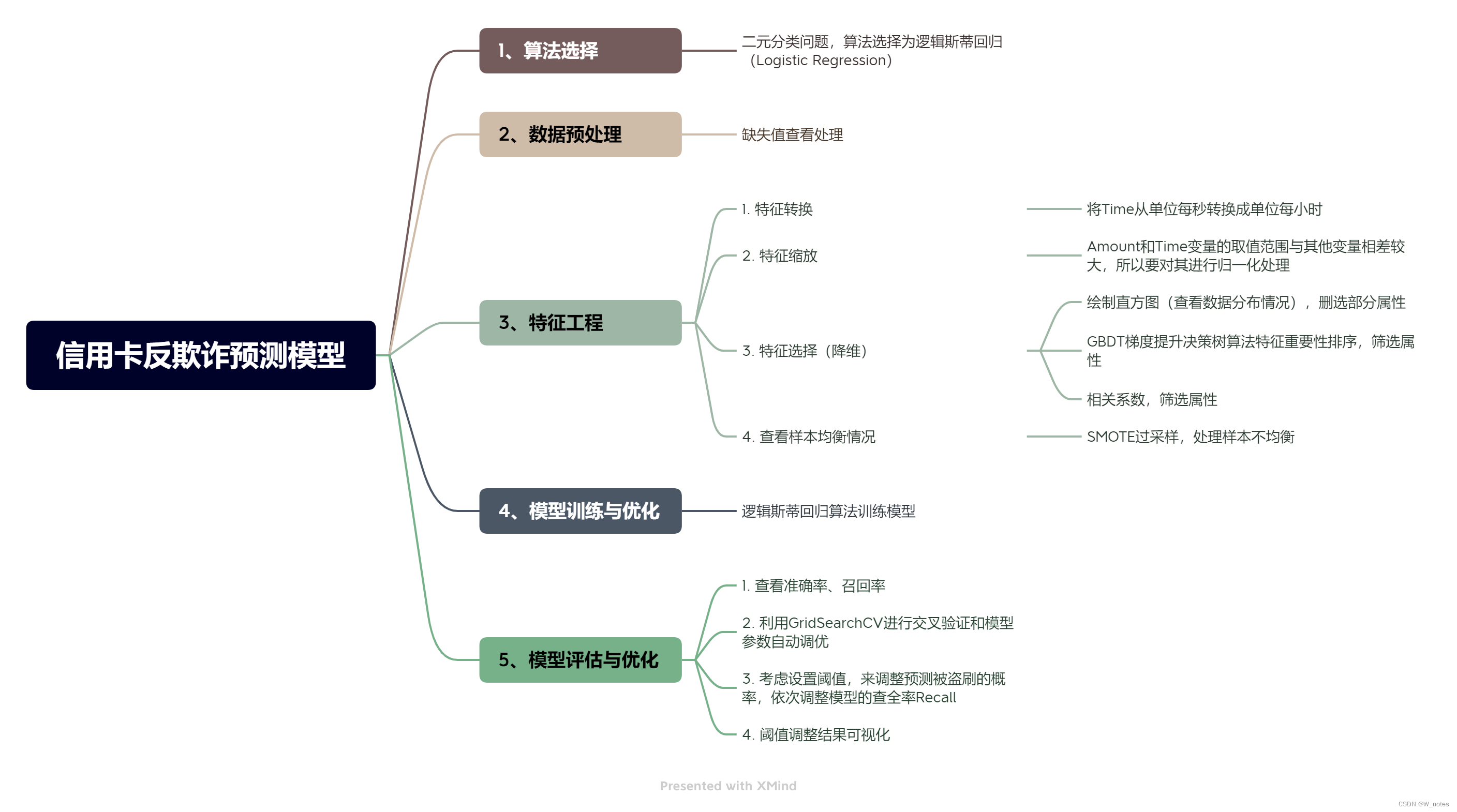
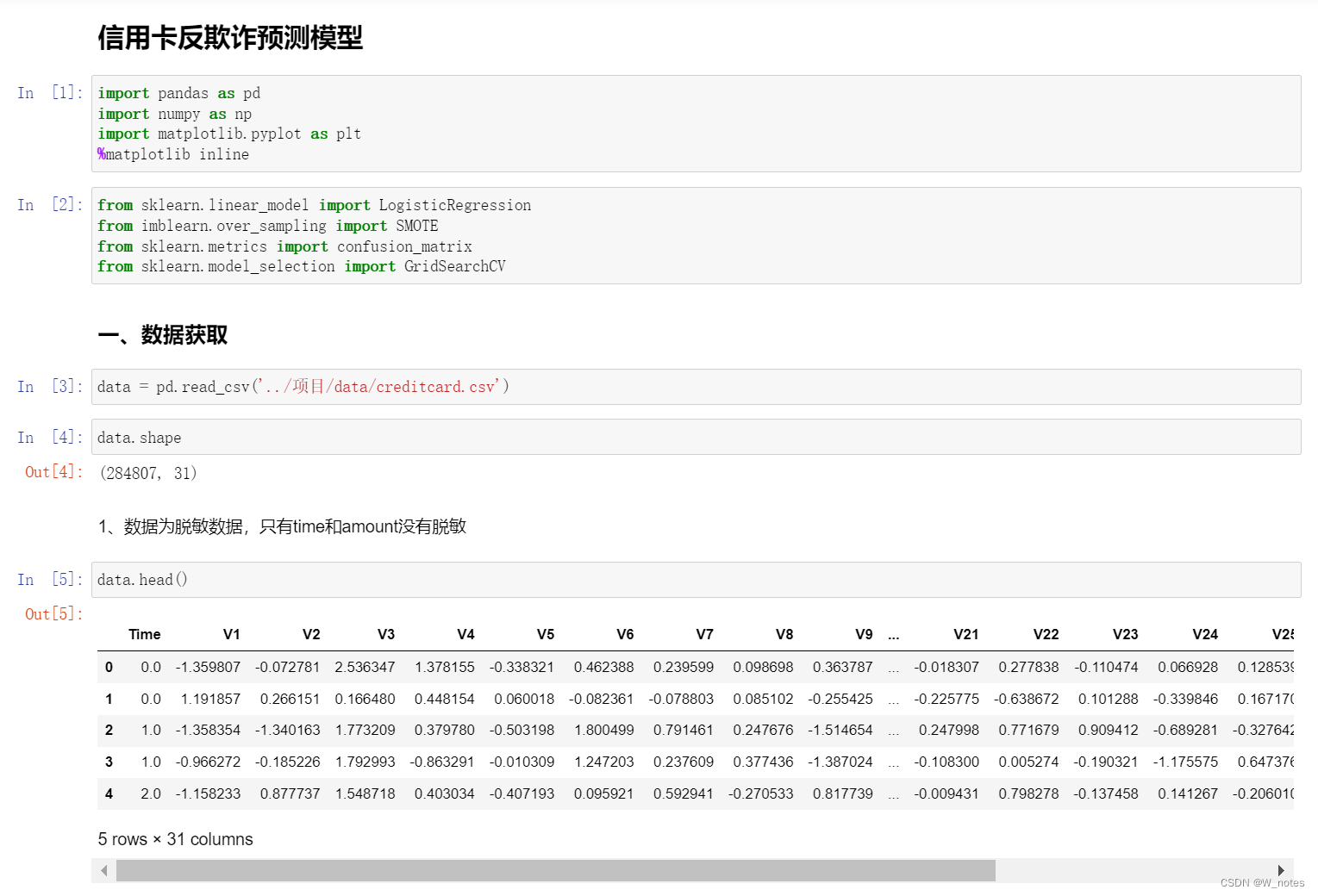
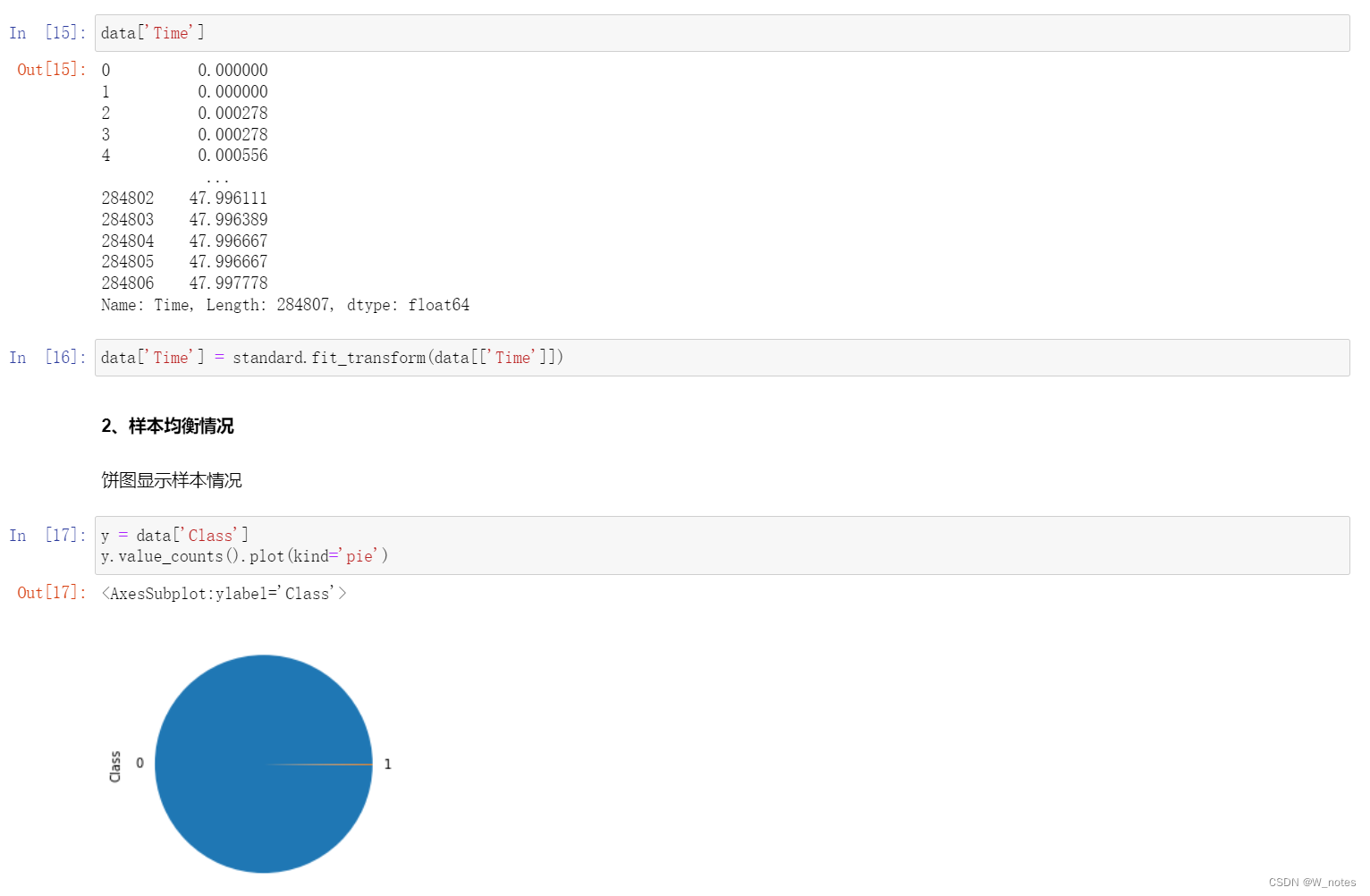
三、python代码
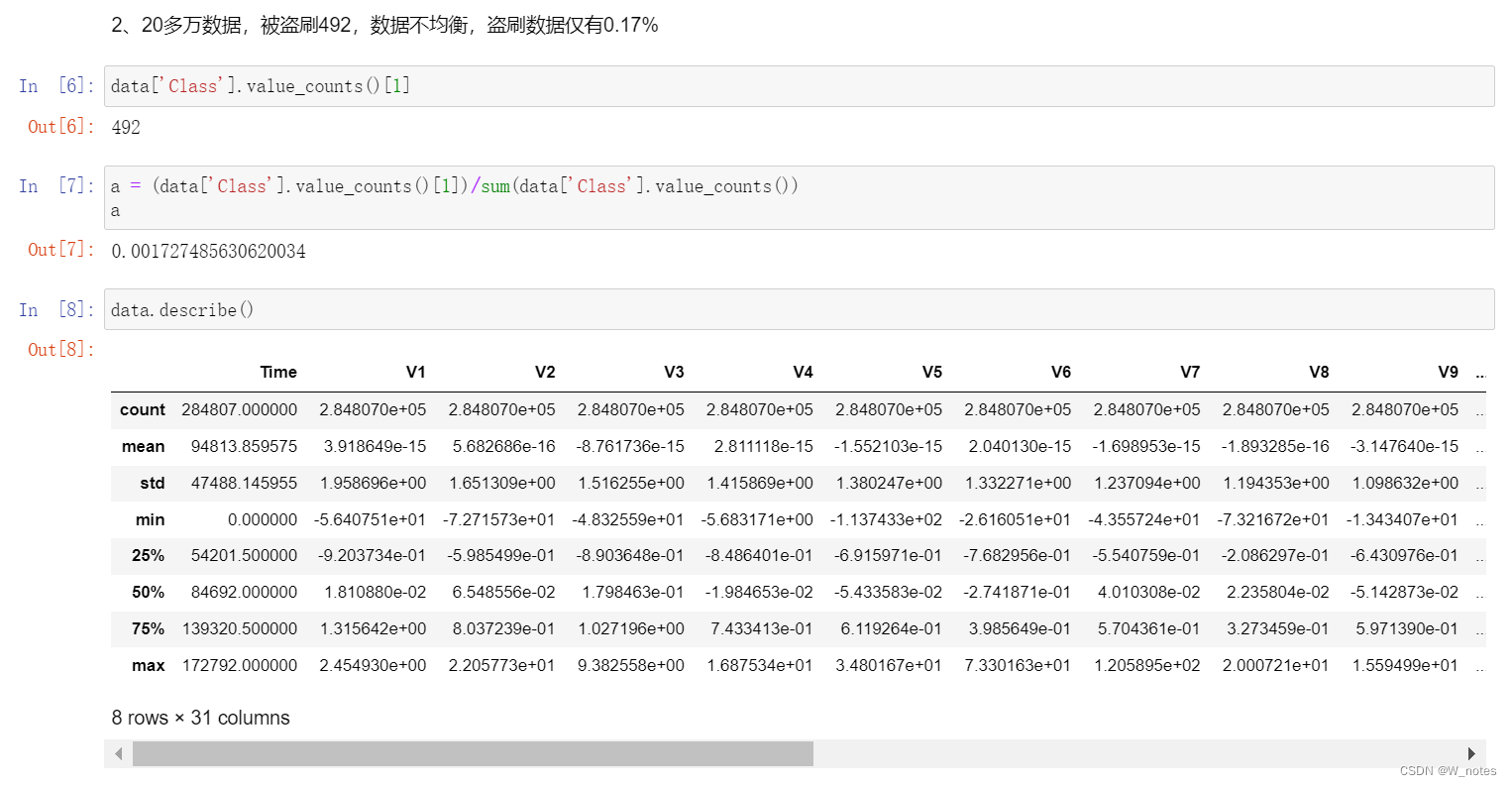
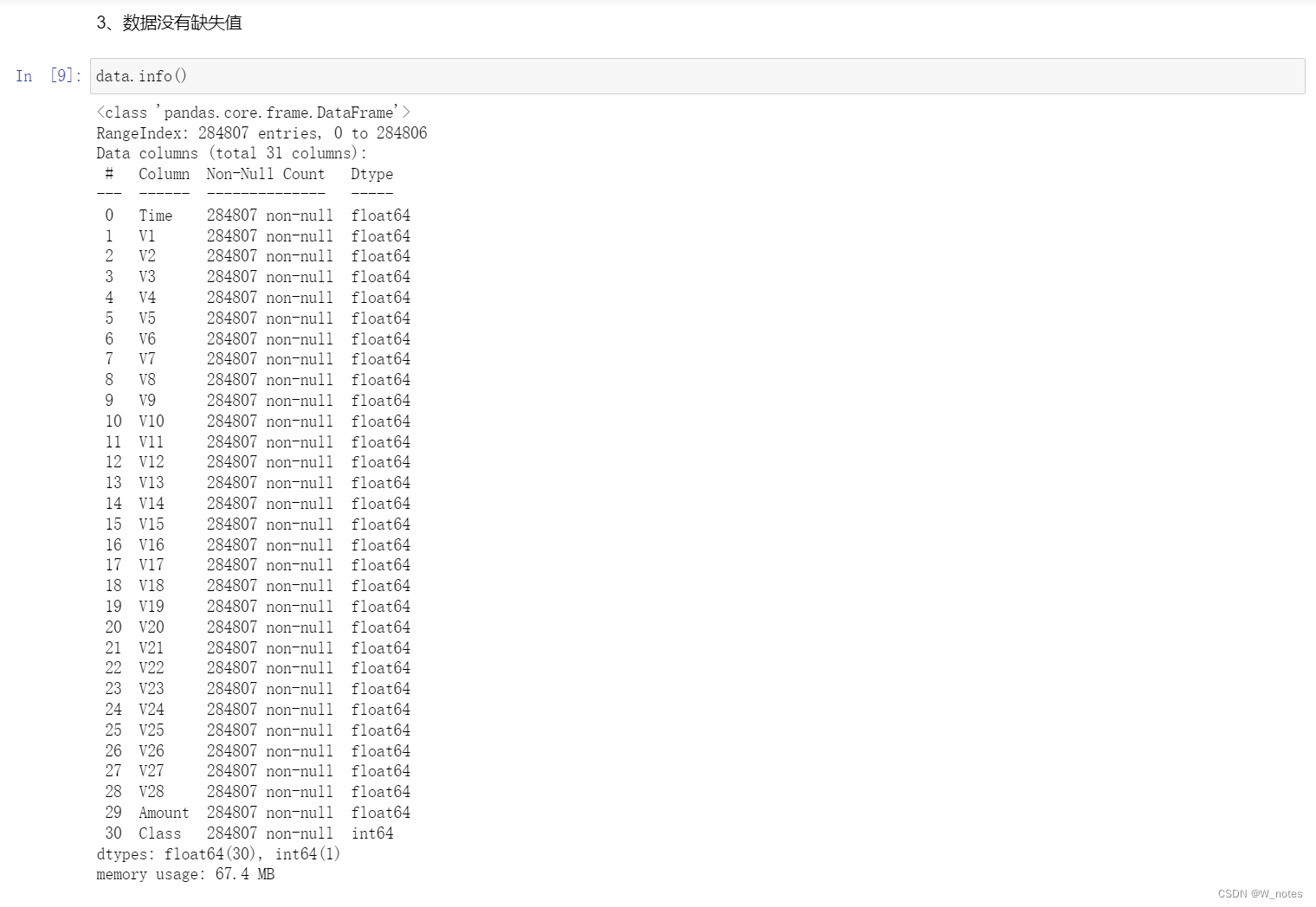




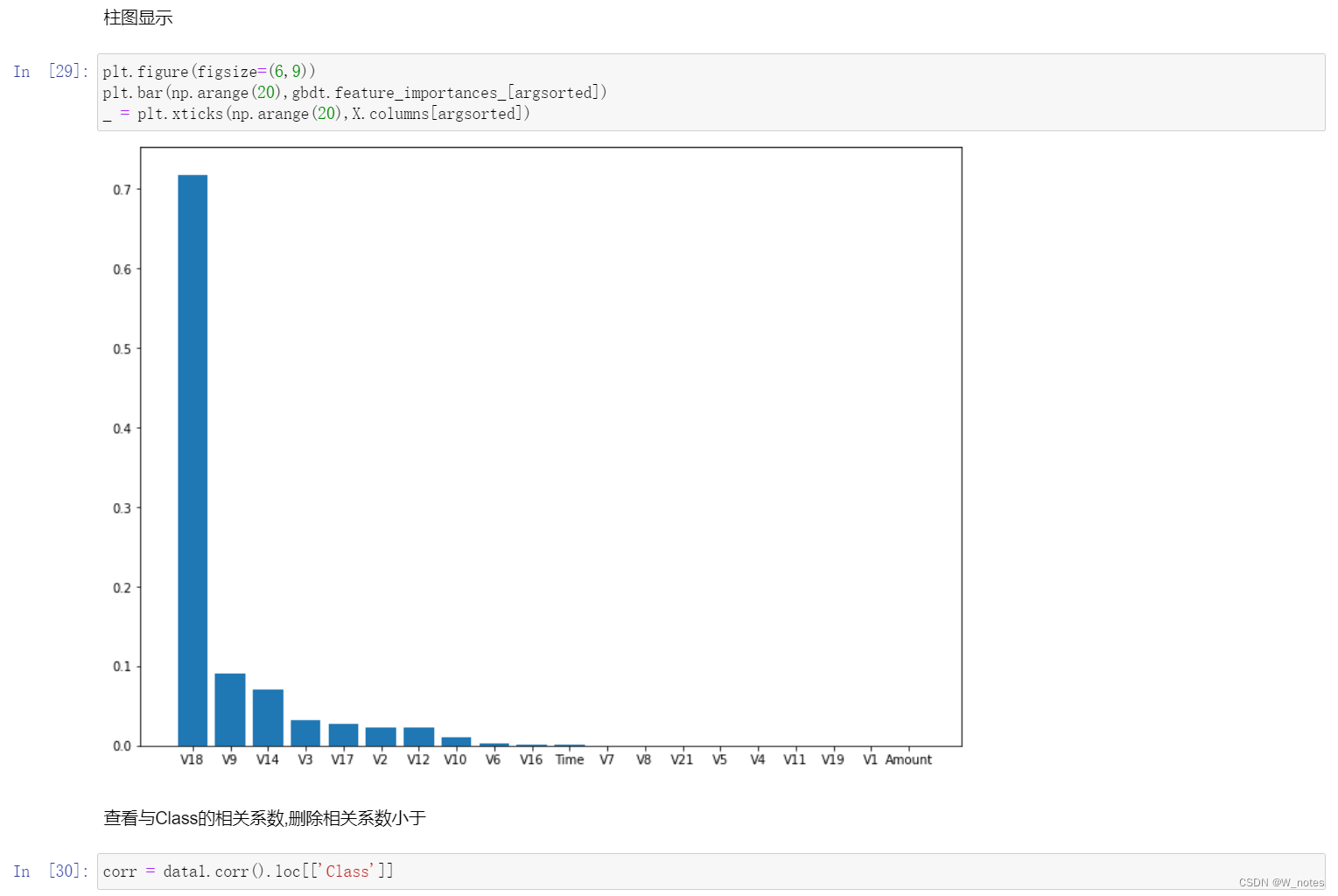
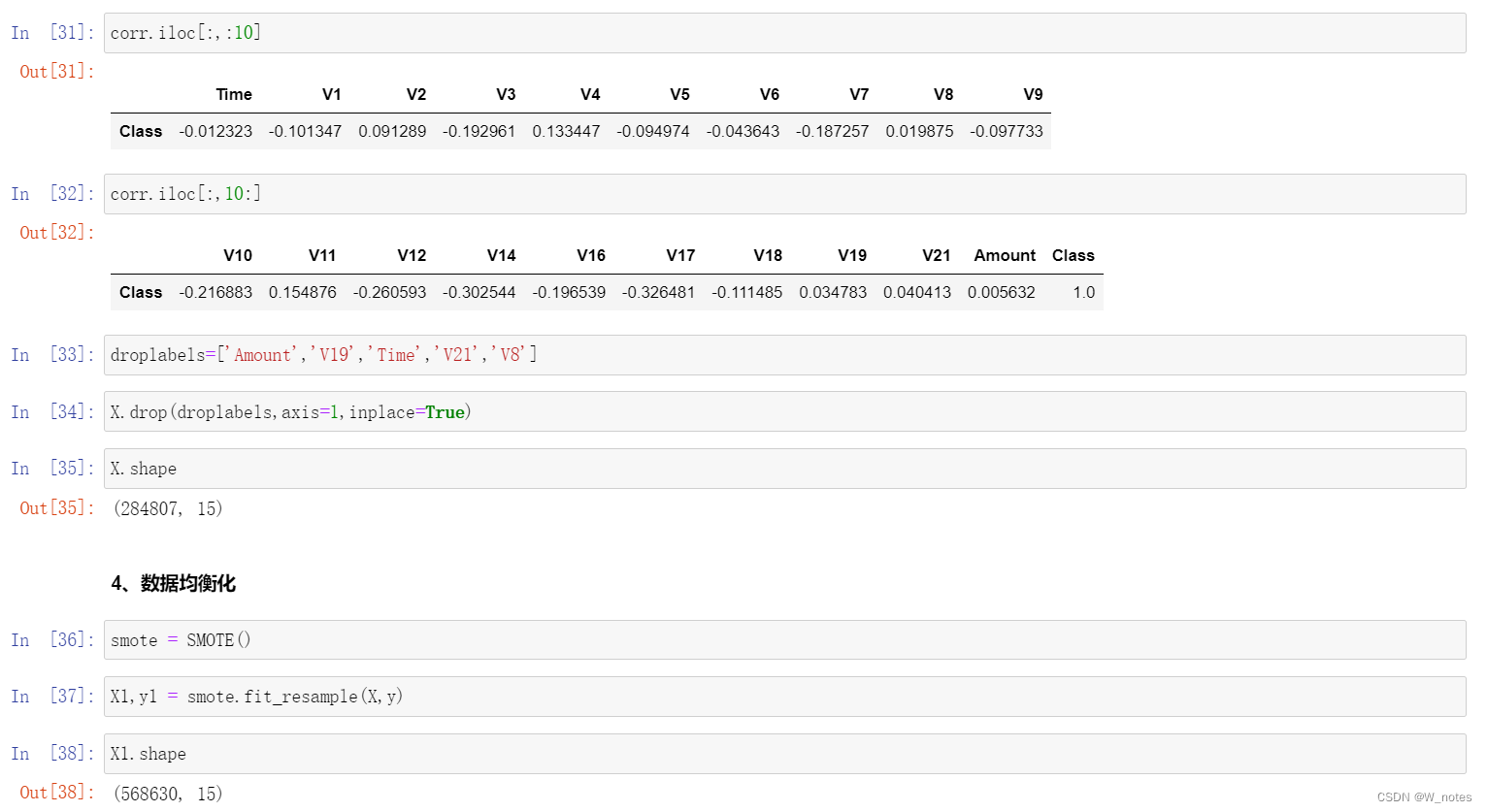

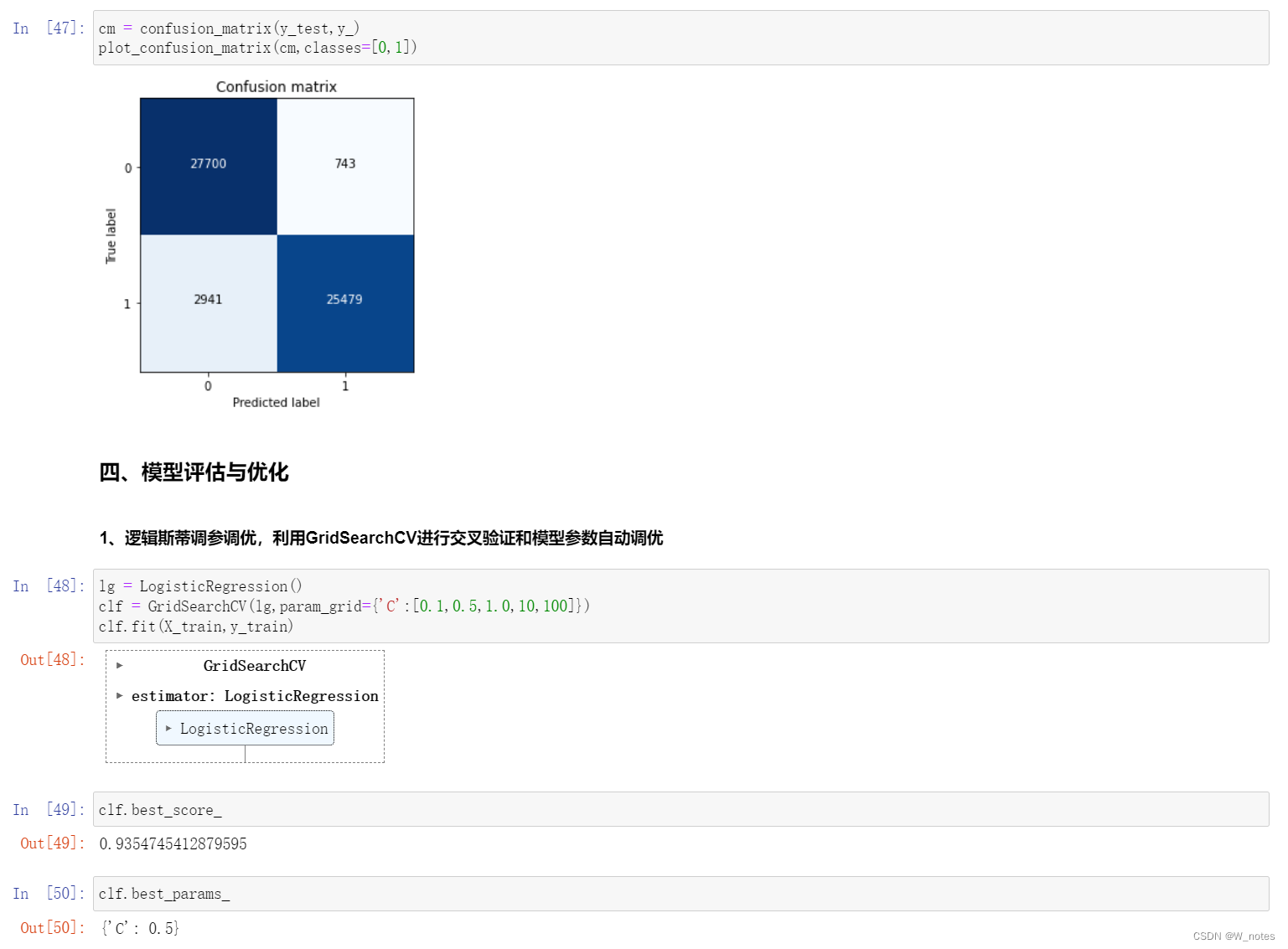
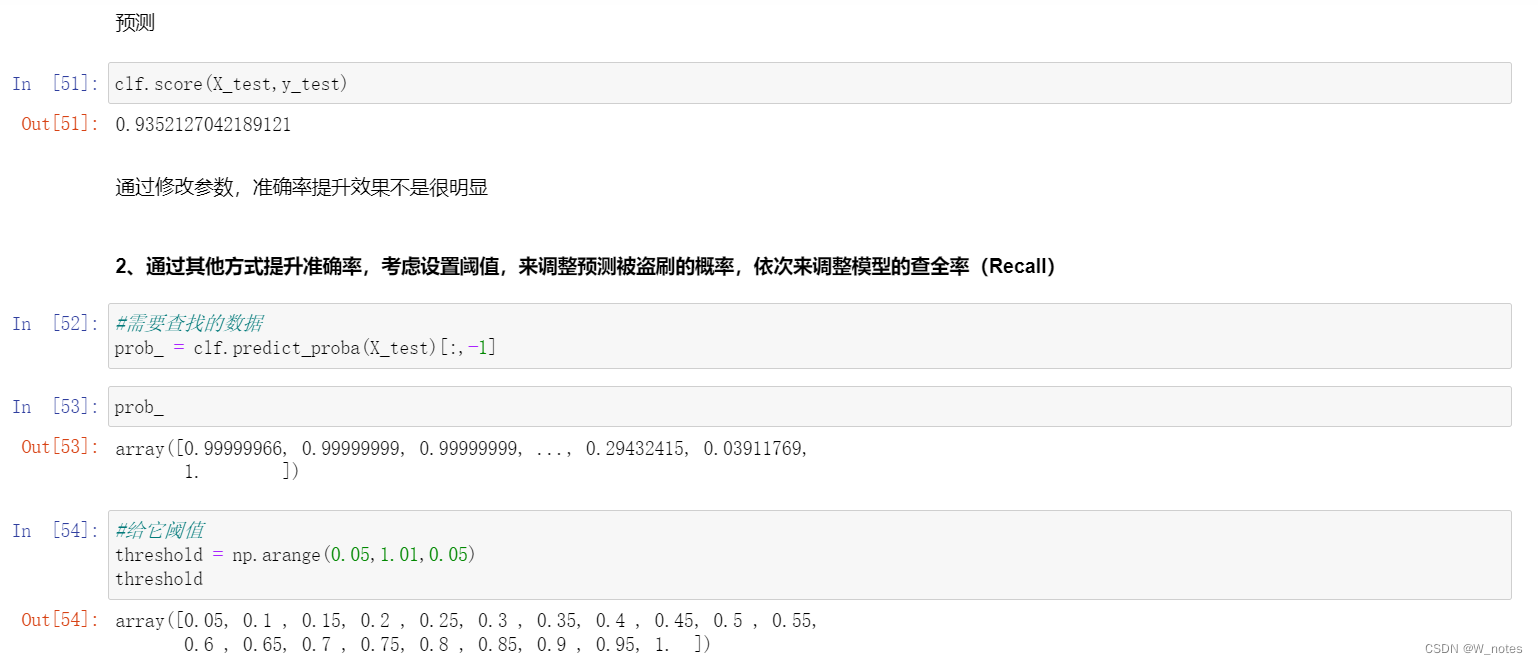
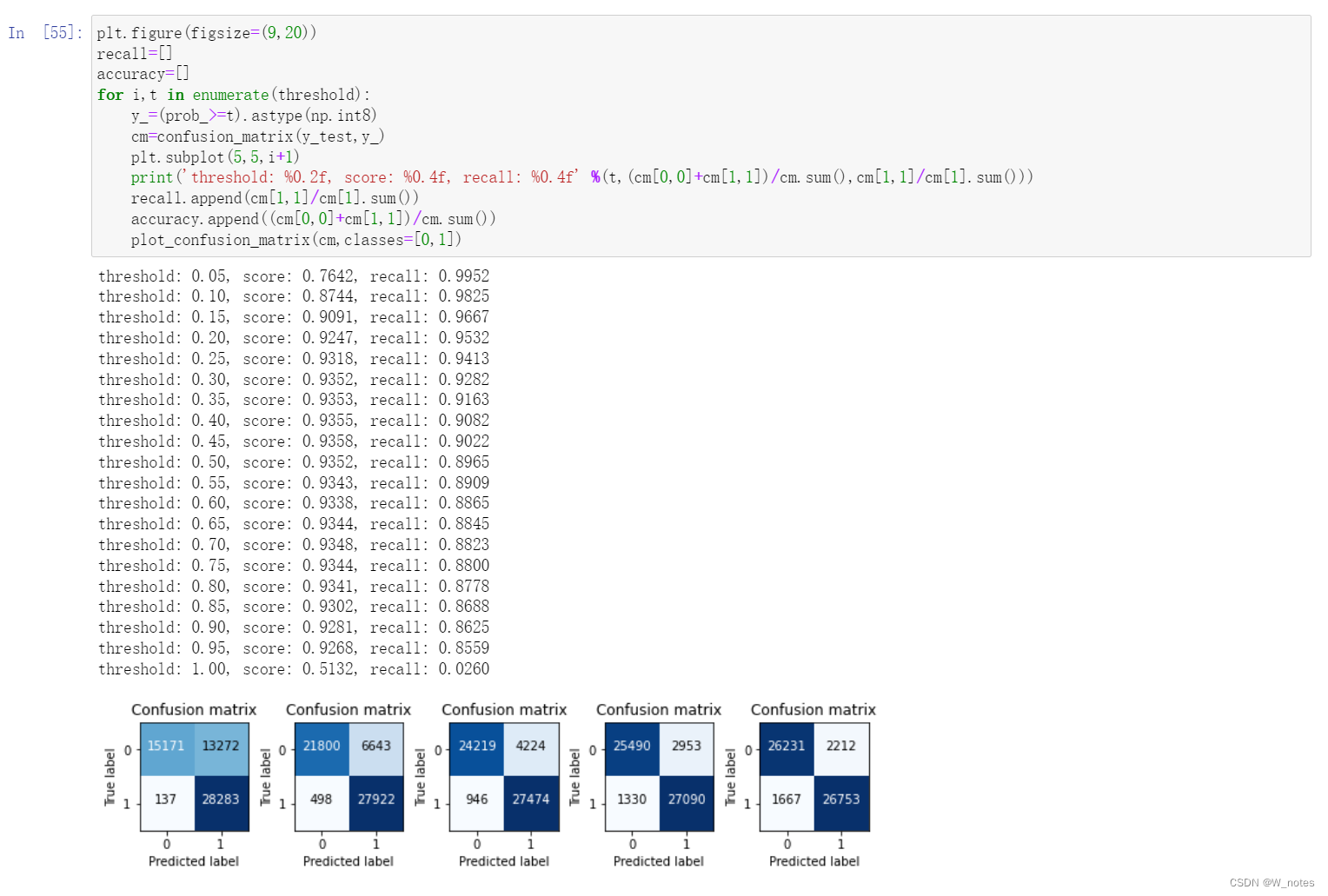
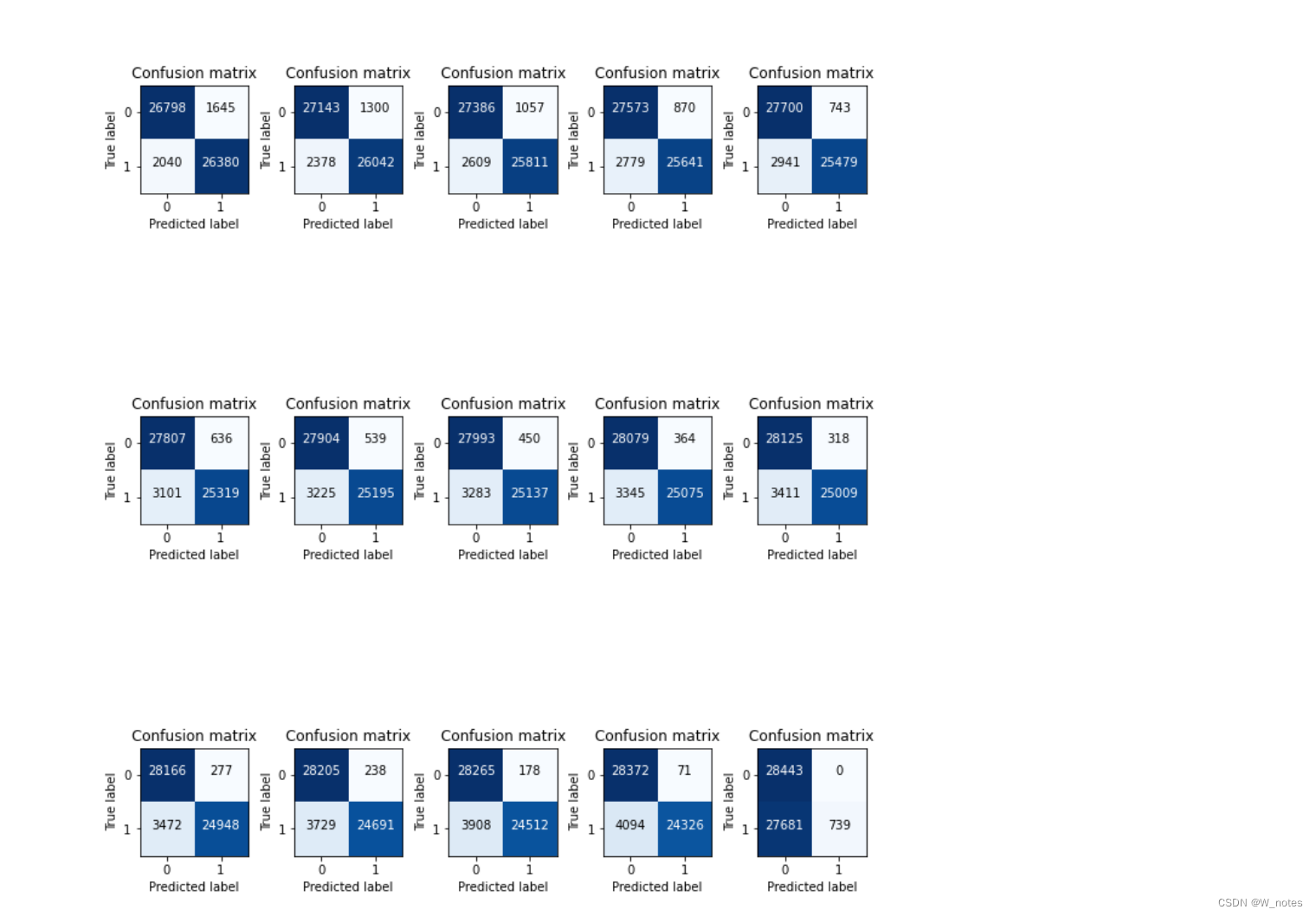
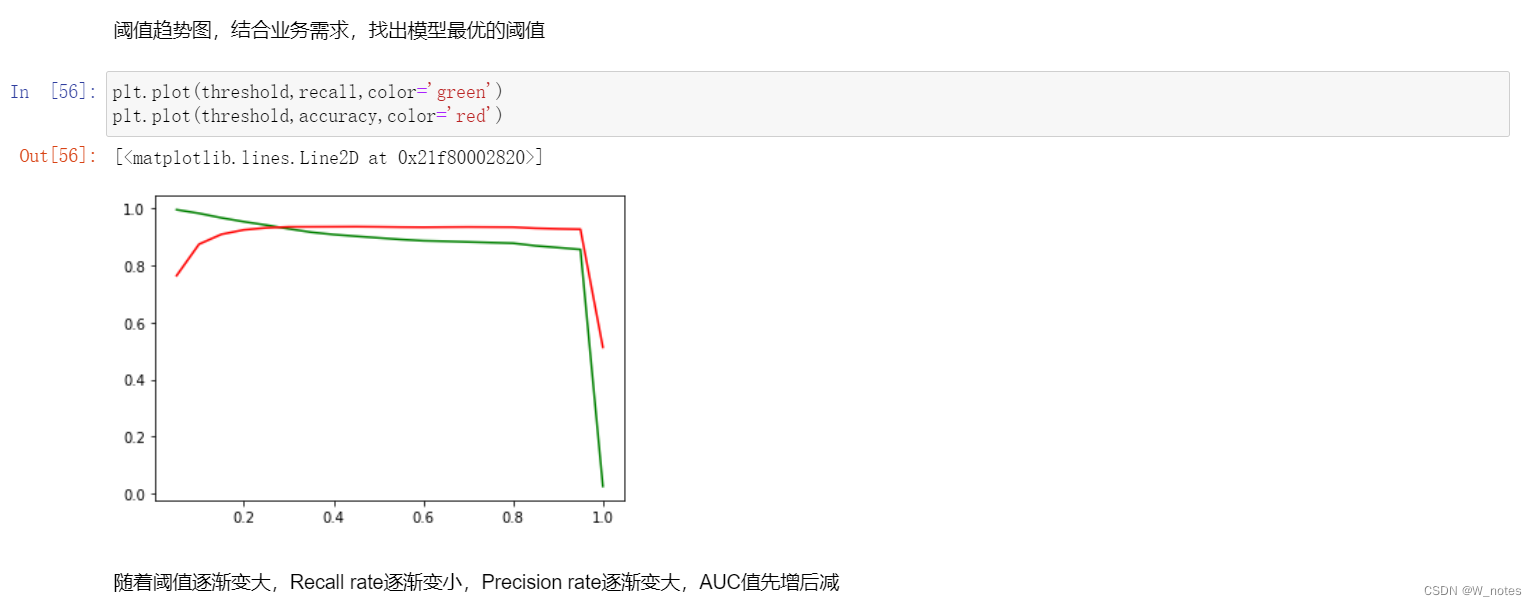
最优阈值:
阈值越小,recall值越大,模型能找出信用卡被盗刷的数量就更多,但是误判的数量也较大。随着阈值逐渐变大,recall rate逐渐变小,precision rate逐渐变大,误判的数量也随之减少。通过调整模型阈值,控制模型反信用卡欺诈的力度,若想找出更多的信用卡被盗刷就设置较小的阈值,反之,则设置较大的阈值。
实际业务中,阈值的选择取决于公司业务边际利润和边际成本的比较;当模型阈值设置较小的值,确实能找出更多的信用卡被盗刷的持卡人,但随着误判数量增加,不仅加大了贷后团队的工作量,也会降低误判为信用卡被盗刷客户的消费体验,从而导致客户满意度下降,如果某个模型阈值能让业务的边际利润和边际成本达到平衡时,则该模型的阈值为最优值。当然也有例外的情况,发生金融危机,往往伴随着贷款违约或信用卡被盗刷的几率会增大,而金融机构会更愿意不惜一切代价守住风险的底线。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/355790
推荐阅读
相关标签

