
- 1Vue3响应式原理-computed_vue3 computed无效
- 2wireshark绿色便携版 v3.4.2.0_wiresharkportable
- 3记录:小程序图片懒加载方法_lazy-load 小程序
- 4Dirichlet Distribution(狄利克雷分布)与Dirichlet Process(狄利克雷过程)_matlab dirichlet分布
- 5Midjourney学习系列之三——宝藏网站与博主分享_mj参考网站
- 6知识图谱在深度学习目标检测中的应用_知识图谱和目标识别
- 7c++使用MYSQL教程_mysql c++
- 8uniapp微信支付宝小程序跳转视频号财富号直播间_uniapp小程序跳转到目标直播间
- 9Linux x86 和ARM什么区别?_linux arm和x86区别
- 10OpenCV 对np.uint32的图像进行可视化,失败_opencv np无效
NLP技术中的Tokenization
赞
踩

©作者 | Gam Waiciu
单位 | QTrade AI研发中心
研究方向 | 自然语言处理
前言
今天我们来聊一聊 NLP 技术中的 Tokenization。之所以想要聊这个话题,是因为,一方面在 NLP 技术中 Tokenization 是非常重要的一个环节,它是数据进入到模型进行计算之前所必须的一个步骤;一方面,不少 NLPer 可能关注的往往是模型的花里胡哨,炼丹 Tricks 的纷繁复杂又或者是数据清洗的枯燥无味,对于字符串数据进入到模型之前所必经的 Tokenization 环节知之甚少;另一方面,笔者曾在工作过程中无意发现字符经过 XLM-Roberta 的 Tokenization 会多出“_”这个特殊符号,于是在 Tokenization 这方面进行了一番调研,便有会意,遂欣然忘食,执笔著之。

引言
1.1 什么是Tokenization
相信大家作为一个 NLPer 都很熟悉 NLP 的流程,如下图。无论大家熟悉不熟悉,请准许我先介绍一番。
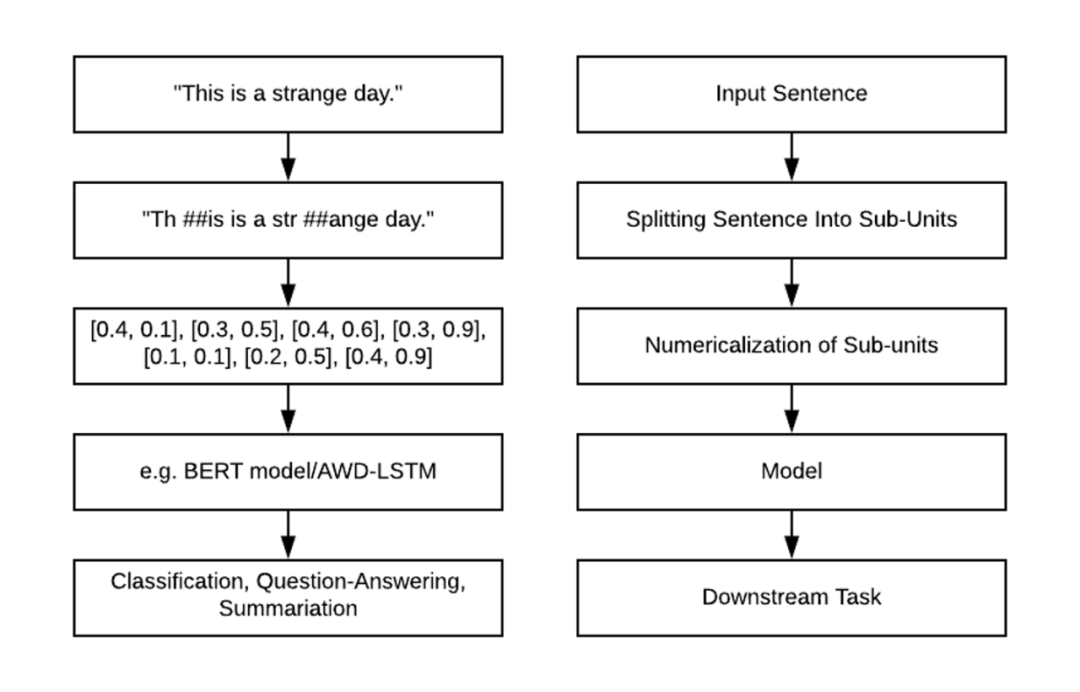
图1.1 NLP流程
首先,我们将文本句子切分成一个个子单元,然后将子单元数值化(映射成向量),接着将这些向量输入到模型进行编码,最后输出到下游任务中进一步得到最终结果。对于为什么要数值化,是因为除了决策树模型,机器学习中绝大多数模型是不支持字符串数据的,想要模型能够顺利有效地学习,必须对字符串数据先数值化。另外,我们并不是直接对输入句子或者单词进行数值化,我们需要先将其切分成一个个有限的子单元,然后将这些子单元数值化。
而这个将原始文本切分成子单元的过程就叫做 Tokenization。国内很多翻译为“分词”,私以为,这样的翻译多少会让人有误解,让人误以为是针对中文进行词语的分割。尽管这是 Tokenization 的任务之一,但并不局限与此(它要做的还有更多)。
1.2 Tokenization的难点
由 1.1 节我们可以知道,Tokenization 其实是为数值化作准备,数值化的过程必然需要映射,而映射又需要一个目标集合或者说映射表。这里就产生一个问题了,如果我们切分出来的子单元种类是非常多甚至无限多的,那么我们就需要一个非常庞大的映射表了,这就会导致巨大的内存消耗以及过多的计算量,这显然是不理想的。
一种做法是将大量的低频子单元使用几个特定的符号(例如,[UNK])代替,这样便缩小了映射表了,但是这样一来我们原始文本就损失了很多信息了。另外,对于切分出来的子单元到底是什么,可以是任意的东西吗?直观上来讲,显然不应该是任意的东西,这些被切分出来的子单元应该是有一定的含义的。比如:【unhappily】如果切分成了【un, happ, ily】显然要比【unh ap pily】要合理得多。因为【un, happ, ily】中每一个子单元都有一定的含义,而后者不然。
综上所示,Tokenization 的难点便是——如何获得理想的切分,使文本中所有的 token 都具有正确的语义,并且不会存在遗漏(out of the vocabulary 问题)。
1.3 三类Tokenization方法
这里笔者对 Tokenization 按切分的粒度分成了三大类,一是按词粒度来分,二是按字符粒度来分,三是按 subword(子词粒度来分)。对于词粒度切分这类方法是自然而然的,因为我们人类对于自然语言文本的理解就是按照这种方式切分的。对于字符粒度,这是一种极简的方法,基本不需要什么技巧,但是它有很多弊端。对于 subword 粒度切分,它似乎继承了儒家学派的中庸之道,是这样一种折中的方法。三种方法概括如下图:
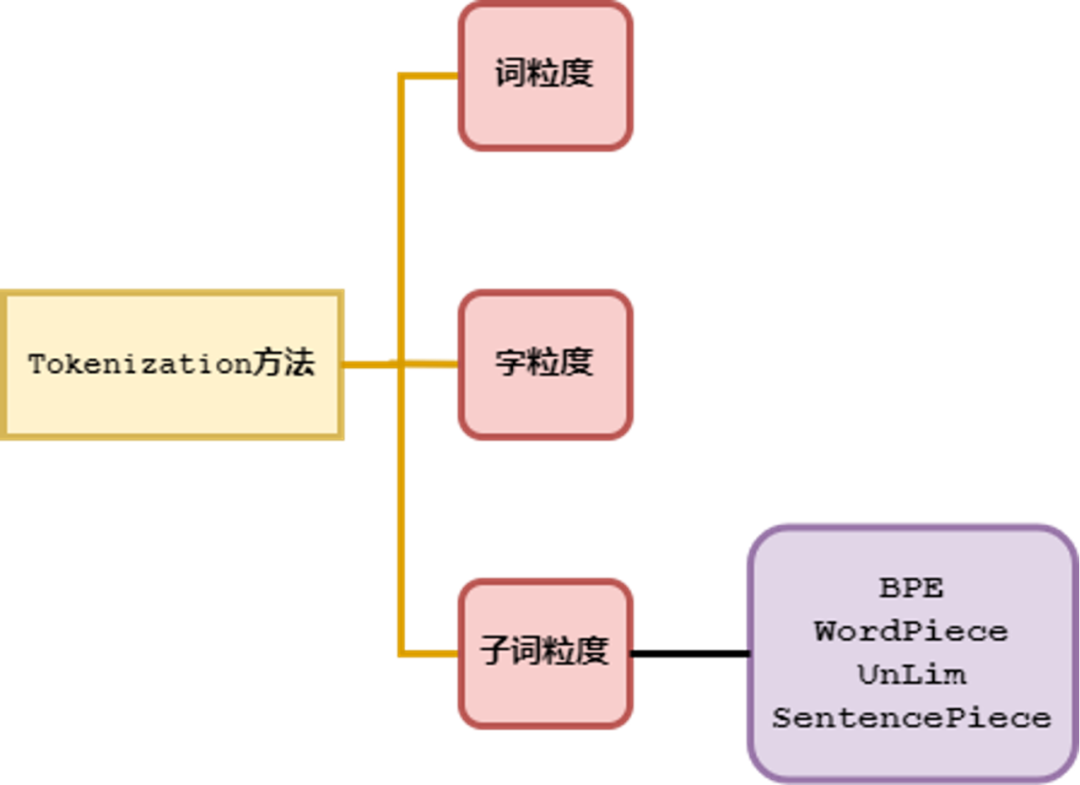
图1.2 Tokenization方法(按粒度分类)

词粒度Tokenization
本节我们来讨论词粒度的相关方法。词粒度的切分就跟人类平时理解文本原理一样,可以用一些工具来完成,例如英文的 NLTK、SpaCy,中文的 jieba、HanLP 等。
首先我们直观地看一下词粒度进行 Tokenization 是怎么样的一种方法。


