
热门标签
热门文章
- 1linux下载命令wget命令详解_wget -t
- 2SpringBoot源码解读与原理分析(十三)IOC容器的启动流程_springbootioc流程
- 3图文讲解Zabbix 分布式监控平台安装过程_zabbix server is runningnolocalhost:10051
- 4微信小程序开发
- 5视频分布式上传方案详解_大视频分段上传方案
- 6php mysql多线程处理数据_PHP中多线程处理
- 7spring boot大学毕业设计管理系统 毕业设计源码030945_sprintboot 毕业相间不
- 8砂石厂智能监管预警系统 解决传统监管难题
- 9CSS3动画1_css3 donghua1
- 10Linux的文件类型分类_linux文件类型
当前位置: article > 正文
从头开始构建和训练 Transformer(上)_transformer 搭建训练模型
作者:小丑西瓜9 | 2024-03-16 12:47:30
赞
踩
transformer 搭建训练模型
1、导 读
2017 年,Google 研究团队发表了一篇名为《Attention Is All You Need》的论文,提出了 Transformer 架构,是机器学习,特别是深度学习和自然语言处理领域的范式转变。
Transformer 具有并行处理功能,可以实现更高效、可扩展的模型,从而更容易在大型数据集上训练它们。它还在情感分析和文本生成任务等多项 NLP 任务中表现出了卓越的性能。
在本笔记本中,我们将探索 Transformer 架构及其所有组件。我将使用 PyTorch 构建所有必要的结构和块,并且我将在 PyTorch 上使用从头开始编Transformer。
- # 导入库
-
- # PyTorch
- import torch
- import torch.nn as nn
- from torch.utils.data import Dataset, DataLoader, random_split
- from torch.utils.tensorboard import SummaryWriter
-
- # Math
- import math
-
- # HuggingFace 库
- from datasets import load_dataset
- from tokenizers import Tokenizer
- from tokenizers .models import WordLevel
- from tokenizers.trainers import WordLevelTrainer
- from tokenizers.pre_tokenizers import Whitespace
-
- # Pathlib
- from pathlib import Path
-
- # Typing
- from Typing import Any
-
- # 循环中进度条的库
- from tqdm import tqdm
-
- # 导入警告库
- import warnings

2、Transformer 架构
在编码之前,我们先看一下Transformer的架构。
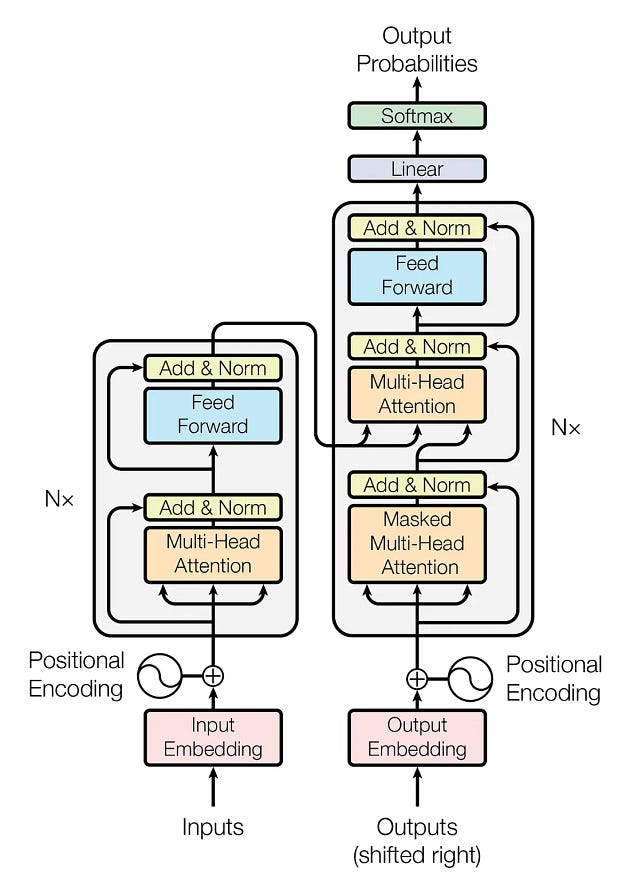
Transformer 架构有两个主要模块:编码器和解码器。让我们进一步看看它们。
编码器:它具有多头注意力机制和全连接的前馈网络。两个子层周围还有残差连接,以及每个子层输出的层归一化。模型中的所有子层和嵌入层都会产生维度 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

