
- 1Android Studio Kotlin代码和java代码相互转化_android studio kotlin转java
- 2Base64编码和解码,乱码_base64解码乱码
- 3如何重塑数字产业生态?树莓集团引领行业新思考
- 4关于编码器测速的问题总结_编码器的极对数旋转一圈多少个脉冲
- 5基于ArcGIS的流域提取流程_arcgis流域提取
- 6java 数据结构之 map 及非线程安全实现类hashmap treemap linkedhashmap概述
- 7[Mysql] 更新数据_mysql更新语句
- 8Spring 数据源_java spring datesource
- 9外挂级OCR神器:免费文档解析、表格识别、手写识别、古籍识别、PDF转Word_表格ocr
- 10SecureCRT使用的一些小技巧--批量导入session_crt导入session
哈希 | unordered_set + unordered_map 的模拟实现(上)
赞
踩
目录
什么是 unordered_set + unordered_map ?
什么是 unordered_set + unordered_map ?
unordered_set :
unordered_set - C++ Reference (cplusplus.com)

1、unordered_set 是每个数据只出现 1 次(去重),且不排序的容器
2、unordered_set 中的数据不可以修改,但是可以插入和删除
3、unordered_set 虽然数据无序,但是每个数据是根据 哈希值 存储的,哈希值可以帮助我们快速找到数据
4、unordered_set 的查找比 set 快,但在遍历上比 set 效率低
5、unordered_set 至少是正向迭代器(没有反向迭代器)
unordered_map :
unordered_map - C++ Reference (cplusplus.com)

1、unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与
其对应的value。
2、在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此
键关联。键和映射值的类型可能不同。
3、在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内
找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
4、unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭
代方面效率较低。
5、unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问
value。
6、它的迭代器至少是前向迭代器。
哈希
数组的存储中,假设 值为 i 的数据存储在下标为 i-1 的位置中,比如值为 4 ,则存储在 3 位置,当数据为 1 2 3 4 5 7 9 时,我们最多只需要开大小为 9 的数组就可以存储所有的数据,当数据为 1 2 100 999 1000 2000 2999 3000 时,我们至少需要开大小为 3000 的数据才可以存储所有的数据,且由于数据不集中,导致数组的空间严重浪费。我们可以采用哈希来解决这个问题。
哈希表:
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。我们称这个函数为哈希函数。
在该结构中:
1、插入元素 : 根据待插入元素的 key ,以哈希函数计算出该元素的存储位置并按此位置进行存放
2、搜索元素 :对元素的 key 进行同样的计算,把求得的函数值当做元素的存储位置,在结构中根据此位置取出元素 和 key 比较,若关键码相等,则搜索成功
按照哈希法构造出来的结构称为 哈希表(Hash Table)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity(capacity为存储元素底层空间总的大小)
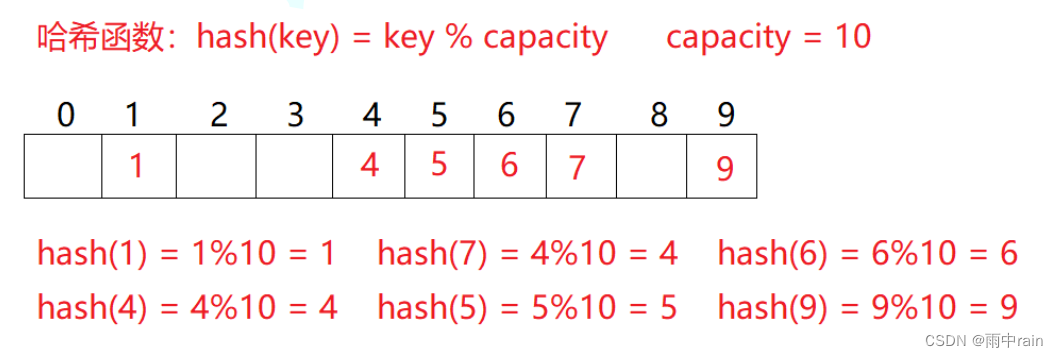
用该方法进行搜索不必进行多次关键码的比较,只需要根据哈希函数计算出存储位置,直接到存储位置查找,因此搜索的速度比较快。
问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?
哈希冲突:
假设两个数据元素的关键字 4 和 44,虽然 4 和 44 是不同的值,但有 Hash( 4 ) == Hash( 44 ),即不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
如何解决哈希冲突:
闭散列:
当发生哈希冲突时,如果哈希表未被填满,说明哈希表中仍存在空位,我们可以把 key 存储在发生冲突位置的下一个空位置,比如存储 44 时,4 和 44 发生哈希冲突了,且位置 5 6 7 都不为空,位置 8 为空,那么把 44 存储在位置 8
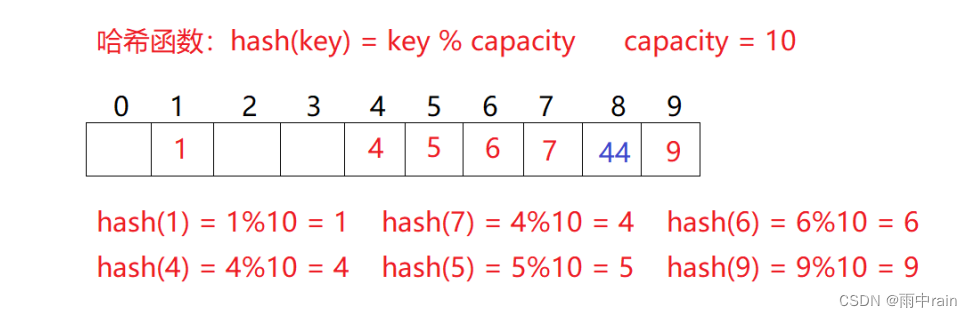
当存储 44 时,如果哈希表全部被填满了,此时需要扩容,同时说明 44 发生了很多次哈希冲突,把所有位置都探测了一遍,这样会导致效率低,有什么方法可以减少哈希冲突的次数?
负载因子:
负载因子 = 填入表中的元素个数 / 哈希表的长度
当哈希表的长度固定时,
1、当负载因子越大时,说明哈希表中的元素越多,发生哈希冲突的可能性越大
2、当负载因子越小时,说明哈希表中的元素越少,发生哈希冲突的可能性越小
所以可以通过负载因子决定是否扩容,而不是在哈希表完全填满时才扩容。应该严格限制负载因子为 0.7 ~ 0.8 以下,才可以提高插入和查找的效率。
闭散列的模拟实现:
为什么需要标记状态?
在实现之前,有一个问题值得注意:
在查找 key 时,我们根据哈希函数计算出 key 应该存储在位置 Hash(key)中,
1、当位置 Hash(key)为空时,我们认为哈希表中不存在 key,结束查找
2、当位置 Hash(key)不为空,且该位置的数据 = key 时,结束查找
3、当位置 Hash(key)不为空,且该位置的数据和 key 不相等时,说明 key 发生过哈希冲突,++Hash(key),一直往后找,直到 Hash(key)为空 或者 位置 Hash(key)的值 = key 时,结束查找
假设数据为 5 15 4 6 11 8 ,在插入 15 时,5 和 15 发生了冲突,所以 15 存储在位置 6 ,在插入 6 时,15 和 6 发生哈希冲突了,所以 6 存储在 位置 7 ,在全部数据插入完之后,如果删除 15,则位置 6 空了,如果此时查找 6 ,按照哈希函数,6 应该存储在位置 6 ,而此时位置 6 为空,根据查找的思路,我们会认为哈希表中没有 6 这个数据,并不会继续往后找,因为程序不知道存储 6 时发生了哈希冲突,6 被存储到位置 7 了

所以每个位置除了存储数据之外,我们需要标记每个位置的状态,来避免这个问题:
1、如果位置 Hash(key)的状态为 EXIST,且该位置的值 = key,结束查找
2、如果位置 Hash(key)的状态为 DELETE,则需要往后找
3、如果位置 Hash(key)的状态为 EMPTY,则该位置确实为空,结束查找
- enum State
- {
- EMPTY,//当前位置为空
- EXIST,//当前位置已经被占了
- DELETE//当前位置被删除
- };
-
- template<class K, class V>
- struct HashData
- {
- pair<K, V> _kv;
- State _state = EMPTY;
- };
-
- template<class K,class V,class Hash=HashFunc<K>>
- class HashTable
- {
- public:
- HashTable(size_t size = 10)
- {
- _tables.resize(size);//先开一定的size
- }
- private:
- vector<HashData<K, V>> _tables;
- size_t _n = 0;//存储哈希表元素的个数
- };

为什么需要 HashFunc?
在哈希函数中,我们认为 key 不是字符型,而是 整型、浮点型等可以进行计算的类型,从而计算出哈希值,如果 key 为 string 类型,那么无法计算哈希值了,因为字符串无法进行加减乘除,怎么解决这个问题呢?
我们写个仿函数,让 string 可以转换为可以计算的类型:
由于字符串是用 ASCII 存储的,我们可以利用 ASCII 来计算哈希值。为了辨别众多的字符串,我们不能只用字符串的第一个字符的 ASCII 来计算哈希值,这样会加剧哈希冲突,我们可以把字符串的所有字符的 ASCII 进行相加,相加得到的和来计算哈希值。
这样会导致一个问题:对于类似 "abcd" "acdb" "aadd" 这样的字符串,ASCII 相加的结果相等,没办法做很好的区分,可以在每次相加之后乘以一个权值,减少和相等的概率,这里用 131 来作为权值。
- template<>
- struct HashFunc<string>
- {
- size_t operator()(const string& str)
- {
- size_t sum = 0;
- for (auto e : str)
- {
- sum += e;
- sum *= 131;
- }
- return sum;
- }
- };
查找 Find:
哈希表是由 vector 实现的,在计算哈希值时,可以对 capacity 取模吗?
size_t hashi = hs(key) % _tables.capacity();不可以,假设 vector 为 nums,用下标遍历 nums 时,一般用 i<nums.size()来判断 for循环是否结束,而不是用 i<nums.capacity() 来进行判断
for(size_t i=0;i<nums.size();i++)意味着,如果我们对 capacity 进行取模,哈希值可能会超过 size 的范围,即越界了,那我们在遍历哈希表时就无法访问超出 size 范围的值。

- HashData<K,V>* Find(const K& key)
- {
- Hash hs;
- size_t hashi = hs(key) % _tables.size();//不用自己写size 函数,因为vector有自带的size
-
- while (_tables[hashi]._state !=EMPTY )
- {//值可能hashi位置,也可能在hashi的后面
-
- if (_tables[hashi]._kv.first == key
- && _tables[hashi]._state==EXIST)
- {//值相等且值存在
- return &_tables[hashi];
- }
- ++hashi;
- hashi %= _tables.size();//取模,如果++hashi之后,hashi越界了,会重新回到0开始找
- }
- return nullptr;//值在哈希表中不存在
- }
插入 Insert:
如果在插入前,哈希表的负载因子>= 0.7了,此时需要扩容,扩容不是仅扩大 vector 的空间,仅扩大空间,扩容后再计算哈希值时,所有的关系都错乱了,因为 size 已经不是原来的 size 了,所以不仅需要扩大空间,还需要把原本哈希表里的数据重新映射到新的哈希表中。
我们在扩容时,可以再次调用 Insert 函数来把旧表的数据映射到新表。因为扩容后,空间已经变大了,再次调用 Insert 函数时,负载因子已经小于 0.7 了,不会再次进入扩容函数,不会出现死循环,而是把旧表的数据映射到新表中。
在插入时,如果哈希值所在的位置已经被占了(EXIST),需要继续往后走,直到找到位置的状态为 EMPTY / DELETE 时,才可以插入。
- bool Insert(const pair<K, V>& kv)
- {
- if (Find(kv.first))
- return false;//值在哈希表已经存在了
-
- Hash hs;
- if (_n*10 / _tables.size() >=7)
- {//如果没有*10,比如7/10,整型和整型相除结果小于1,那么商为0,*10可以避免这种尴尬
- //超出负载因子,扩容
- HashTable<K,V,Hash> newHt(2 * _tables.size());
- for (auto& e:_tables)
- {
- if (e._state == EXIST)
- {
- //把旧表的数据重新映射到新表中
- newHt.Insert(e._kv);//插入到新表中
- }
- }
- _tables.swap(newHt._tables);//只需要交换vector
- }
- size_t hashi = hs(kv.first) % _tables.size();
-
- while (_tables[hashi]._state == EXIST)
- {//如果 hashi 位置已经被占了
- ++hashi;
- hashi %= _tables.size();
- }
- _tables[hashi]._kv = kv;
- _tables[hashi]._state = EXIST;
- ++_n;//哈希表个数++
- return true;
- }
删除 Erase:
复用 Find 来确定 key 是否在哈希表中:
1、当哈希表中不存在 key 时,返回假
2、当哈希表中存在 key 时,把 key 所在的位置的状态设为 DELETE,把哈希表的数据的个数 -1,随后返回真
- bool Erase(const K& key)
- {
- //auto ret = Find(key);
- HashData<K, V>* ret = Find(key);
- if (ret)
- {
- //值在哈希表中存在
- --_n;
- ret->_state = DELETE;
- return true;
- }
- else
- {
- return false;
- }
- }
开散列:
开散列法又叫链地址法(开链法),首先对关键码集合用哈希函数计算哈希值,具有相同哈希值的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。即原本每个位置存储的是数据,现在每个位置存储的是链表。
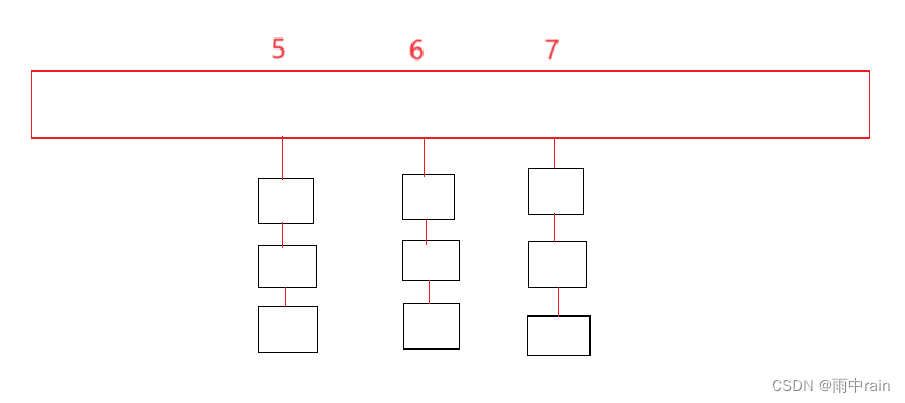
结点的实现:
- template<class K,class V>
- struct HashNode
- {
- pair<K, V> _kv;
- HashNode* _next;//指向下一个结点
-
- HashNode(const pair<K,V>& kv)
- :_kv(kv)
- ,_next(nullptr)
- { }
- };
开散列的模拟实现:
析构函数:
如果不写析构函数,vector 默认的析构函数不会释放链表,而链表的结点是手动开辟的,这会导致内存泄漏,所以需要写析构函数,处理链表。
- template<class K,class V,class Hash= HashFunc<K>>
- class HashTable
- {
- typedef HashNode<K, V> Node;
- public:
- HashTable(size_t size = 10)
- {
- _tables.resize(size,nullptr);
- _n = 0;
- }
- ~HashTable()
- {
- for (size_t i = 0; i < _tables.size(); i++)
- {
- Node* cur = _tables[i];
- while (cur)
- {
- Node* next = cur->_next;
- delete cur;
- cur = next;
- }
- _tables[i] = nullptr;//把链表置空
- }
- }
- private:
- vector<Node*> _tables;//指针数组
- size_t _n;//数据的个数
- };
查找 Find:
和闭散列不同的是,我们用 key 计算出哈希值后,即找到了对应的哈希桶,我们需要遍历哈希桶(即遍历链表)来确定 key 是否存在
- Node* Find(const K& key)
- {
- Hash hs;
- size_t hashi = hs(key) % _tables.size();
- Node* cur = _tables[hashi];
- while (cur)
- {
- if (cur->_kv.first == key)
- {
- return cur;
- }
- cur = cur->_next;
- }
- return nullptr;
- }
插入 Insert:
在开散列的插入中,我们先开辟一个结点,根据 key value 的哈希值找到要插入的桶,在对应的链表中实现头插。
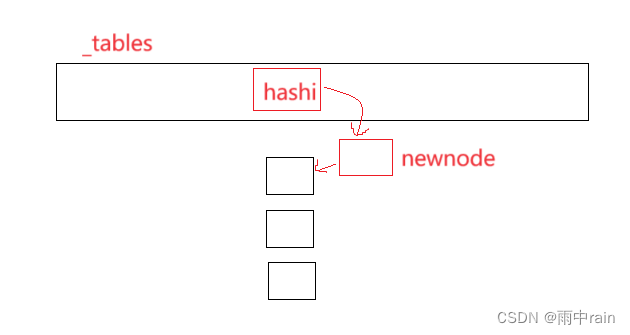
开散列如何考虑哈希冲突的情况呢?
假设桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可
能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希
表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,
再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可
以给哈希表增容。
开散列如何扩容呢?
我们开一个新表,然后遍历旧表,把旧表的结点的 key value 根据哈希函数重新映射到新表中,我们可以像闭散列一样在扩容时再次调用 Insert ,来把旧表的结点映射到新表吗?
不可以,在开散列的插入中,需要开辟结点,假设旧表有 1000 个结点,那么新表也需要开辟 1000 个结点,把旧表的结点全部映射到新表后,旧表的结点就全部释放掉了,这样会造成浪费,因为我们不必要开新表的 1000 个结点,只需要把旧表的结点插入到新表即可
- bool Insert(const pair<K,V>& kv)
- {
- if (Find(kv.first))
- {
- //值存在,不必插入
- return false;
- }
-
- Hash hs;
- //扩容
- if (_n == _tables.size())
- {
- //HashTable<K, V> newht(2 * _tables.size());
- vector<HashNode<K, V>*> newht(2 * _tables.size(), nullptr);
- //只需要创建新表vector,不需要重新创建新的哈希表
-
- for (size_t i = 0;i < _tables.size();i++)
- {//遍历旧表
-
- Node* cur = _tables[i];
- while (cur)
- {
- size_t hashi = hs(cur->_kv.first) % newht.size();
- //插入新表
- Node* next = cur->_next;
- cur->_next = newht[hashi];
- newht[hashi] = cur;
-
- cur = next;
- }
- _tables[i] = nullptr;//把旧表置空
- }
- _tables.swap(newht);
- }
-
- //空间充足
- Node* newnode = new Node(kv);
- size_t hashi = hs(kv.first) % _tables.size();
- //头插
- newnode->_next = _tables[hashi];
- _tables[hashi] = newnode;
- ++_n;
- return true;
- }
删除Erase:
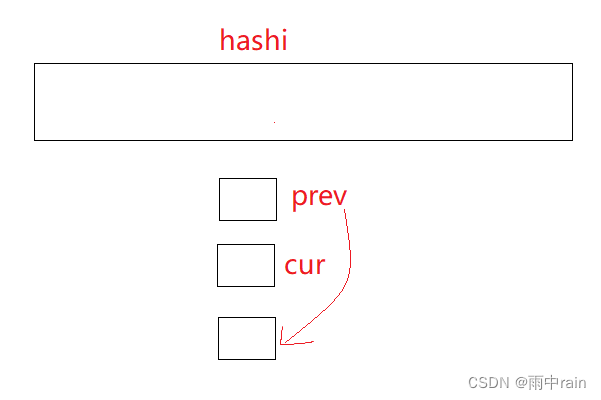
我们根据 key 的哈希值计算出 key 对应的桶,接着用 cur 遍历桶对应的链表,在删除时,由于是单链表,所以需要 prev 标记 cur 结点的前一个结点,并把 prev 初始化为空,假设 cur 是要删除的结点:
1、当 prev 为空,则链表为头删,把链表的头节点交给 cur 的下一个结点
2、当 prev 不为空,则 prev 的下一个结点指向 cur 的下一个结点,随后把 cur 结点释放即可
3、当 cur 为空,即遍历了整个链表都没有匹配的 key value 时,说明哈希表中不存在我们要删除的节点
- bool Erase(const K& key)
- {
- Hash hs;
- size_t hashi = hs(key) % _tables.size();
- Node* cur = _tables[hashi];
- Node* prev = nullptr;
- while (cur)
- {
- if (cur->_kv.first == key)
- {
- if (prev)
- {
- prev->_next = cur->_next;
- }
- else
- {
- //头删
- _tables[hashi] = cur->_next;
- }
-
- delete cur;
- --_n;
- return true;
- }
-
- prev = cur;
- cur = cur->_next;
- }
- return false;
- }

