
- 1AList搭建与使用(Win、Linux云服务器)_alist搭建教程
- 2STM32 入门教程(江科大教材)#笔记1_江科大stm32教程 csdn
- 3slowfast实现行为识别_slowfast行为
- 4<数据结构与算法>效率分析专项总结_算法效率分析
- 5万字长文,详细解读AI大模型技术原理!!_ai大模型原理
- 6百度大脑营业执照识别使用攻略_营业执照 ocr 数据采集
- 7五步搞定Android开发环境部署——非常详细的Android开发环境搭建教程_安卓环境配置
- 8利用 Python 实现有道翻译 (纯python、2020.6.1)_python 有道翻译
- 9python: tuple index out of range_pyhton tuple index out of range
- 10AS中导入新项目&手动配置gradle_as 导入gradle
Docker下的Flink_docker flink
赞
踩
在之前的文章Docker下的Storm中讲了通过Storm来进行实时计算任务,那么这本篇文章中将介绍怎样通过Flink来做实时计算任务。
Storm和Flink都是流处理框架,用于处理实时数据流。它们在一些方面有一些异同点。
1.Storm和Flink的架构不同。Storm是一个分布式的、实时的、容错的流处理系统,采用了主从架构。它使用了一个中心的协调节点(Nimbus)来管理和分发作业,以及多个工作节点(Supervisor)来执行计算任务。而Flink是一个基于事件驱动的流处理框架,采用了分布式流处理引擎的架构。它使用了一个中央调度器(JobManager)来协调和管理作业,以及多个任务管理器(TaskManager)来执行计算任务。
2.Storm和Flink在容错性上有一些区别。Storm使用了可靠性机制来确保数据的完整性和一致性,例如元组的可靠性传递和消息确认机制。而Flink采用了基于检查点的容错机制,通过定期保存计算状态的检查点来实现故障恢复和容错。
3.Storm和Flink的处理模型也有所不同。Storm采用了基于元组的处理模型,将数据流抽象为无界的元组流,通过定制的Bolt进行处理。而Flink采用了基于数据流的处理模型,将数据流抽象为有界的数据流,通过转换操作和窗口操作进行处理。
4.Storm和Flink在一些特性和用途上也有一些差异。Storm适用于一些低延迟、高吞吐量的实时应用,如实时分析、实时推荐等。而Flink更加通用,适用于各种批处理和流处理的场景,支持复杂的流处理和批处理操作,并提供了高级API和丰富的库和工具集。
拉取Flink镜像
在这里我们拉取的是1.13.0版本的Flink的官方Docker镜像:

docker pull flink:1.13.0拉取完成,通过命令进行检查,如果是Docker Desktop的话也可以直接在UI中检查镜像的拉取情况。
docker images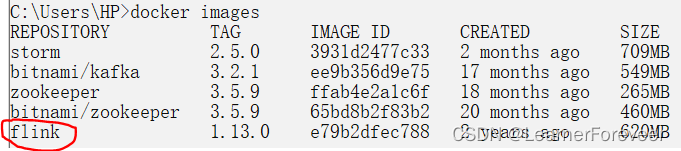

创建容器
这里通过docker-compose定义一个包含一个作业管理器和两个任务管理器的 Apache Flink 集群。作业管理器映射到主机的 8081 端口,而任务管理器则在同一网络下运行,并设置了各自的环境变量以连接到作业管理器。
在docker-compose.yml文件路径下的控制台输入下面的命令搭建集群:
docker-compose up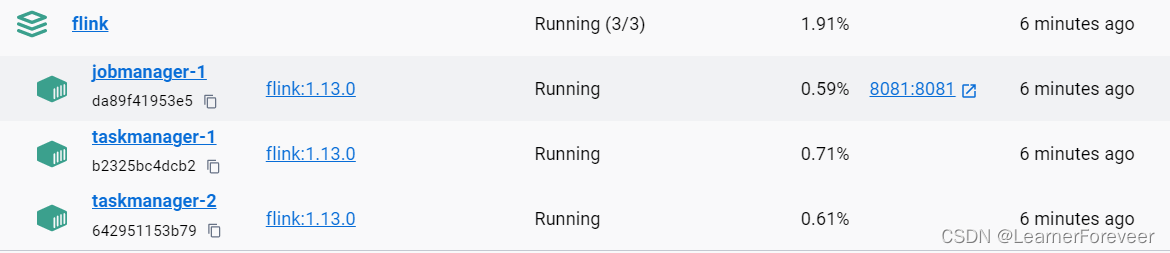
当然也可以通过docker命令查看当前已经搭建好了的flink集群:
docker ps
集群控制页面(Flink UI)
可以看到,在这里我们暴露了jobmanager的8081端口,通过这个端口我们可以打开Flink集群的UI界面并在上面提交程序jar包。
通过在浏览器的地址栏中输入localhost:8081即可打开Flink的UI页面:
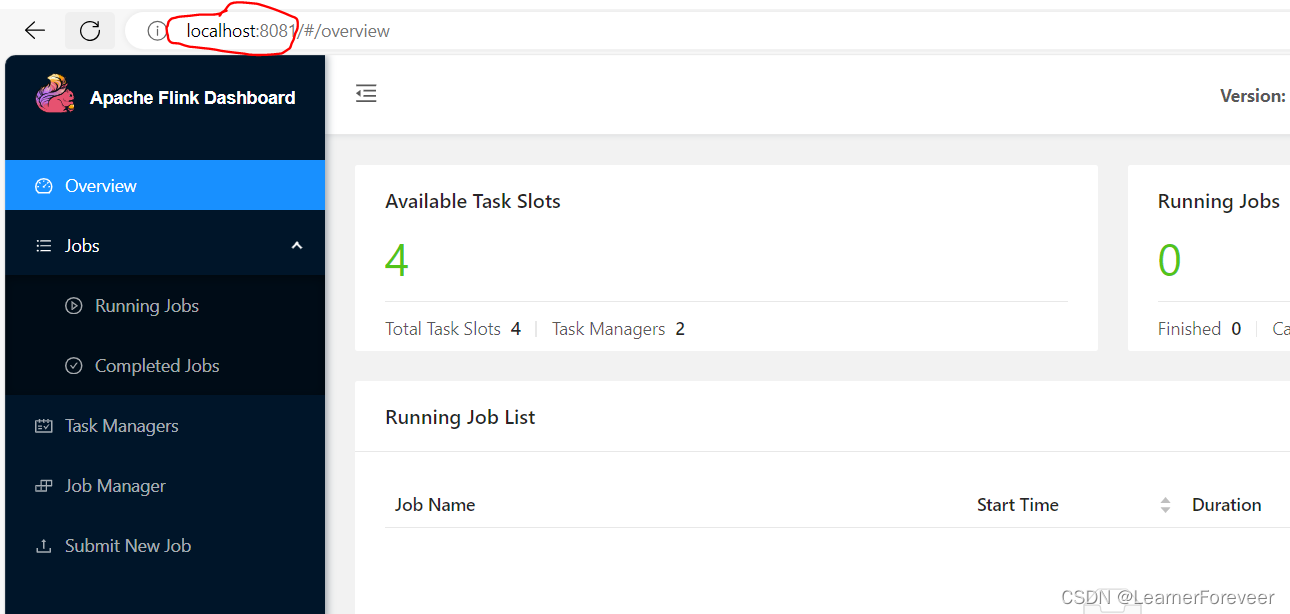
Flink的UI页面是用于展示和监控Flink集群的运行状态和统计信息的Web可视化界面,通过它可以方便地查看集群总览、作业列表、作业监控、Task监控和日志查看等功能,帮助用户监控集群运行情况、发现和解决问题,并进行作业调优。
创建Flink任务程序
Flink任务程序是基于Apache Flink框架编写的数据处理应用程序,它由一系列数据转换和操作组成,用于实现对数据流或批量数据的实时处理。任务程序可以定义数据源、数据转换操作和数据汇,同时可以设置数据窗口、触发器和窗口函数等,以实现各种复杂的数据处理逻辑。Flink任务程序具有高度可扩展性和容错性,能够处理大规模数据流和批量数据,并具备低延迟和高吞吐量的特性。
在这里我们通过下面的实例来学习Flink项目的创建和任务的编写,在这一部分可能对一些特别深入细致的代码内容没办法进行详细的解释,如果读者想要对Flink进行深入的理解请学习Flink的系列课程,本篇文章仅仅带大家熟悉怎样在Docker中创建Flink集群并完成相应的任务。
任务:现有游戏交易数据,其数据格式为(交易类型,交易金额),现在请编写Flink Java任务来完成对不同交易类型的交易总金额进行统计。
Maven依赖导入
如果要通过Flink向Redis,HBase等Sink数据需要导其他的依赖,这里我们只是将最终数据sink到控制台上,所以就不需要这些其他的依赖了,只需要最基础的Flink-Java依赖即可。
由于flink依赖的包比较多,所以通过一个maven pom文件属性对这些依赖的作用范围进行管理:
- <properties>
- <base.flink.scope>compile</base.flink.scope>
- </properties>
再次基础上将依赖写入:
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>1.13.0</version>
- <scope>${base.flink.scope}</scope>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.12</artifactId>
- <version>1.13.0</version>
- <scope>${base.flink.scope}</scope>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.12</artifactId>
- <version>1.13.0</version>
- <scope>${base.flink.scope}</scope>
- </dependency>
- </dependencies>

编写自定义数据源
Flink中已经实现好了的数据源包括本地集合、文件、Kafka、Socket等。本地集合数据源适用于小规模数据集的测试和调试,可以直接将数据加载到内存中进行处理。文件数据源可以从本地文件系统或分布式文件系统(如HDFS)中读取数据,支持各种格式的文件,如文本文件、CSV文件等。Kafka数据源可以将数据从Kafka消息队列中读取,实现实时数据处理。Socket数据源可以从网络socket中读取数据,常用于接收实时数据流。此外,Flink还支持自定义数据源,开发者可以根据自己的需求实现自己的数据源逻辑。这些数据源提供了灵活且高效的数据输入方式,使得用户可以方便地将各种数据接入到Flink中进行处理。
虽然Flink中有许多已经实现好了的数据源,但是为了对Flink的自定义源进行了解,所以在这里我会自己手动实现一个自定义数据源。
根据我们上面提到的任务,在这里我会创建一个自定义源来自动创建随机的交易流水:

- package source;
-
- import org.apache.flink.streaming.api.functions.source.SourceFunction;
-
- import java.util.Random;
-
- // 自定义实现Flink的SourceFunction接口,产生随机交易流数据
- public class RandomFlowSource implements SourceFunction<String> {
-
- // 创建一个Random对象用于生成随机数
- private static final Random rd = new Random();
-
- // 用于控制数据源是否在运行的标志位
- private volatile boolean isRunning = true;
-
-
- @Override
- public void run(SourceContext<String> sourceContext) throws Exception {
- // 当数据源在运行时持续产生数据
- while (isRunning) {
- // 生成随机的交易类型,假设有3种交易类型
- int transactionType = rd.nextInt(3);
-
- // 生成随机的交易金额,取值范围为0到100
- double transactionAmount = rd.nextDouble() * 100;
-
- // 将交易类型和金额拼接成字符串,并将其发送给下游算子
- sourceContext.collect(String.format("%d,%f", transactionType, transactionAmount));
-
- // 线程休眠100毫秒,模拟实际数据产生的时间间隔
- Thread.sleep(100);
- }
- }
-
- @Override
- public void cancel() {
- // 当取消数据源时,修改标志位使数据源停止产生数据
- isRunning = false;
- }
- }
创建任务处理程序
在完成了Flink数据源的创建之后,接下来就要完成最核心的任务处理部分的代码了。
- package tasks;
-
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.api.java.functions.KeySelector;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import scala.Int;
- import source.RandomFlowSource;
-
- public class TransactionAnalysisJob {
- public static void main(String[] args) throws Exception {
- // 获取Flink的执行环境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- // 添加自定义数据源RandomFlowSource作为数据输入源
- DataStreamSource<String> dataSource = env.addSource(new RandomFlowSource());
-
- // 使用MapFunction将输入的字符串转换成Tuple2<String, Double>类型的数据流
- SingleOutputStreamOperator<Tuple2<String, Double>> mapOp = dataSource.map(new MapFunction<String, Tuple2<String, Double>>() {
- @Override
- public Tuple2<String, Double> map(String s) throws Exception {
- // 将输入的字符串按逗号分割成交易类型和金额,并封装成Tuple2返回
- String[] fields = s.split(",");
- return Tuple2.of(fields[0], Double.parseDouble(fields[1]));
- }
- });
-
- // 按照交易类型进行分组,然后对交易金额进行求和
- SingleOutputStreamOperator<Tuple2<String, Double>> sum = mapOp.keyBy(new KeySelector<Tuple2<String, Double>, String>() {
- @Override
- public String getKey(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
- // 以交易类型作为key进行分组
- return stringDoubleTuple2.f0;
- }
- }).sum(1);
-
- // 打印输出结果
- sum.print();
-
- // 执行任务
- env.execute();
- }
- }
首先创建一个Flink的执行环境,并添加了自定义的数据源RandomFlowSource用作输入流。然后,通过MapFunction将输入的字符串转换成包含交易类型和金额的元组数据流,并按照交易类型进行分组,对交易金额进行求和。最后,打印输出结果并执行整个任务。
本地运行任务
本地运行任务就是在IDEA中直接运行任务程序,此时在控制台中将源源不断地输出计算的结果:
在这里我们之间将统计结果输出到了控制台中,如果想要输出到其他的地方就需要自定义Sink,或者通过Flink的其他输出依赖包将内容输出到其他的地方。
集群运行任务
要想在集群中运行Flink任务,我们需要将我们前面写的Flink代码打包成jar包并通过Flink UI提交。
提交之前将依赖的生命周期修改成provided:
- <properties>
- <base.flink.scope>provided</base.flink.scope>
- </properties>
之后使用Maven将代码打包:
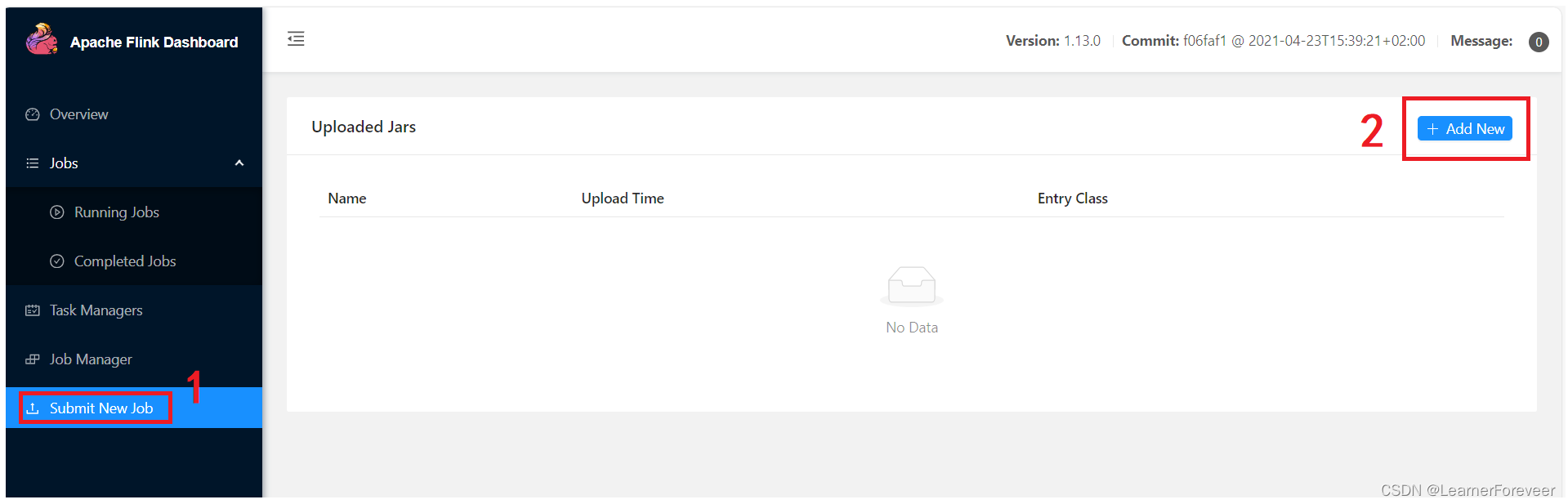
通过UI将jar包上传到集群上:
双击jar包完成上传:
上传完成后可以看到我们上传到集群中的jar包:
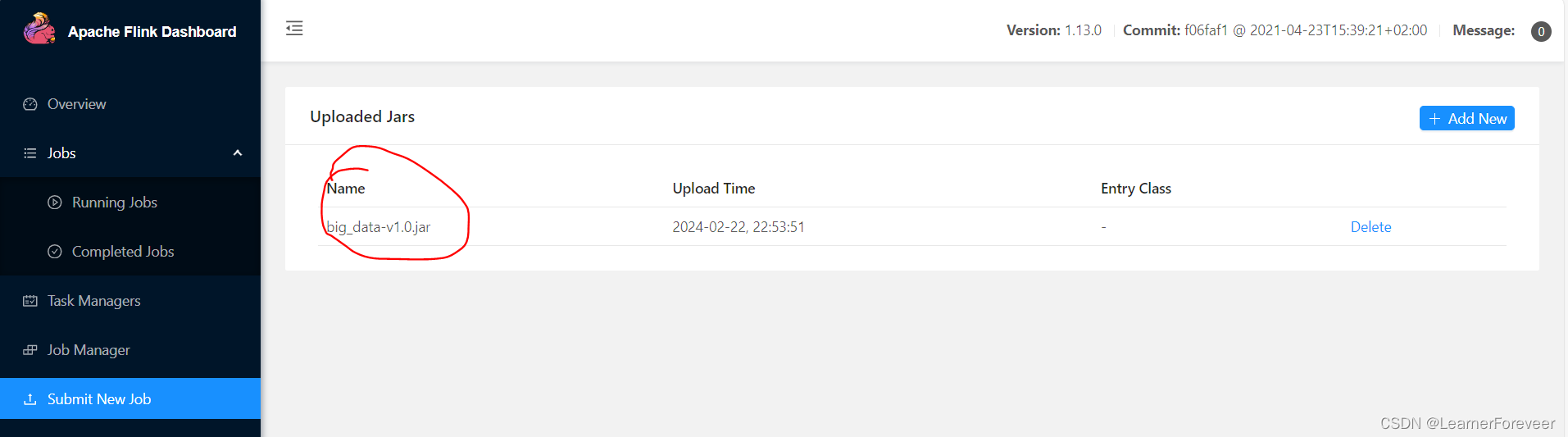
之后点击需要运行的jar包,输入并行数、主程序等开始执行任务:
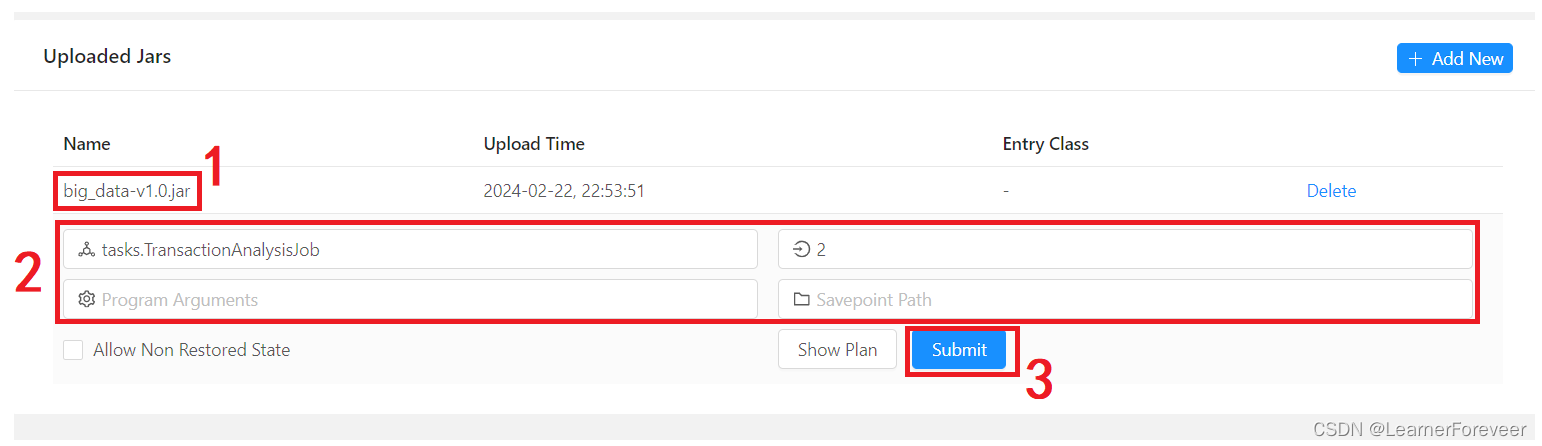
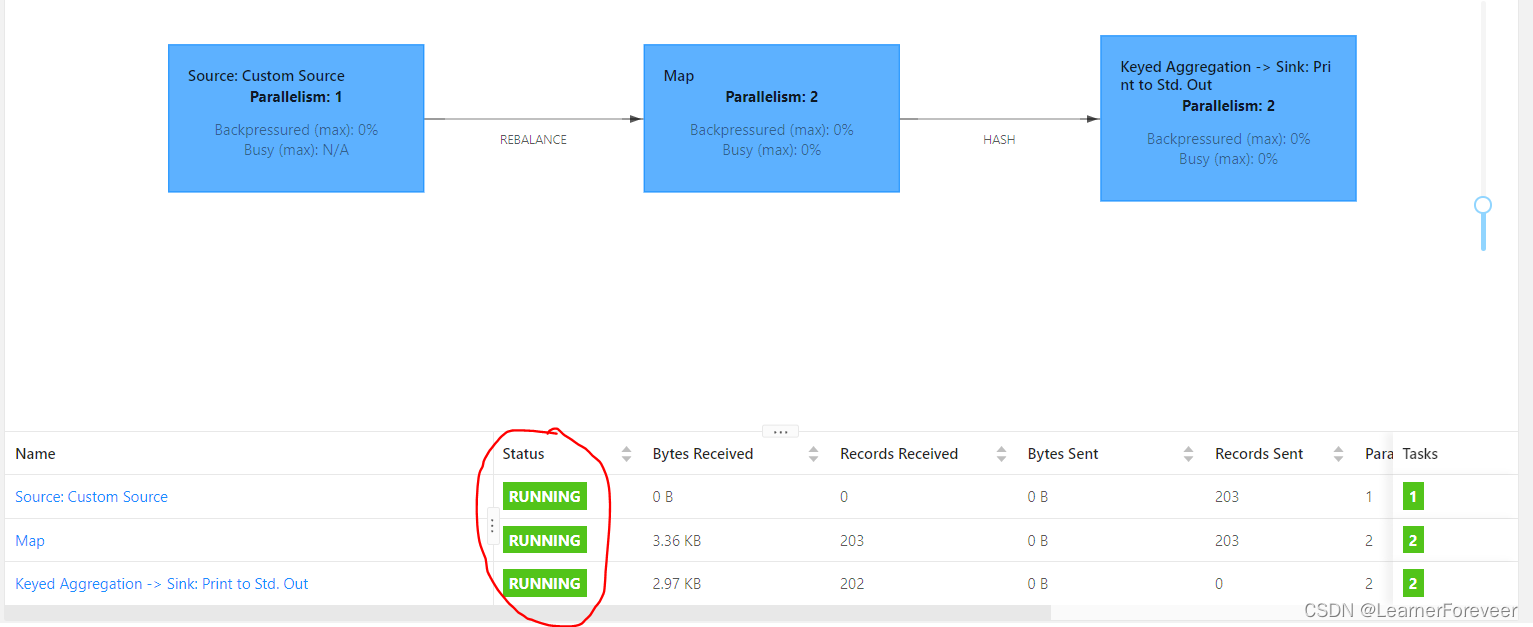
可以看到我们的任务已经成功开始执行了,如果想要查看输出的结果可以在Flink TaskManager中的logs看到(一般来说输出的内容在stdout中查看,但是由于特性由Docker创建的Flink集群不能直接在stdout中看到)。
docker logs -f <你的taskmanager结点的容器名>在本文中的taskmanager结点的容器名分别是taskmanager-1和taskmanager-2,在控制台中输入命令可以看到输出的结果如下:
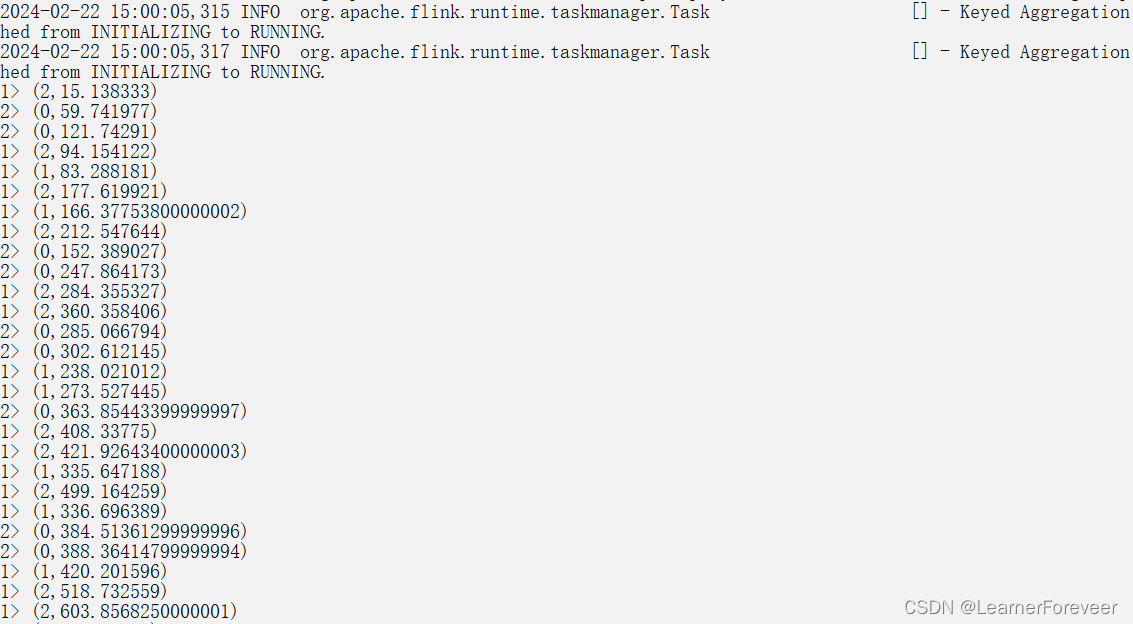
至此,对Docker下搭建的Flink集群就介绍到这里了。
上一篇:Docker下的Storm

