
热门标签
热门文章
- 1传播行为、事务回滚、分布式事务(CAP理论和BASE理论)
- 2微信小程序发送模版消息推送_微信公众号若依
- 3vue router 整合引入_router在线引入
- 4microblaze+yt8511+freertos 1000M网调试记录_microblaze 千兆以太网
- 5时隔两年,盘点ECCV 2018影响力最大的20篇论文_eccv 2018 image inpainting for irregular holes usi
- 6如何在 Elasticsearch 中选择精确 kNN 搜索和近似 kNN 搜索_elasticsearch knn 和fassi hnsw
- 7进阶指南!深入理解Java注解_深入java注解
- 8大数据技术概述与入门_全球信息量总和 数据
- 9基于springboot+vue的在线学习系统的设计与实现_在线学习系统详细类设计
- 10Electron常见问题 10 - video标签如何控制视频音量大小_video 标签 音量键没法操作
当前位置: article > 正文
机器学习6——聚类,k-means算法_arcgisk-means聚类
作者:天景科技苑 | 2024-08-10 11:35:57
赞
踩
arcgisk-means聚类
聚类
无监督学习方法,对无人为处理的无标签样本,将相似样本提取特征并聚集
k-means算法
迭代算法,将无标签数据按潜在联系聚类
基本原理:
1.若要聚类生成k类,首先随机选取k个点,作为聚类中心,标记为k个类
2.对所有数据点,计算到k个中心的距离,选择最近的中心点,标记为此类
3.对k个类的每个类计算,重新选取中心点
4.重复2、3,直到满足条件为止。
聚类中心初始化方法:
forgy法(随机选择k个值作为初始质心)、
random partition法(随机选择k个点,并将样本划分为k个簇,有k个点和簇计算得到k个聚类中心)
k means++ 法(随机选择1个聚类点,计算选出其余点中到已有聚类点距离和最大的点最为新聚类点,重复直到选出k个聚类点)
距离计算方法
欧式距离法(x方加y方和的开方)
曼哈顿距离(x间差的绝对值+y间差的绝对值,|x1-x2|+|y1-y2|)
切比雪夫距离(x间差的绝对值与y间差的绝对值的最大值,max(|x1-x2|,|y1-y2|))、
余弦距离(cosθ)、信息熵、明可夫斯基距离(曼哈顿距离、欧式距离、切比雪夫距离的通式)等等
停止条件:
迭代到足够次数
聚类中心不再变换
K值选择:
根据需要确定
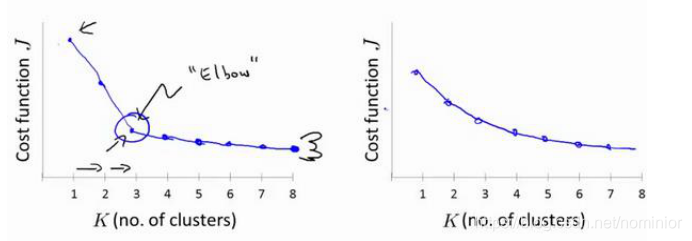
计算各类的损失函数(到聚类中心的距离和),如果如左图所示有一个明显的转折点,选择转折点数为聚类个数k,若为右图,无明显合适分类数
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/958306
推荐阅读
相关标签

