
热门标签
热门文章
- 1HEIC格式转换,码住这三个方法!
- 2软件测试基础知识_软件测试入门知识
- 3API网关-Apisix路由配置教程(数据编辑器方式)_apisix 端口
- 4全球IT界大佬权势排行:盖茨榜首马云第六_it界大佬简介
- 5springboot项目jar包加密_springboot项目 打包加密
- 640个适合前端初学者练手的基础案例(HTML&CSS)_前端案例
- 7数据结构之B树_数扰结构 b树
- 8LLM(八)| Gemini语言能力深度观察_bbh测评集
- 9Android Framework学习笔记(十)Content Provider启动过程_android content provider
- 1035岁的软件测试工程师何去何从?“我“的测试之路如何走_软件测试35岁何去何从
当前位置: article > 正文
Python GCN代码实战,图卷积神经网络代码模板,GCN代码框架,直接套用_图卷积python
作者:天景科技苑 | 2024-08-04 18:17:19
赞
踩
图卷积python
1.GCN简介
GCN(Graph Convolutional Network)是一种用于图数据的深度学习模型。它是针对图结构数据而设计的神经网络结构,能够学习节点之间的关系和图的全局特性。GCN通过在图数据上进行卷积操作,将节点的特征进行传播和聚合,从而实现节点之间的信息交互和特征学习。
GCN具有很强的适用性,可以用于推荐系统、社交网络分析、生物信息学、化学分子分析等领域。其优点包括对节点之间的关系进行建模、适用于不定长的图数据、处理稀疏图数据等。GCN已经在学术界和工业界取得了一定的成功,并且在图神经网络领域有着广泛的应用前景。
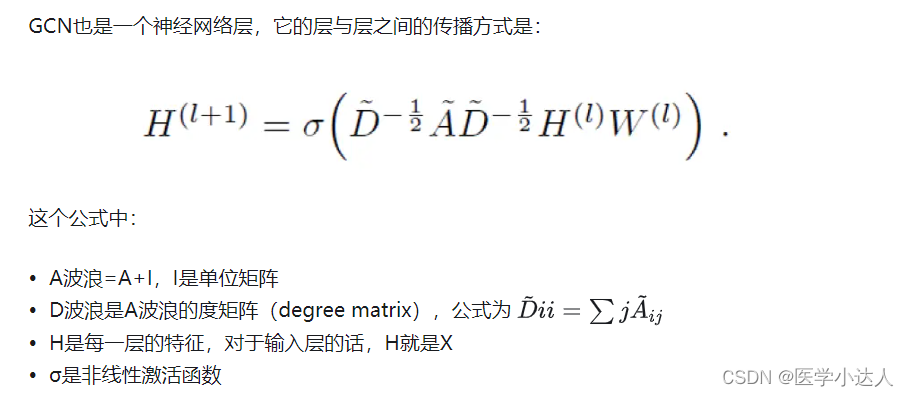
2.代码实战
版本一
这里分别定义了模型的卷积层GraphConvolutionLayer类和模型的主体GCN类,模型的卷积层就是上述公式,计算一层的特征表示,就是利用度矩阵、邻接矩阵以及特征矩阵进行信息传递,H(l)在最开始的时候就是原始的特征矩阵。
这里计算的时候把adj就是度矩阵、单位矩阵、邻接矩阵处理好之后的矩阵,都叫邻接矩阵;
- import torch
- import torch.nn as nn
- import torch.optim as optim
- import torch.nn.functional as F
-
- class GraphConvolutionLayer(nn.Module):
- def __init__(self, input_dim, output_dim):
- super(GraphConvolutionLayer, self).__init__()
- self.linear = nn.Linear(input_dim, output_dim)
-
- def forward(self, x, adj_matrix):
- x = torch.matmul(adj_matrix, x)
- x = self.linear(x)
- return F.relu(x)
-
- class GCN(nn.Module):
- def __init__(self, input_dim, hidden_dim, output_dim):
- super(GCN, self).__init__()
- self.gc1 = GraphConvolutionLayer(input_dim, hidden_dim)
- self.gc2 = GraphConvolutionLayer(hidden_dim, output_dim)
-
- def forward(self, x, adj_matrix):
- x = self.gc1(x, adj_matrix)
- x = self.gc2(x, adj_matrix)
- return x
-
- # 模拟数据
- adj_matrix = torch.tensor([[0, 1, 0], [1, 0, 1], [0, 1, 0]], dtype=torch.float32)
- features = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float32)
- labels = torch.tensor([[0.1], [0.2], [0.3]], dtype=torch.float32)
-
- # 初始化模型
- model = GCN(input_dim=2, hidden_dim=16, output_dim=1)
-
- # 定义损失函数和优化器
- criterion = nn.MSELoss()
- optimizer = optim.Adam(model.parameters(), lr=0.01)
-
- # 训练模型
- for epoch in range(100):
- optimizer.zero_grad()
- output = model(features, adj_matrix)
- loss = criterion(output, labels)
- loss.backward()
- optimizer.step()
-
- if (epoch+1) % 10 == 0:
- print(f'Epoch [{epoch+1}/100], Loss: {loss.item()}')
-
版本二
这里没有单独定义图卷积类,都放到GCN类里了,其实就是邻接矩阵adj和特征矩阵X的组合计算,然后经过一层线性层,再经过激活函数就是这一层的特征表示
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
-
- class GCN(nn.Module):
- def __init__(self, input_dim, hidden_dim, output_dim):
- super(GCN, self).__init__()
- self.fc1 = nn.Linear(input_dim, hidden_dim)
- self.fc2 = nn.Linear(hidden_dim, output_dim)
-
- def forward(self, x, adj):
- x = F.relu(self.fc1(torch.mm(adj, x)))
- x = self.fc2(torch.mm(adj, x))
- return x
-
- # 示例数据和邻接矩阵
- x = torch.randn(5, 10) # 特征矩阵,5个节点,每个节点有10个特征
- adj = torch.randn(5, 5) # 邻接矩阵
-
- model = GCN(input_dim=10, hidden_dim=16, output_dim=2) # 创建GCN模型
- optimizer = optim.Adam(model.parameters(), lr=0.01) # 选择优化器
- criterion = nn.CrossEntropyLoss() # 损失函数采用交叉熵
-
- # 训练模型
- for epoch in range(100):
- optimizer.zero_grad()
- output = model(x, adj)
-
- # 假设这里有标签数据y
- y = torch.LongTensor([0, 1, 0, 1, 0]) # 5个节点的标签
-
- loss = criterion(output, y)
- loss.backward()
- optimizer.step()
-
- # 计算训练集和验证集准确率和F1值
- output = model(x, adj)
- predictions = output.argmax(dim=1)
- correct = (predictions == y).sum().item()
- accuracy = correct / len(y)
-
- precision = torch.true_divide(torch.sum(predictions * y), torch.sum(predictions))
- recall = torch.true_divide(torch.sum(predictions * y), torch.sum(y))
- f1 = 2 * (precision * recall) / (precision + recall)
-
- print("训练集准确率:", accuracy)
- print("训练集F1值:", f1.item())
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/928982
推荐阅读
相关标签

