
- 1用户画像原理、方法_根据聚类结果对不同类别的用户画像,并且分析不同群体用户的特征。(用户画像定义:
- 2ZooX首发双向电动无人车,会成为自动驾驶出行的主流吗?
- 3独立开发者用微信小程序赚钱_微信小程序收益 csdn
- 4Python 列表 sort()函数使用详解_sort函数python_python list sort
- 5HW面试经验分享 | 某服蓝队初级_微步在线hw面试
- 6GIT删除本地分支和远程分支_git 删除远程分支为啥要叫加:
- 7用Tkinter写的聊天室的输入中文的问题_tkinter无法切换中文输入法
- 8国密SSL证书提升网络安全
- 9爬取百度搜索结果_爬虫爬取百度搜索结果
- 10EXPLAIN sql优化方法(3)DERIVED
基于Negative Sampling的模型_skip-gram noise contrastive estimation
赞
踩
本篇介绍基于 Negative Sampling 的 CBOW和 Skip-gram模型。Negative Sampling(简称为 NEG)是 NCE(Noise Contrastive Estimation)的一个简化版本,目的是用来提高训练速度并改善所得词向量的质量。与 Hierarchical Softmax 相比,NEG 不再使用(复杂的)Huffman树,而是利用(相对简单的)随机负采样,能大幅度提高性能,因而可作为 Hierarchical Softmax 的一种替代。

1. CBOW模型
在 CBOW 模型中,已知词的上下文
,需要预测
,因此,对于给定的
,词
就是一个正样本,其它词就是负样本。负样本那么多,该如何选取呢?
假定现在已经选好了一个关于的负样本子集
。且对
,定义
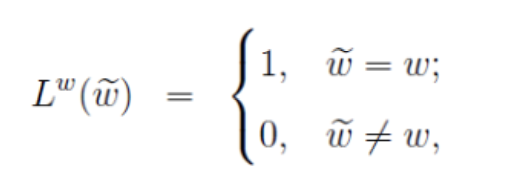
此公式定义了词的标签,即正样本的标签为 1,负样本的标签为 0。
对于一个给定的正样本,我们希望最大化。
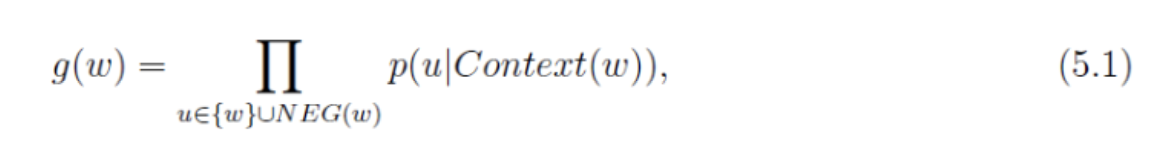
其中
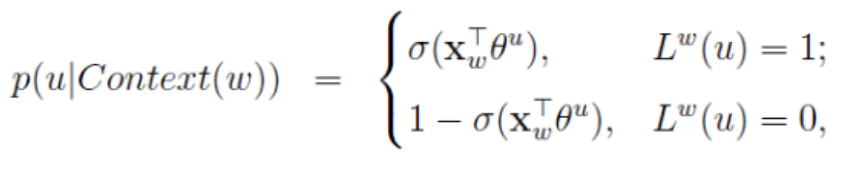
或者写作整体表达式
![]()
这里仍任然表示中
各词的词向量之和,而
表示词
对应的一个辅助向量,为待训练参数。
为什么要最大化,让我们先来看看
的表达式,将公式(5.2)代入(5.1)可得:
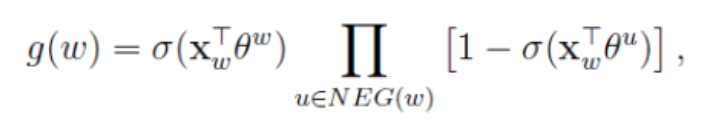

给定一个词,怎样生成
呢?
词典中的词在语料
中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。这就是我们对采样过程的一个大致要求,本质上就是一个带权采样的问题。
下面先用一段通俗的描述来帮助读者理解带权采样的机理:
设词典中的每一个词
对应一个线段
,长度为
这里的counter(w)表示一个词在语料中出现的次数(分母中的求和项用来做归一化)。现在将这些线段首尾相连拼接在一起,形成一个长度为1的单位线段.如果随机地往这个单位线段上打点,则其中长度越长的线段(对应高频词)被打中的概率就越大。(例如有4个词,出现的次数是 1 2 2 5,每个词出现归一化次数是0.1 0.2 0.2 0.5)
接下来谈谈 word2vec 中的具体做法:记,
,这里
表示词典中的第j个词,


