
热门标签
热门文章
- 1在MySQL登录时出现Access denied for user ‘root‘@‘localhost‘ (using password YES) 拒绝访问问题解决_mysql显示access denied for user
- 2数据库中的序列是什么?具体概念?_数据库序列是什么
- 3kubelet配置cni插件_第四步:树莓派Kubernetes集群安装
- 4Qt 状态栏QStatusBar_qt statusbar 布局
- 5转载:关于 Token,你应该知道的十件事
- 64.1UiPathExcel读取操作_uipath excel
- 7【数据结构】链表篇
- 8最大子段和问题动态规划解法和分治策略解法深度分析_写出用动态规划算法求解序列a=(-2.15,-5,13,-8. 5)的最大字段和的过程
- 9yum和apt-get用法及区别_apt-get 和yum
- 10当Swagger遇上YApi,瞬间高大上了!_新城主管点333oo
当前位置: article > 正文
python爬虫------王者荣耀英雄及技能爬取并保存信息到excel_腾讯游戏爬虫
作者:在线问答5 | 2024-08-14 22:24:41
赞
踩
腾讯游戏爬虫
目录
前言
这里我们不用selenium模拟人进行爬取数据,直接用requests模块获取相关信息。
整体思路:
1、获取王者荣耀官网所有英雄所在页面的网页的源代码
2、获取王者荣耀各个英雄的具体网址
3、提取其中的数据
4、把数据保存到excel中
以下是本篇文章正文内容
一、准备工作
- import requests
- import re
- import pandas as pd
-
- base_url = 'https://pvp.qq.com/web201605/herolist.shtml'
- headers = {
- 'referer': 'https://pvp.qq.com/',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
- }
首先导入requests、re、pandas模块,谷歌浏览器搜索王者荣耀官网,找到英雄资料并将网址,头信息中的referer、user-agent写入程序中。
二、具体步骤
1.获取王者荣耀官网所有英雄所在页面的网页的源代码
代码如下:
- base_url = 'https://pvp.qq.com/web201605/herolist.shtml'
- headers = {
- 'referer': 'https://pvp.qq.com/',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
- }
- response = requests.get(base_url, headers=headers)
- response.encoding = 'gbk'
- r = response.text
- # print(r)输出的是网页的全部源代码
没有response.encoding = 'gbk'会导致输出结果存在乱码。
2.获取王者荣耀各个英雄的具体网址
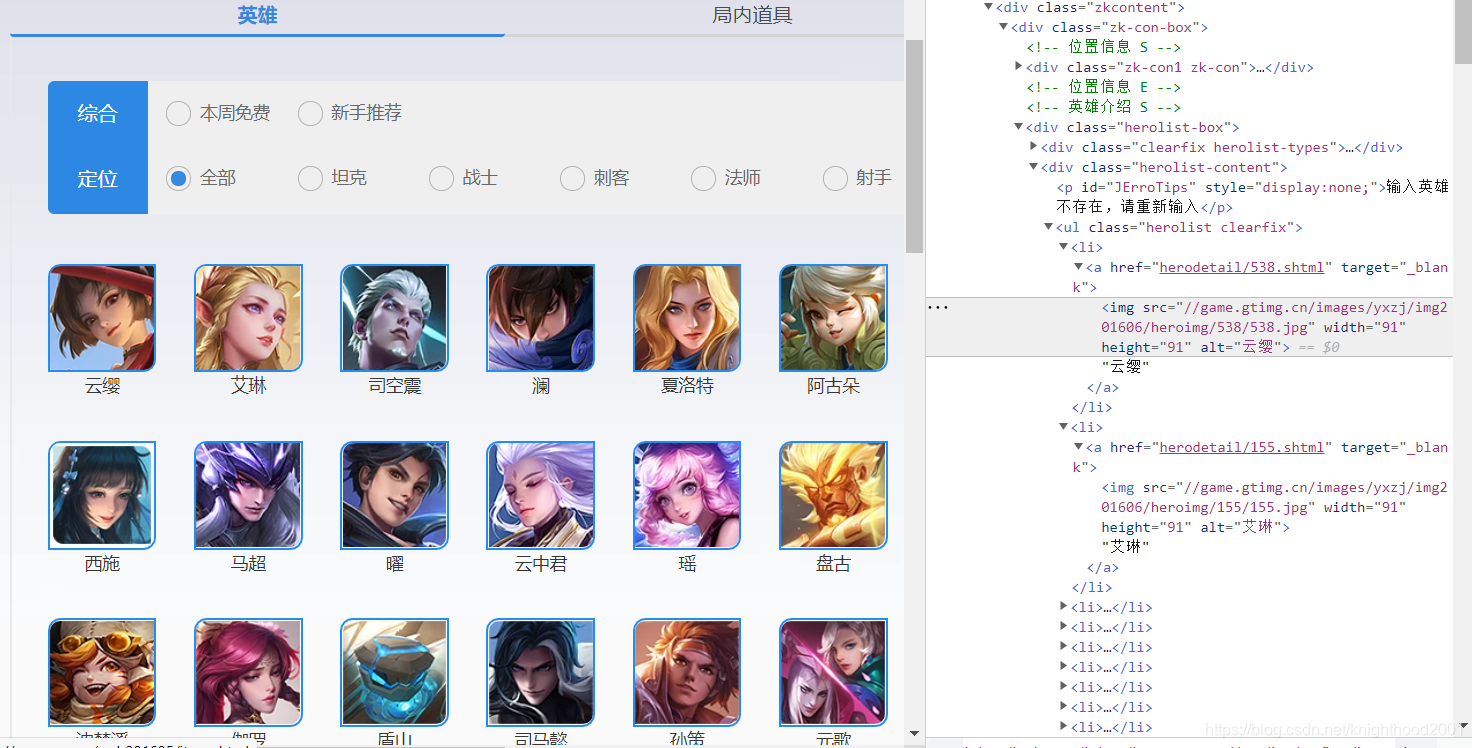
上图右边代码放大如下: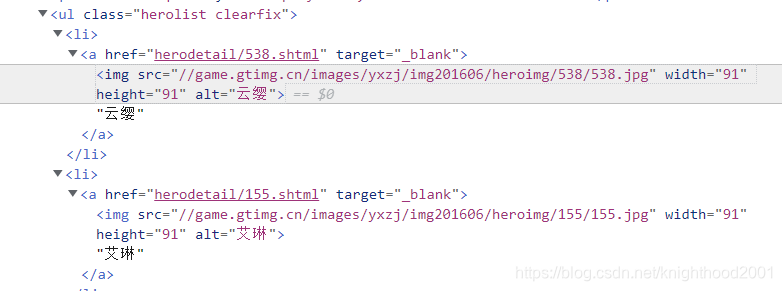
由图中我们观察到 href="herodetail/155.shtml"中的herodetail/155.shtml即为个个英雄的相关网址,但是经过观察,其中的数字没有啥规律,因此我们使用re正则表达式取出数字,并保存在hero_xuhao_list中,然后利用for循环,构建每个英雄的网址,代码如下:
- # 由于英雄的网址为无序,故使用re
- wangzhi = re.compile(r'<a href="herodetail/(\d*).shtml" target="_blank"')
- hero_xuhao_list = re.findall(wangzhi, r)
- # print(hero_xuhao_list)
- df = []
- # 标题栏
- columns = ['英雄', '被动', '技能1', '技能2', '技能3', '技能4']
- for id in hero_xuhao_list:
- detail_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(id)
- # print(detail_url)
- response1 = requests.get(detail_url, headers=headers)
- response1.encoding = 'gbk'
- # print(response1.text) 获得具体网址的全部源代码
response.textd的部分内容如下
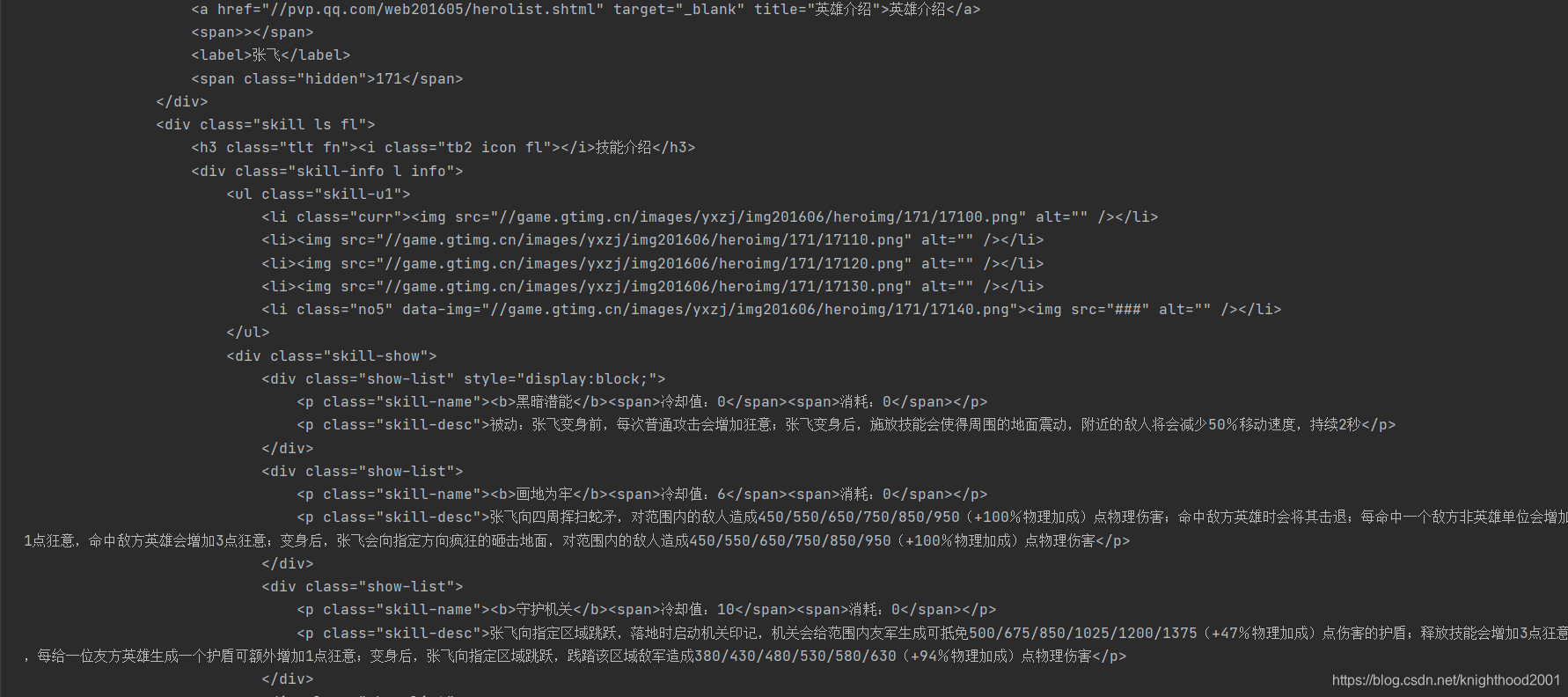
可以看到有英雄和技能的文字出现,接下来只需要用re匹配出相应内容即可
3.提取其中的数据
由于存在着缩减,我将2中的for循环内容也截取出来了,便于理解层次。
- for id in hero_xuhao_list:
- detail_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(id)
- # print(detail_url)
- response1 = requests.get(detail_url, headers=headers)
- response1.encoding = 'gbk'
- # print(response1.text) # 获得具体网址的全部源代码
- names = re.compile('<label>(.*?)</label>')
- name = names.findall(response1.text)[0]
- # 没有这个[0],会使得excel中的数据是['云中君'],即中文名外面还有引号和[]
- skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
- skill = skills.findall(response1.text)
- # print(skill)
- beidong = skill[0]
- jineng1 = skill[1]
- jineng2 = skill[2]
- jineng3 = skill[3]
- jineng4 = skill[4]
- b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])

用re提取的数据主要有英雄名字、一技能、二技能、三技能、四技能
对于名字,需要在后面加个[0],否则最后的excel文件中英雄名字列中全是列表形式的输出,
如['张飞']
![]()
如上图,有些英雄有四个技能,有些只有三个技能,按照以上方法书写,没有四技能的在excel四技能列中为空,正确。
4.把数据保存到excel中
- df = []
- # 标题栏
- columns = ['英雄', '被动', '技能1', '技能2', '技能3', '技能4']
- for id in hero_xuhao_list:
- detail_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(id)
- # print(detail_url)
- response1 = requests.get(detail_url, headers=headers)
- response1.encoding = 'gbk'
- # print(response1.text) # 获得具体网址的全部源代码
- names = re.compile('<label>(.*?)</label>')
- name = names.findall(response1.text)[0]
- # 没有这个[0],会使得excel中的数据是['云中君'],即中文名外面还有引号和[]
- skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
- skill = skills.findall(response1.text)
- # print(skill)
- beidong = skill[0]
- # print(beidong)
- jineng1 = skill[1]
- jineng2 = skill[2]
- jineng3 = skill[3]
- jineng4 = skill[4]
- b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])
-
- d = pd.DataFrame(df, columns=columns)
- # index=False表示输出不显示索引值
- d.to_excel("王者荣耀英雄与技能.xlsx", index=False)
为了连贯,我将2,3点的内容也放了进来。
存储数据到excel主要涉及到以下几行:
df = [] # 标题栏 columns = ['英雄', '被动', '技能1', '技能2', '技能3', '技能4']
d = pd.DataFrame(df, columns=columns)
# index=False表示输出不显示索引值
d.to_excel("王者荣耀英雄与技能.xlsx", index=False)
其中dataframe是二维数组。最后数据就存到excel中了。
总结
以下是源代码:
- import requests
- import re
- import pandas as pd
-
- base_url = 'https://pvp.qq.com/web201605/herolist.shtml'
- headers = {
- 'referer': 'https://pvp.qq.com/',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
- }
- response = requests.get(base_url, headers=headers)
- response.encoding = 'gbk'
- r = response.text
- # print(response.text)# 输出的是网页的全部源代码
-
- # 由于英雄的网址为无序,故使用re
- wangzhi = re.compile(r'<a href="herodetail/(\d*).shtml" target="_blank"')
- hero_xuhao_list = re.findall(wangzhi, r)
- # print(hero_xuhao_list)
- df = []
- # 标题栏
- columns = ['英雄', '被动', '技能1', '技能2', '技能3', '技能4']
- for id in hero_xuhao_list:
- detail_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(id)
- # print(detail_url)
- response1 = requests.get(detail_url, headers=headers)
- response1.encoding = 'gbk'
- # print(response1.text) # 获得具体网址的全部源代码
- names = re.compile('<label>(.*?)</label>')
- name = names.findall(response1.text)[0]
- # 没有这个[0],会使得excel中的数据是['云中君'],即中文名外面还有引号和[]
- skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
- skill = skills.findall(response1.text)
- # print(skill)
- beidong = skill[0]
- # print(beidong)
- jineng1 = skill[1]
- jineng2 = skill[2]
- jineng3 = skill[3]
- jineng4 = skill[4]
- b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])
-
- d = pd.DataFrame(df, columns=columns)
- # index=False表示输出不显示索引值
- d.to_excel("王者荣耀英雄与技能.xlsx", index=False)
-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/980897
推荐阅读
相关标签

