
- 1【ARMv8/v9 异常模型入门及渐进4 - ARM64 异常概念/异常处理流程/异常向量/汇编代码】_arm 异常serror
- 2消息中间件——RabbitMQ(四)命令行与管控台的基本操作!_rabbitmq 控制台
- 3Mybatis集成ehcache+redis_mybatis-ehcache-redis
- 4离线安装 k8s 集群 kubeadmin方式_kubeadmin命令
- 5基于Spring Cloud项目实战_springcloud 实战
- 6利用Lora调整和部署 LLM_lora llm
- 7北航OO第四单元总结
- 823.10 Django 事务的使用
- 9人工智能实验:动物识别系统(C++代码实现)
- 10display变量 Linux,linux DISPLAY变量
什么是大模型?一文读懂LLM大模型的基本概念(LLM入门)
赞
踩
大模型是指具有大规模参数和复杂计算结构的机器学习模型。本文从大模型的基本概念出发,对大模型领域容易混淆的相关概念进行区分,并就大模型的发展历程、特点和分类、泛化与微调进行了详细解读,供大家在了解大模型基本知识的过程中起到一定参考作用。
1. 大模型的定义
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
那么,大模型和小模型有什么区别?
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
2. 大模型相关概念区分:
大模型(Large Model,也称基础模型,即Foundation Model) ,是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
大语言模型(Large Language Model) :通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer):GPT 和ChatGPT都是基于Transformer架构的语言模型,但它们在设计和应用上存在区别:GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
ChatGPT:ChatGPT则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
3. 大模型的发展历程
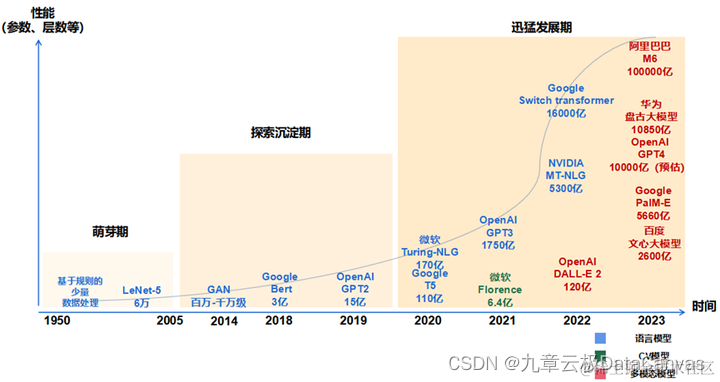
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/949594
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

