
热门标签
热门文章
- 1云计算课堂笔记和作业
- 2mysql笔记:14. 权限管理_mysql权限的分类 mysql权限的层级
- 3程序员吐槽:前外包同事能力不行,却面过了头条,只因为会刷题_毫无编程能力的同事
- 4学习笔记:第一个Flutter web程序_getstringutfchars amap
- 5全方位大模型教程:从基础入门到实战应用
- 6MobaXterm 使用教程_mobaxterm 教程
- 7Intellij IDEA免费版方法(1)_idea官网免费版
- 8【论文源码实战】轻量化MobileSAM,分割一切大模型出现,模型缩小60倍,速度提高40倍
- 91024_1024最新网址
- 10filebeat+ELK+kafka 架构体系 运行原理_elk kafka filebeat
当前位置: article > 正文
AI关键模型之Transformer_transformers ai
作者:在线问答5 | 2024-08-04 04:46:44
赞
踩
transformers ai
Transformer模型是近年来自然语言处理(NLP)领域最重要的创新之一,它摆脱了传统循环神经网络(RNN)和卷积神经网络(CNN)的局限性,引入了注意力机制,在机器翻译、文本生成、对话系统等任务上取得了突破性进展。
1. 模型结构
Transformer模型主要由两部分组成:编码器(Encoder)和解码器(Decoder)。每个编码器和解码器都包含多个相同的层堆叠而成,这些层主要由自注意力(Self-Attention)机制和前馈神经网络(Feed Forward Neural Network)构成。
- 编码器(Encoder):编码器负责将输入序列转换为一个高维向量表示。它包含多个编码器层,每个编码器层由自注意力机制、残差连接、层归一化(Layer Normalization)和前馈神经网络组成。
- 解码器(Decoder):解码器将编码器的输出向量表示转换为目标序列。与编码器类似,解码器也包含多个相同的层,但除了自注意力机制和前馈神经网络外,解码器还包含一个额外的编码器-解码器注意力(Encoder-Decoder Attention)机制,用于将编码器的输出与解码器的当前位置进行关联。
2. 注意力机制
- 自注意力(Self-Attention):Transformer模型的核心是自注意力机制,它允许模型在处理序列中的每个单词时,都能够关注到序列中的其他单词。这种机制使得模型能够捕捉到序列中的长距离依赖关系,并提高了模型的并行计算能力。
- 多头注意力(Multi-Head Attention):为了进一步增强模型的表示能力,Transformer使用了多头注意力机制。它将输入序列分成多个子序列,并分别对每个子序列进行自注意力计算,然后将结果拼接起来。这种机制使得模型能够学习到输入序列中不同位置之间的多种关联性。
3. 位置编码
由于Transformer模型本身不包含循环或卷积结构,因此无法直接捕获序列中的位置信息。为了解决这个问题,Transformer在输入序列中加入了位置编码(Positional Encoding),使得模型能够区分不同位置的单词。位置编码可以通过正弦和余弦函数计算得到,也可以通过学习得到。
4. 优缺点
- 优点:Transformer模型具有高效性、上下文感知和预训练与微调等优点。它使用自注意力机制实现了对输入序列的编码和表示学习,具有更高的并行性和计算效率。同时,它能够捕捉序列中不同位置之间的依赖关系,实现上下文感知。此外,Transformer模型通常采用预训练和微调的方式进行模型训练和应用,可以提高模型的泛化能力和准确性。
- 缺点:Transformer模型对数据要求高,通常需要大量的数据和计算资源来进行预训练和微调。此外,由于模型内部结构比较复杂,解释性较差。另外,对于较长的序列,模型的学习能力仍然有限。
5. 前沿研究
随着Transformer模型在各个领域的广泛应用,其研究也进入了一个新的阶段。目前的前沿研究主要集中在如何进一步提高模型的性能、降低计算成本以及扩展模型的应用范围等方面。例如,研究者们正在探索使用更高效的注意力机制、改进模型的预训练策略以及将Transformer模型应用于跨领域任务等。
6. 性能优势
- 处理并行性:与传统循环网络不同,Transformer允许并行处理输入序列,显著提高了训练和推理的速度。
- 长距离依赖:自注意力机制使得Transformer能够直接计算序列中各个位置之间的关系,从而有效捕捉长距离依赖关系。
- 模型泛化能力:由于其独特的结构设计,Transformer具有很好的泛化能力,适用于多种不同的NLP任务和数据集。
7. 模型缺点
- 计算资源要求高:由于模型结构和运算的复杂性,Transformer需要较多的计算资源,尤其是在处理大规模数据时。
- 对数据量的需求:为了达到良好的表现,Transformer需要大量的训练数据来充分训练其大量的参数
8. Transformer中的Q、K、V
- Q(Query):查询向量。在自注意力机制中,Q用于表示当前位置对序列中其他位置的查询需求。换句话说,它代表了当前位置想要关注序列中哪些部分的信息。
- K(Key):关键向量。K用于表示序列中每个位置可以被其他位置查询到的信息。在自注意力机制中,K与Q进行相似度计算,以确定当前位置应该关注序列中的哪些部分。
- V(Value):数值向量。V包含了序列中每个位置的实际信息,这些信息将根据Q和K的相似度计算结果进行加权求和,得到最终的输出表示。
- Q、K、V是通过将输入序列(通常是词嵌入表示)进行线性变换得到的。具体来说,输入序列X会分别与三个可训练的参数矩阵(通常表示为Wq、Wk、Wv)进行相乘,得到Q、K、V三个矩阵。
- 线性变换:输入序列X经过线性变换得到Q、K、V三个矩阵。
- 相似度计算:计算Q和K的点积(或内积),得到一个相似度矩阵。这个矩阵中的每个元素表示了序列中两个位置之间的相似度。
- 缩放(Scale):将相似度矩阵中的每个元素除以一个缩放因子(通常为K的维度大小的平方根),以控制相似度的大小。这一步是为了防止在相似度计算时,由于K的维度较大导致内积结果过大,进而影响softmax函数的稳定性。
- Softmax归一化:对缩放后的相似度矩阵进行softmax操作,得到每个查询词与其他词的权重分布。这个权重分布表示了当前位置对序列中其他位置的关注程度。
- 加权求和:将权重矩阵与V矩阵相乘,得到每个查询词的表示向量。这个表示向量是序列中所有位置信息的加权和,其中权重由Q和K的相似度决定。
- 连接表示:将每个查询词的表示向量连接起来,得到最终的表示矩阵。这个表示矩阵包含了序列中所有位置的信息,并且每个位置的信息都根据其他位置的信息进行了加权调整。
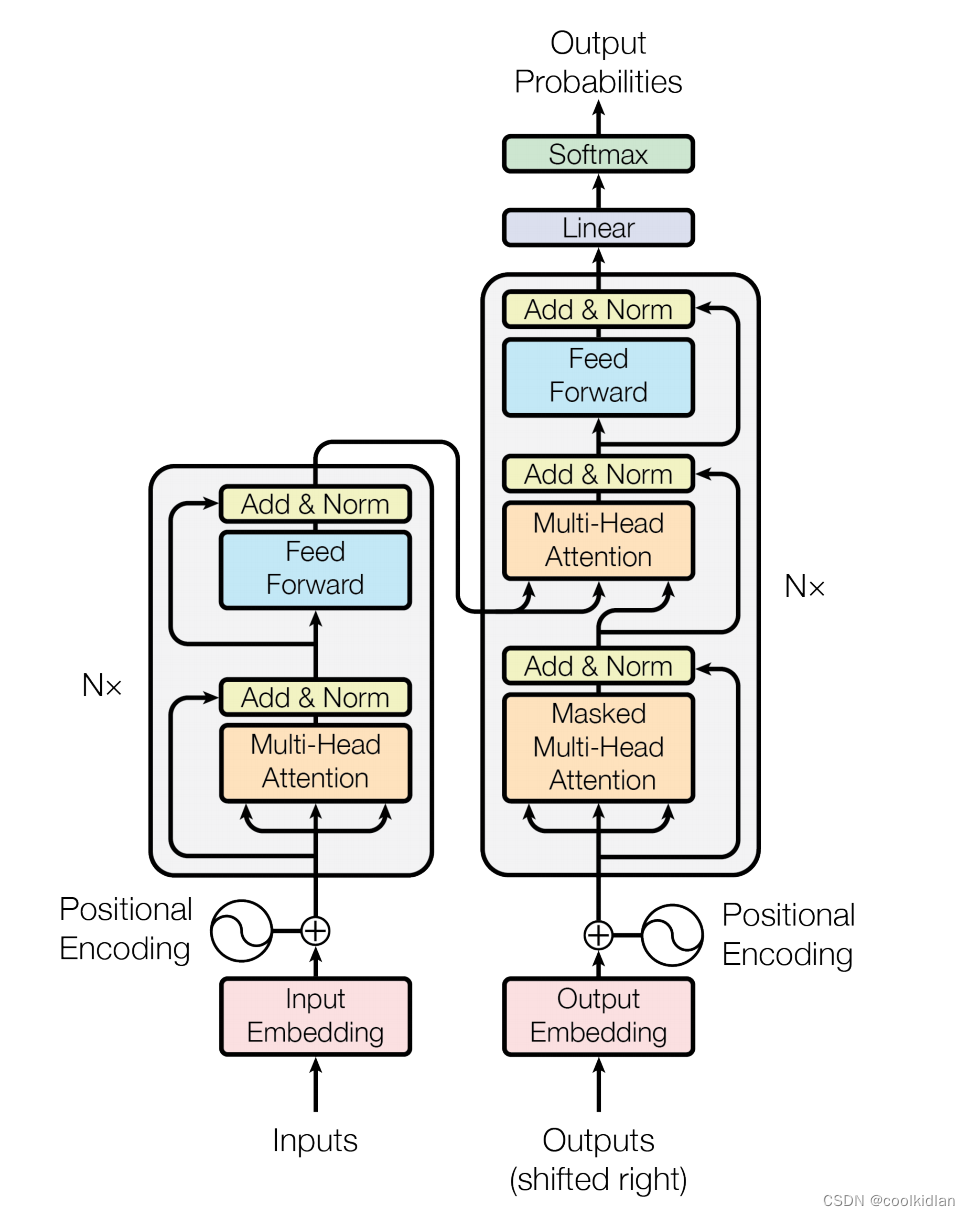
图1 Transformer网络结构图
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/926263
推荐阅读
相关标签

